







1、概述
Prometheus默认将数据储存在本地的TSDB(时序数据库)中,这种设计较大地简化了Promethes的部署难度,但与此同时也存在着一些问题。
首先是数据持久化的问题,原生的TSDB对于大数据量的保存及查询支持不太友好 ,并不适用于保存长期的大量数据;另外,该数据库的可靠性也较弱,在使用过程中容易出现数据损坏等故障,且无法支持集群的架构。
为了满足这方面的需求,Prometheus提供了remote_write和remote_read的特性,支持将数据存储到远端和从远端读取数据的功能。当配置remote_write特性后,Prometheus会将采集到的指标数据通过HTTP的形式发送给适配器(Adaptor),由适配器进行数据的存入。而remote_read特性则会向适配器发起查询请求,适配器根据请求条件从第三方存储服务中获取响应的数据。
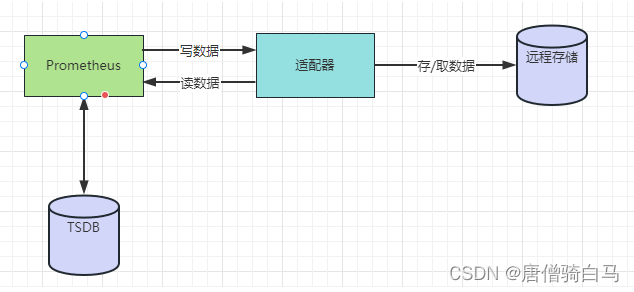
使用接口的存储方式,符合Prometheus追求简洁的设计理念,一方面可以减少与远程存储的耦合性,避免因存储问题而导致服务中断;另一方面通过将监控与数据分离,Prometheus也降低了自身设计的复杂性,能够更好地进行弹性扩展。
在Prometheus社区中,目前已经有不少远程存储的支持方案,下面列出了其中的部分方案,完整内容可参见官网。AppOptics: write
- Chronix: write
- Cortex: read and write
- CrateDB: read and write
- Elasticsearch: write
- Gnocchi: write
- Graphite: write
- InfluxDB: read and write
- Kafka: write
- OpenTSDB: write
- PostgreSQL/TimescaleDB: read and write
- Splunk: read and write
在这些解决方案中,有些只支持写入操作,不支持读取,有些则支持完整的读写操作。
在本文的示例中,我们将使用InfluxDB来做为我们远程存储的方案。
2、InfluxDB简介
InfluxDB是业界流行的一款时间序列数据库,其使用go语言开发。InfluxDB以性能突出为特点,具备高效的数据处理和存储能力,目前在监控和IOT 等领域被广泛应用。

产品具有以下特点:
- 自定义的TSM引擎,数据高速读写和压缩等功能。
- 简单、高性能的HTP查询和写入API。
- 针对时序数据,量身打造类似SQL的查询语言,轻松查询聚合数据。
- 允许对tag建索引,实现快速有效的查询。
- 通过保留策略,可有效去除过期数据
与传统关系数据库的名词对比:
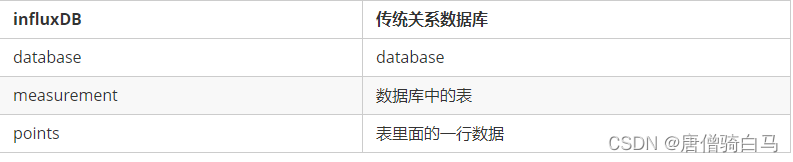
于InfluxDB的更多内容可参见官文文档:https://docs.influxdata.com/influxdb/v1.8,本文不做过多介绍。
3、安装InfluxDB
3.1 配置yum源
cat <<EOF | sudo tee /etc/yum.repos.d/influxdb.repo
[influxdb]
name = InfluxDB Repository - RHEL \$releasever
baseurl = https://repos.influxdata.com/rhel/\$releasever/\$basearch/stable
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdb.key
EOF
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









