




为什么选用Redis-stack-server?
新增了ReJSON-RL,用于存储向量化后的数据,所以可以当作向量数据库
并且Redis-Stack本身也是高性能的查询内存的分布式数据库,所以不用引入新的技术

embedding是进行向量化(通常是embeddingModel来实现具体功能,也叫做嵌入式模型),向量化后就可以存入向量库,向量库可以用PostgreSQL,也可以用Redis-stack
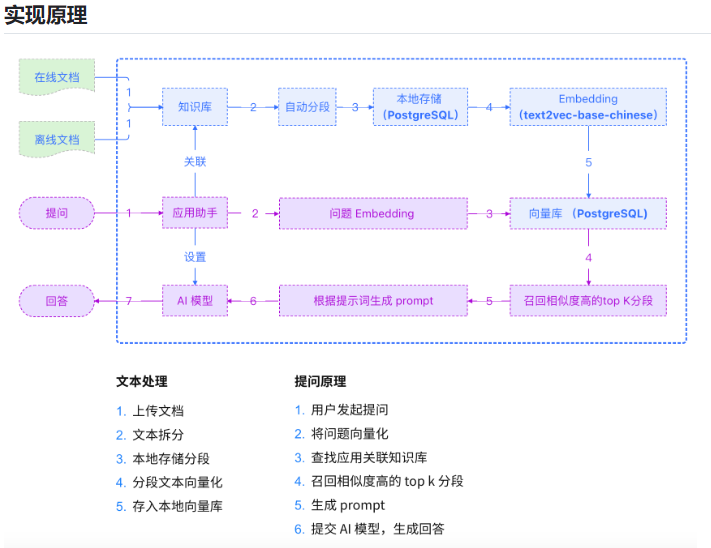
内存可以作为向量数据库,但是一重启一断电数据就没了
这了选择RedisStack作为向量数据,用来向量的存储,未来会改名成Redis8,也就是在原本的Reids的功能上增加了新的特性,本质上还是Redis
向量数据库还可以用ElaticSearch、MongoDB等
一、改pom.xml
重点:
<!--spring-ai-alibaba dashscope-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<!-- 添加 Redis 向量数据库依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>完整:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.atguigu.study</groupId>
<artifactId>SpringAIAlibaba-atguiguV1</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>SAA-11Embed2vector</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--spring-ai-alibaba dashscope-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<!-- 添加 Redis 向量数据库依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.38</version>
</dependency>
<!--hutool-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.22</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-m 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









