




使用RAG时,需要对文档分段后进行存储,之前的例子中,我们是将向量数据存入内存。事实上,LangChain4j集成了20中以上的向量存储方式。
LangChain4j支持的向量存储
| Embedding Store | Storing Metadata | Filtering by Metadata | Removing Embeddings |
|---|---|---|---|
| In-memory | ✅ | ✅ | ✅ |
| AlloyDB for Postgres | ✅ | ✅ | ✅ |
| Astra DB | ✅ | ||
| Azure AI Search | ✅ | ✅ | ✅ |
| Azure CosmosDB Mongo vCore | ✅ | ||
| Azure CosmosDB NoSQL | ✅ | ||
| Cassandra | ✅ | ||
| Chroma | ✅ | ✅ | ✅ |
| ClickHouse | ✅ | ✅ | ✅ |
| Cloud SQL for Postgres | ✅ | ✅ | ✅ |
| Coherence | ✅ | ✅ | ✅ |
| Couchbase | ✅ | ✅ | |
| DuckDB | ✅ | ✅ | ✅ |
| Elasticsearch | ✅ | ✅ | ✅ |
| Infinispan | ✅ | ||
| Milvus | ✅ | ✅ | ✅ |
| MongoDB Atlas | ✅ | ✅ | ✅ |
| Neo4j | ✅ | ||
| OpenSearch | ✅ | ||
| Oracle | ✅ | ✅ | ✅ |
| PGVector | ✅ | ✅ | ✅ |
| Pinecone | ✅ | ✅ | ✅ |
| Qdrant | ✅ | ✅ | ✅ |
| Redis | ✅ | ||
| Tablestore | ✅ | ✅ | ✅ |
| Vearch | ✅ | ||
| Vespa | |||
| Weaviate | ✅ | ✅ |
本例,我们将向量输入存入redis中。为此,我们需要安装redis stack服务。
redis-stack安装
redis-stack介绍
Redis Stack是Redis的扩展,它提供了一系列功能的扩展扩展,比如,全文搜索、文档数据库、时间序列数据、图形数据和矢量搜索等。
Redis Stack 是一组软件套件,它主要由三部分组成:
- Redis Stack Server,由 Redis,RedisSearch,RedisJSON,RedisGraph,RedisTimeSeries 和 RedisBloom 组成
- RedisInsight,官方提供的强大的redis客户端工具
- Redis Stack 客户端 SDK,包括Java、JavaScript、Python
通过docker安装redis-stack
我们通过docker安装redis-stack套件,首先拉取镜像:
docker pull redis/redis-stack拉取镜像后,运行容器:
docker run -d --name redis-stack -p 8001:8001 -p 6379:6379 -v /root/redisstack/data:/data/redis_data redis/redis-stack其中8001端口用于访问RedisInsight。
访问RedisInsight
访问地址:http://宿主机ip:8001
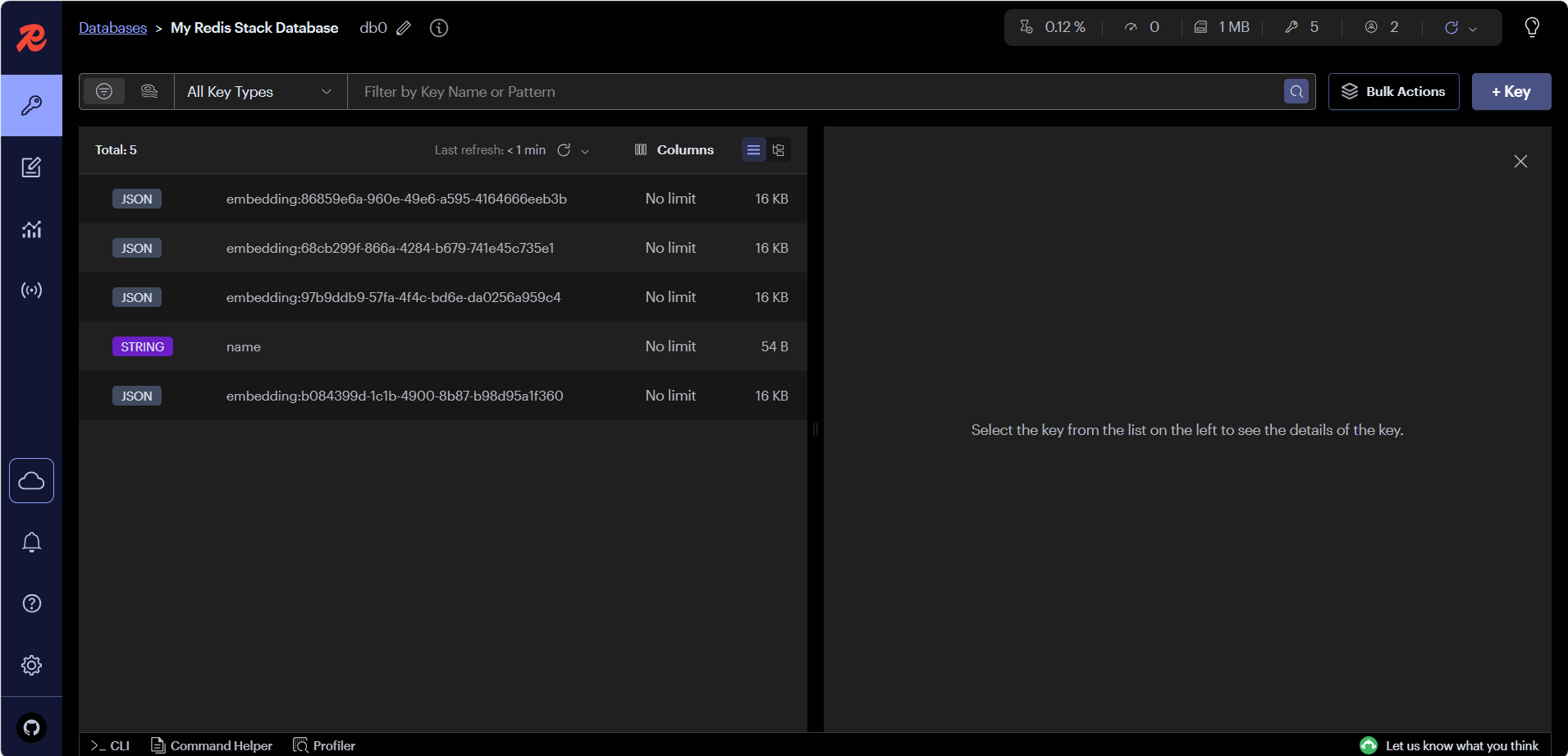
向redis-stack写入向量数据
导入jar
存储向量数据,一般要求jedis使用5.2.0及以上版本。
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-redis</artifactId>
<version>1.0.0-beta2</version>
<exclusions>
<exclusion>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.2.0</version>
</dependency>测试代码
package com.renr.langchain4jnew.app4;
import dev.langchain4j.community.store.embedding.redis.RedisEmbeddingStore;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.embedding.onnx.bgesmallzhv15.BgeSmallZhV15EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingMatch;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingStore;
import java.util.List;
public class RedisEmbeddingStoreTest {
public static void main(String[] args) {
// 创建redis向量存储对象
EmbeddingStore<TextSegment> embeddingStore = RedisEmbeddingStore.builder()
.host("localhost") // reids ip
.port(6379) // redis 端口
.indexName("mytest") // 索引名称,可以不写
// .dimension(512)
.build();
// 创建嵌入模型对象
EmbeddingModel embeddingModel = new BgeSmallZhV15EmbeddingModel();
// 将指定的数据向量化,并存入redis
TextSegment segment1 = TextSegment.from("I like football.");
Embedding embedding1 = embeddingModel.embed(segment1).content();
embeddingStore.add(embedding1, segment1);
TextSegment segment2 = TextSegment.from("The weather is good today.");
Embedding embedding2 = embeddingModel.embed(segment2).content();
embeddingStore.add(embedding2, segment2);
// 向需要比对的内容向量化
Embedding queryEmbedding = embeddingModel.embed("What is your favourite sport?").content();
// 创建搜索对象
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(2) // 指定返回的搜索结果的最大个数
.build();
// 进行相似度搜索
List<EmbeddingMatch<TextSegment>> matches = embeddingStore.search(embeddingSearchRequest).matches();
// 获取匹配的数据
EmbeddingMatch<TextSegment> embeddingMatch = matches.get(0);
// 打印计算的结果
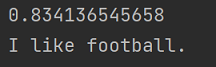
System.out.println(embeddingMatch.score());
System.out.println(embeddingMatch.embedded().text());
}
}执行结果
查看redis中数据
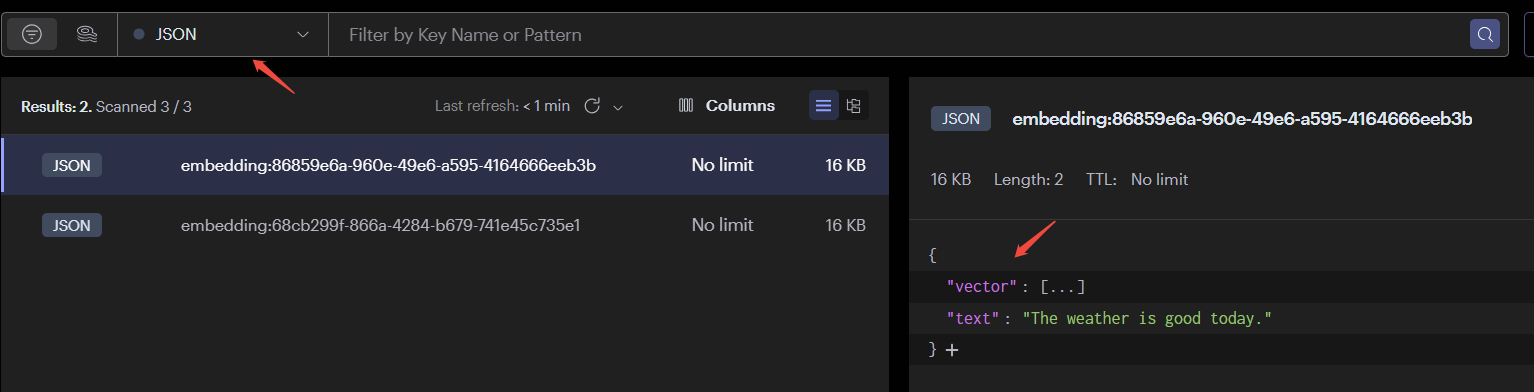
LangChain4j使用JSON格式存储向量数据,而且数据中包含原来的文档内容text和向量化后的数据vector。
通过查看源码,其中使用KNN算法(K-邻近算法)进行向量搜索。
 RAG中使用redis作为向量存储
RAG中使用redis作为向量存储
package com.renr.langchain4jnew.app5;
import com.renr.langchain4jnew.app4.NaiveRAG;
import com.renr.langchain4jnew.constant.CommonConstants;
import dev.langchain4j.community.model.zhipu.ZhipuAiChatModel;
import dev.langchain4j.community.store.embedding.redis.RedisEmbeddingStore;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentParser;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.document.parser.TextDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.embedding.onnx.bgesmallzhv15.BgeSmallZhV15EmbeddingModel;
import dev.langchain4j.rag.DefaultRetrievalAugmentor;
import dev.langchain4j.rag.RetrievalAugmentor;
import dev.langchain4j.rag.content.injector.ContentInjector;
import dev.langchain4j.rag.content.injector.DefaultContentInjector;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import java.net.URISyntaxException;
import java.net.URL;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.time.Duration;
import static java.util.Arrays.asList;
public class AdvancedRAG03_RedisStore {
public static void main(String[] args) throws URISyntaxException {
ChatLanguageModel chatModel = ZhipuAiChatModel.builder()
// 模型key
.apiKey(CommonConstants.API_KEY)
// 精确度
.temperature(0.9)
.model("GLM-4-Flash")
.maxRetries(3)
.callTimeout(Duration.ofSeconds(60))
.connectTimeout(Duration.ofSeconds(60))
.writeTimeout(Duration.ofSeconds(60))
.readTimeout(Duration.ofSeconds(60))
.logRequests(true)
.logResponses(true)
.build();
// 获取待加载的文档路径
URL fileUrl = NaiveRAG.class.getClassLoader().getResource("document/医院.txt");
Path path = Paths.get(fileUrl.toURI());
// 指定文档解析器
DocumentParser documentParser = new TextDocumentParser();
// 加载文档数据
Document document = FileSystemDocumentLoader.loadDocument(path, documentParser);
// 支持中文的嵌入模型
EmbeddingModel embeddingModel = new BgeSmallZhV15EmbeddingModel();
// 使用redis作为向量存储对象
EmbeddingStore<TextSegment> embeddingStore = RedisEmbeddingStore.builder()
.host("localhost") // reids ip
.port(6379) // redis 端口
.indexName("mytest") // 索引名称,可以不写
// .dimension(512)
.build();
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(300, 0))
// .documentSplitter(new DocumentByLineSplitter(300, 0))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(document);
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
// 每次最多检索2个最符合要求的分段
.maxResults(2)
// 指定检索时的最低相似度分数
.minScore(0.5)
.build();
ContentInjector contentInjector = DefaultContentInjector.builder()
// .promptTemplate(...) // Formatting can also be changed
.metadataKeysToInclude(asList("file_name", "index"))
.build();
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.contentRetriever(contentRetriever)
.contentInjector(contentInjector)
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(chatModel)
.retrievalAugmentor(retrievalAugmentor)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.build();
// String answer = assistant.chat("医院地址");
String answer = assistant.chat("医院职工数");
System.out.println(answer);
}
}执行后,查看redis中数据:



















 2738
2738



 到【灌水乐园】发言
到【灌水乐园】发言








