






自定义语义分割数据集(划分训练集与验证集)、并且将一个文件夹下的所有图片的名字存到txt文件
我们可以借助Pytorch从文件夹中读取数据集,十分方便,但是Pytorch中没有提供数据集划分的操作,需要手动将原始的数据集划分为训练集、验证集和测试集,废话不多说, 这里写了一个工具类,帮助大家将数据集自动划分为训练集、验证集和测试集,还可以指定比例,代码如下。
1.划分训练集、验证集与测试集
工具类
import os
import random
import shutil
from shutil import copy2
def data_set_split(src_data_folder, target_data_folder, train_scale=0.8, val_scale=0.1, test_scale=0.1):
'''
读取源数据文件夹,生成划分好的文件夹,分为trian、val、test三个文件夹进行
:param src_data_folder: 源文件夹 E:/biye/gogogo/note_book/torch_note/data/utils_test/data_split/src_data
:param target_data_folder: 目标文件夹 E:/biye/gogogo/note_book/torch_note/data/utils_test/data_split/target_data
:param train_scale: 训练集比例
:param val_scale: 验证集比例
:param test_scale: 测试集比例
:return:
'''
print("开始数据集划分")
class_names = os.listdir(src_data_folder)
# 在目标目录下创建文件夹
split_names = ['train', 'val', 'test']
for split_name in split_names:
split_path = os.path.join(target_data_folder, split_name)
if os.path.isdir(split_path):
pass
else:
os.mkdir(split_path)
# 然后在split_path的目录下创建类别文件夹
for class_name in class_names:
class_split_path = os.path.join(split_path, class_name)
if os.path.isdir(class_split_path):
pass
else:
os.mkdir(class_split_path)
# 按照比例划分数据集,并进行数据图片的复制
# 首先进行分类遍历
for class_name in class_names:
current_class_data_path = os.path.join(src_data_folder, class_name)
current_all_data = os.listdir(current_class_data_path)
current_data_length = len(current_all_data)
current_data_index_list = list(range(current_data_length))
random.shuffle(current_data_index_list)
train_folder = os.path.join(os.path.join(target_data_folder, 'train'), class_name)
val_folder = os.path.join(os.path.join(target_data_folder, 'val'), class_name)
test_folder = os.path.join(os.path.join(target_data_folder, 'test'), class_name)
train_stop_flag = current_data_length * train_scale
val_stop_flag = current_data_length * (train_scale + val_scale)
current_idx = 0
train_num = 0
val_num = 0
test_num = 0
for i in current_data_index_list:
src_img_path = os.path.join(current_class_data_path, current_all_data[i])
if current_idx <= train_stop_flag:
copy2(src_img_path, train_folder)
# print("{}复制到了{}".format(src_img_path, train_folder))
train_num = train_num + 1
elif (current_idx > train_stop_flag) and (current_idx <= val_stop_flag):
copy2(src_img_path, val_folder)
# print("{}复制到了{}".format(src_img_path, val_folder))
val_num = val_num + 1
else:
copy2(src_img_path, test_folder)
# print("{}复制到了{}".format(src_img_path, test_folder))
test_num = test_num + 1
current_idx = current_idx + 1
print("*********************************{}*************************************".format(class_name))
print(
"{}类按照{}:{}:{}的比例划分完成,一共{}张图片".format(class_name, train_scale, val_scale, test_scale, current_data_length))
print("训练集{}:{}张".format(train_folder, train_num))
print("验证集{}:{}张".format(val_folder, val_num))
print("测试集{}:{}张".format(test_folder, test_num))
if __name__ == '__main__':
src_data_folder = "/home/ubuntu/PycharmProjects/DataSet/workshop"
target_data_folder = "/home/ubuntu/PycharmProjects/DataSet/workshop"
data_set_split(src_data_folder, target_data_folder)
2.文件名称保存为txt
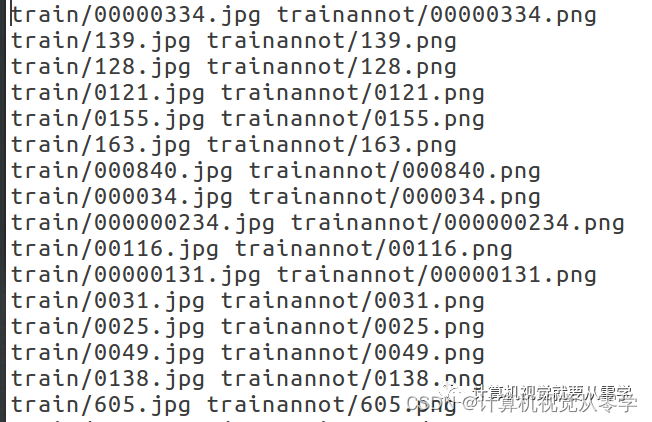
import os
img_path = '/home/ubuntu/PycharmProjects/DataSet/workshop/train/'
img_list = os.listdir(img_path)
print(img_list)
f = open('/home/ubuntu/PycharmProjects/DataSet/workshop/workshop_train_list.txt', 'w')
for img in img_list:
img = img[:-4] + '.jpg'
imgstr = 'train/'+img+' '+'trainannot/'+img[:-4]+'.png'+'\n'
print(imgstr)
f.write(imgstr)
f.close()
3.文件移动
第一张图是训练集(train),第二张图是未划分之前的原标签(mask)数据集,现在需要根据训练集中的图片,将与之对应的标签(mask)图片移动到另一个文件夹(trainannot)中
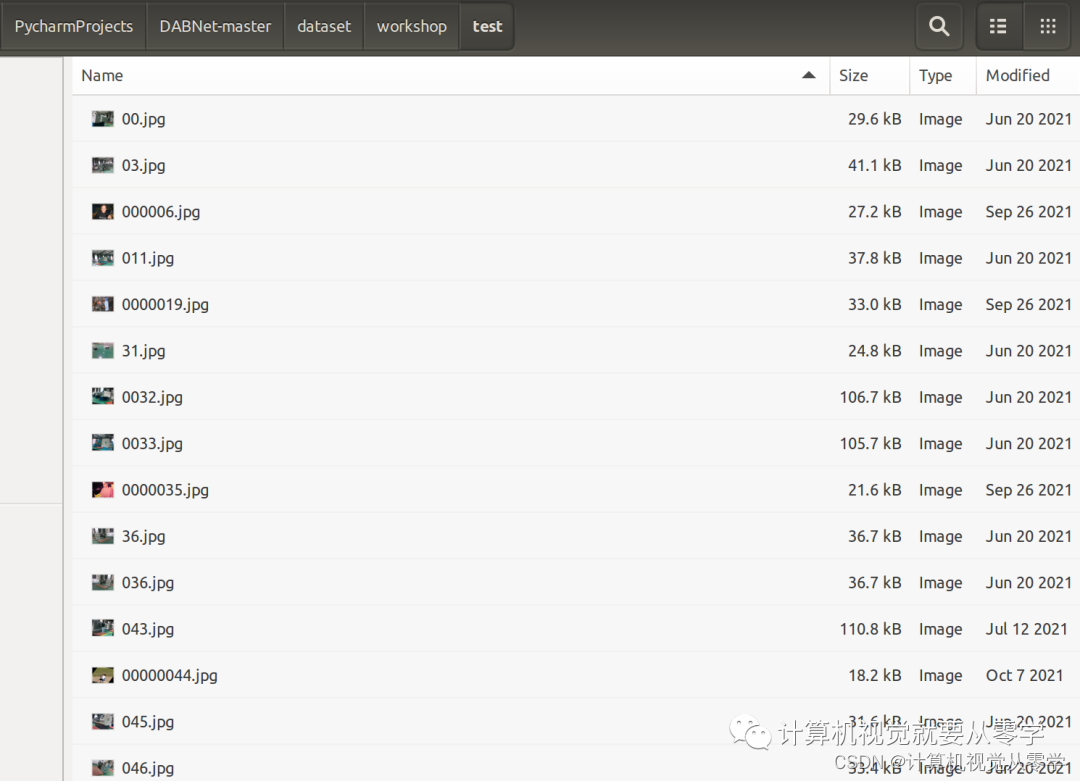
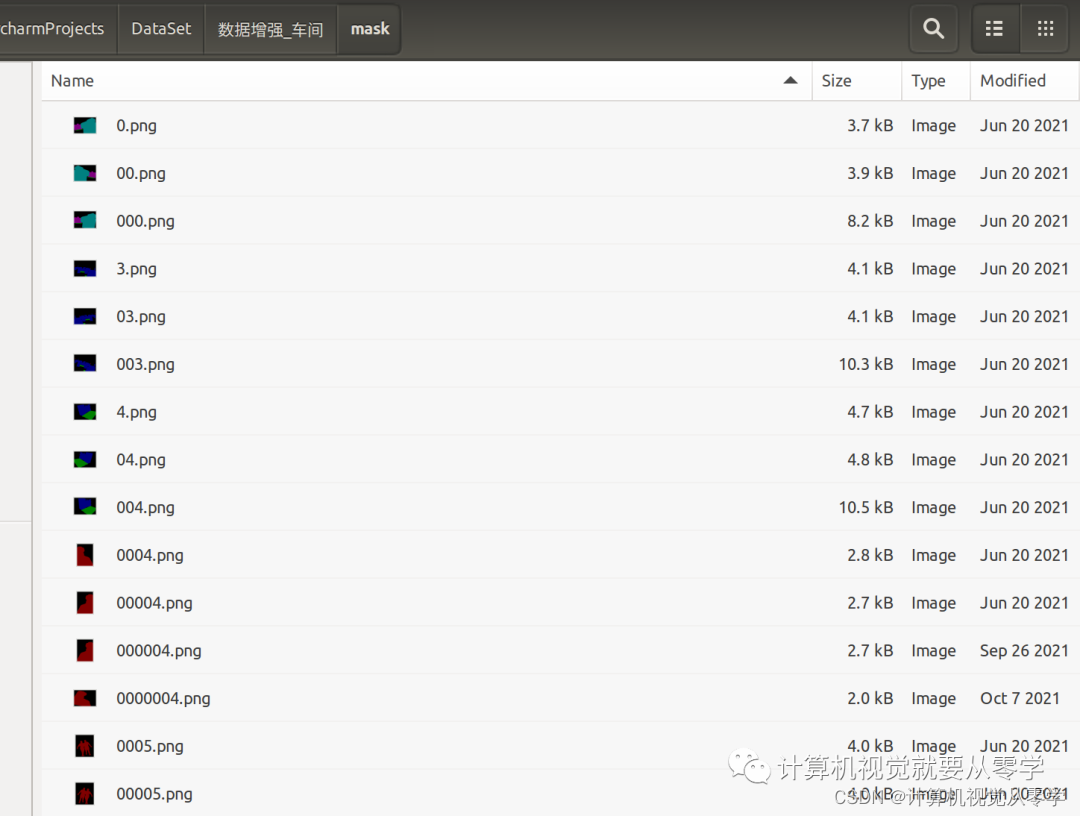
import os, random, shutil
def moveImage(fileImageDir):
pathDir = os.listdir(fileImageDir)
filenumber = len(pathDir)
rate = 0.1
picknumber = int(filenumber * rate) # 按照设定比例从文件夹中取一定数量图片
sample = random.sample(pathDir, picknumber)
print(sample)
for name in sample:
shutil.move(fileImageDir + name, tarImageDir + name)
return
def extract_name(Image_dir, write_file_name):
file_list = []
# 读取文件,并将地址、图片名和标签写到txt文件中
write_file = open(write_file_name, "w") # 打开write_file_name文件
for file in os.listdir(Image_dir):
if file.endswith(".jpg"):
name = file.split('.')[0] # 分割图像名称和后缀名
write_name = name
file_list.append(write_name)
sorted(file_list) # 将列表中所有元素随机排列
number_of_lines = len(file_list)
for current_line in range(number_of_lines):
write_file.write(file_list[current_line] + '\n')
write_file.close()
def moveLabel(fileLabelDir, write_file_name):
pathDir = os.listdir(fileLabelDir)
f = open(write_file_name, 'r')
lines = f.readlines()
for line in lines:
line = line.strip('\n') # 去除文本的换行符,否则报错
shutil.move(fileLabelDir + str(line) + '.jpg', tarLabelDir + str(line) + '.jpg')
if __name__ == '__main__':
fileImageDir = '/home/ubuntu/PycharmProjects/DataSet/workshop/img/' # 训练集图像地址
tarImageDir = '/home/ubuntu/PycharmProjects/DataSet/workshop/test/' # 测试集图像地址
Image_dir = tarImageDir
write_file_name = '/home/ubuntu/PycharmProjects/DataSet/workshop/img.txt' # 提取测试集文件名称文件存放地址
fileLabelDir = '/home/ubuntu/PycharmProjects/DataSet/workshop/mask/' # 训练集标签地址
tarLabelDir = '/home/ubuntu/PycharmProjects/DataSet/workshop/testannot/' # 测试集标签地址
moveImage(fileImageDir)
extract_name(Image_dir, write_file_name)
moveLabel(fileLabelDir, write_file_name)
4.将数据集保存为.pkl格式以及读取.pkl格式文件
import pickle
dict_data = {"name":["张三", "李四"]}
with open("dict_data.pkl", 'wb') as fo: # 将数据写入pkl文件
pickle.dump(dict_data, fo)
with open("dict_data.pkl", 'rb') as fo: # 读取pkl文件数据
dict_data = pickle.load(fo, encoding='bytes')
print(dict_data.keys()) # 测试我们读取的文件
print(dict_data)
print(dict_data["name"])
==============================
结果如下:
dict_keys(['name'])
{'name': ['张三', '李四']}
['张三', '李四']


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









