







 文章探讨了如何解决Prometheus在大规模监控环境中的性能瓶颈和高可用问题。提出了结合远程存储实现Prometheus服务的高可用性和数据持久化,以及通过联邦模式对监控任务进行拆分,以提高监控系统的容量和可靠性。联邦模式包括功能拆分和水平拆分,主节点通过/federate接口统一管理数据。告诫在采用分级联邦时要注意网络复杂性、数据延迟和主节点的压力管理。
文章探讨了如何解决Prometheus在大规模监控环境中的性能瓶颈和高可用问题。提出了结合远程存储实现Prometheus服务的高可用性和数据持久化,以及通过联邦模式对监控任务进行拆分,以提高监控系统的容量和可靠性。联邦模式包括功能拆分和水平拆分,主节点通过/federate接口统一管理数据。告诫在采用分级联邦时要注意网络复杂性、数据延迟和主节点的压力管理。
在上篇的Prometheus远程存储方案中,我们解决了数据持久化和大数据量存储/查询的需求。但是,在大规模的监控环境中,除了存储方面的问题外,Prometheus实例在处理大量的监控任务时,也可能会成为性能瓶颈。另外还有高可用的问题,应该如何来保证监控系统的可靠性。
本篇我们将就这些问题进行探讨研究。
1、Prometheus高可用
在官方的推荐方案中,对于高可用的处理是通过部署两套Prometheus,配置同样的目标实例来实现的。在这个方案里面,两套Prometheus会获取相同的监控指标,并且触发同样的告警规则,而对于警报的去重工作则由Alertmanager来负责。
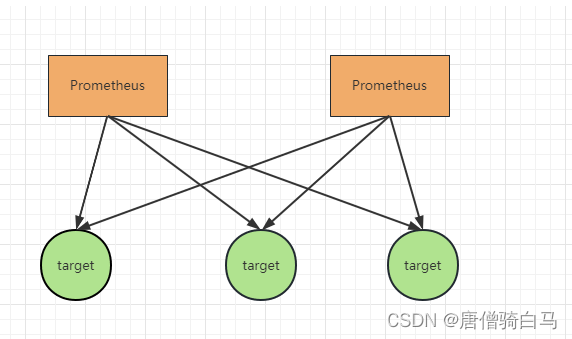
但此方案也存在着明显缺点,比如当某个Prometheus出现故障或中断时,那么该节点将会出现数据丢失的情况,并与另一个节点存在数据差异。当在该节点上进行查询操作时,就会遇到这个问题。
对此,我们可以与远程存储方案结合起来,将Prometheus的读写放到远程存储端,通过高可用 +远程存储的方式来解决上面的问题。
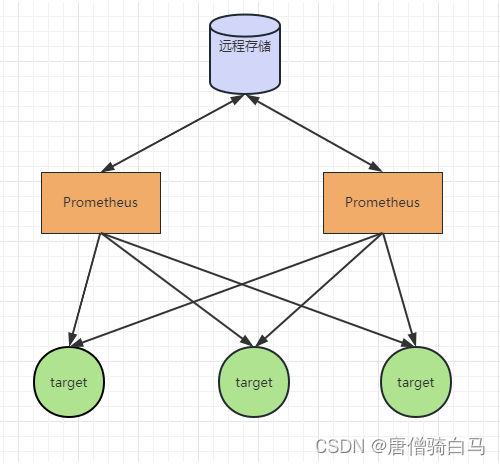
此优化方案在解决了Promthues服务可用性的基础上,同时确保了数据的持久化,当某个Promthues 节点发生宕机的情况时,由于还有另一个节点在获取数据,这样可以保证在查询时不会遇到数据丢失的问题。
该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时确保Promthues服务高可用性的场景。
2、联邦模式
在大规模的监控环境中,当单个Prometheus无法处理大量的监控采集任务时,我们可以基于联邦的模式将采集任务划分到不同的Prometheus实例中,再由顶层的Prometheus进行数据的统一管理。
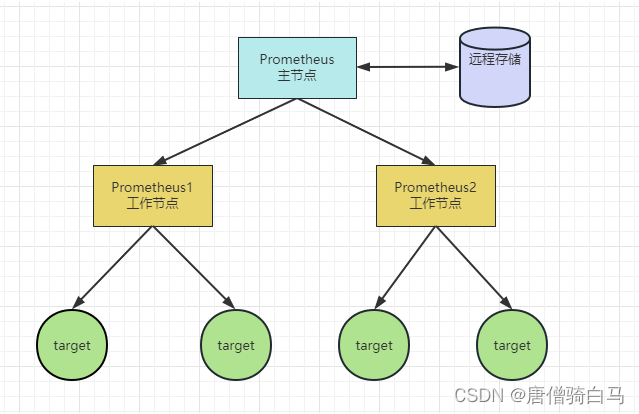
在此方案中,工作节点的Prometheus根据拆分原则,负责指定目标的数据采集及规则告警工作,而主节点则通过/federate
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









