






完全分布式安装(以3台为例)
1.准备工作
1.1修改主机名称
ftj-node1

图一
ftj-node2

图二
ftj-node3

图三
1.2设置静态的IP的
ftj-node1 -> 192.168.134.46

图五
ftj-node2-> 192.168.134.47

图六
ftj-node3 -> 192.168.134.48

图七
1.3配置hosts文件(主机与IP的映射)
每台主机都要添加下面三条配置。
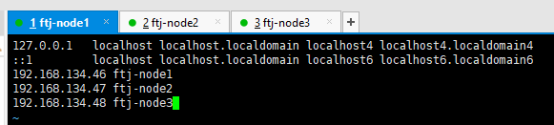
图八
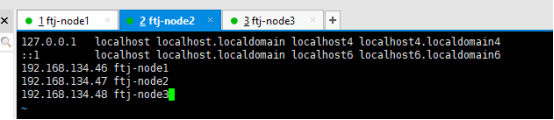
图九
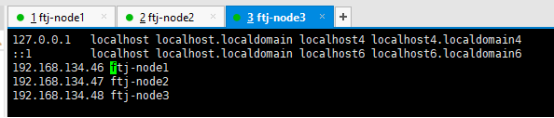
图10
1.4设置免密码登录(从一台机器登录到另一台机器)
1.4.1生成密钥
在三台机器分别执:ssh-keygen -t rsa
1.4.2三台主机都要执行下面的操作
互相复制公钥到每台机器(在每台机器中都执行以下三个命令)
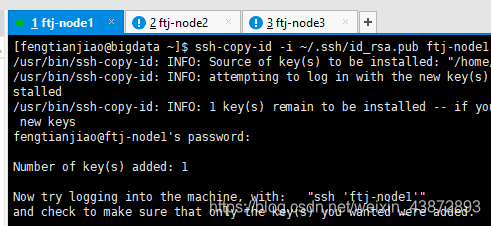
图11
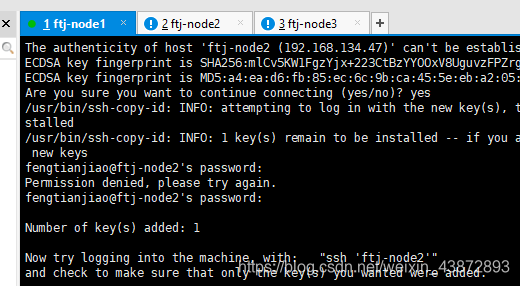
图12
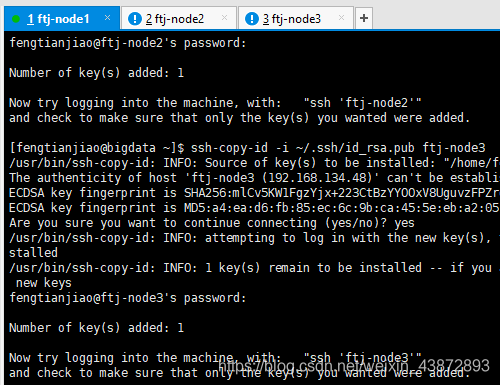
图13
ssh-copy-id -i ~/.ssh/id_rsa.pub ftj-node1 (主机名)
此处需要注意的是:需要在本机上运行之后才运行其他的。
1.5关闭防火墙和selinux
关闭防火墙命令:
sudo systemctl stop firewalld
sudo systemctl disable firewalld

图14
关闭selinux:
vi /etc/selinux/config
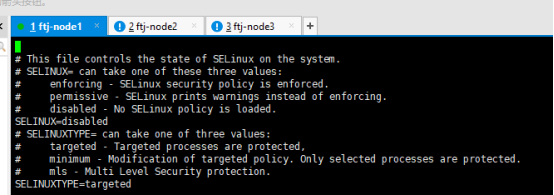
图15
2.主机进行时间同步(让所有的主机时间是一样的)
让所有的主机都在一个时间
不能联网采用 date –s “2019-05-13 00:00:00”
如果可以联网:ntpdate 公用时间服务器
yum –y install ntpdate
ntpdate -u ntp1.aliyun.com
centos8时间同步:
https://blog.youkuaiyun.com/oopxiajun2011/article/details/105454663/
3.安装JDK
三台都需要安装,我们可以安装一台,向其他两台中去分发
Ftj-node1中安装
3.1解压修改名称
3.2在用户变量中配置JAVA的环境变量
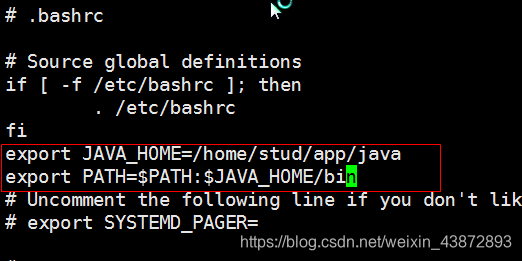
图16
1.安装Hadoop并配置环境变量
图17
图18
图19
5.进行集群规划
hdfs :namenode seconarynamenode(伪分布式和非高靠完全分布式的进程) datanode
Yarn :resourceManager nodeManager
主节点一个(1个namenode进程,1个resourcemanager)
从节点 采用3个(dataname /nodemanager)
主机名称 IP HDFS进程 YARN进程
Ftj-node1 192.168.100.101 Namenode 、datanode Nodemanager
Ftj-node2 192.168.100.102 Seconarynamenode、datanode Nodemanager
Ftj-node3 192.168.100.103 datanode Nodemanager、ResourceManager
6.修改配置文件
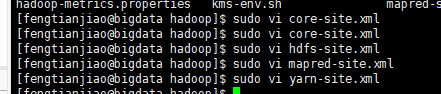
图20
6.1配置hadoop-env.sh
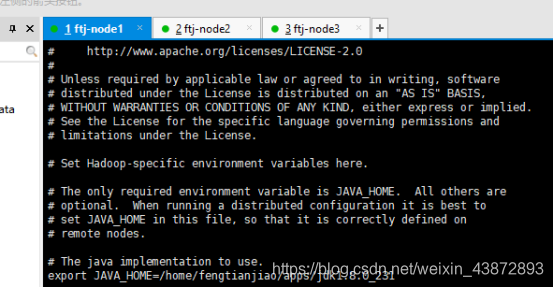
图21
6.2配置 core-site.xml
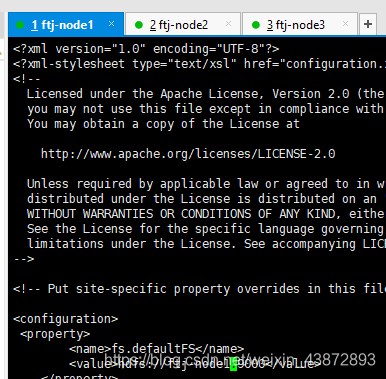
图22
fs.default.name
hdfs://ftj-node1:9000
hadoop.tmp.dir
file:///home/fengtianjiao/apps/tmp/hadoop
</configuration
6.3配置hdfs-site.xml
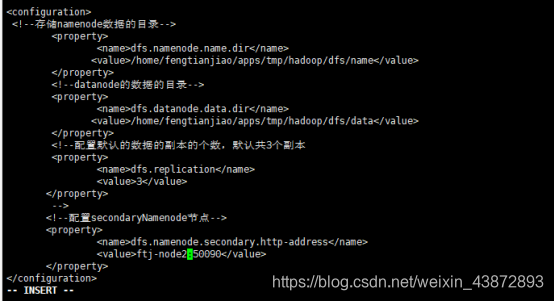
图23
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/fengtianjiao/apps/tmp/hadoop/dfs/name</value>
</property>
<!--datanode的数据的目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/fengtianjiao/apps/tmp/hadoop/dfs/data</value>
</property>
<!--配置默认的数据的副本的个数,默认共3个副本
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
-->
<!--配置secondaryNamenode节点-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>ftj-node2:50090</value>
</property>
图24
mapreduce.framework.name
yarn
6.5.配置yarn-site.xml
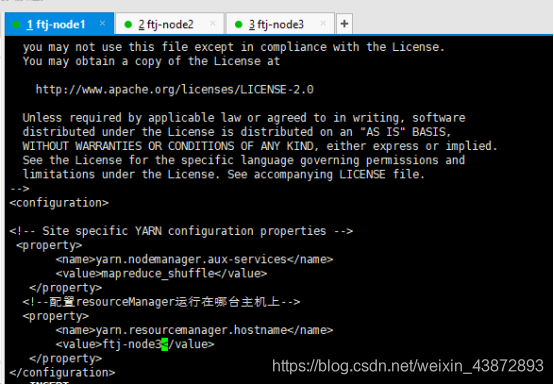
图25
yarn.nodemanager.aux-services
mapreduce_shuffle
图26
图27
7.分发安装包到nod2 node3
将apps目录分发到另外两台机器
scp -r /home/fengtianjiao/apps fengtianjiao@ftj-node2:/home/fengtianjiao
scp -r /home/fengtianjiao/apps wangjian@ftj-node3:/home/fengtianjiao

图28
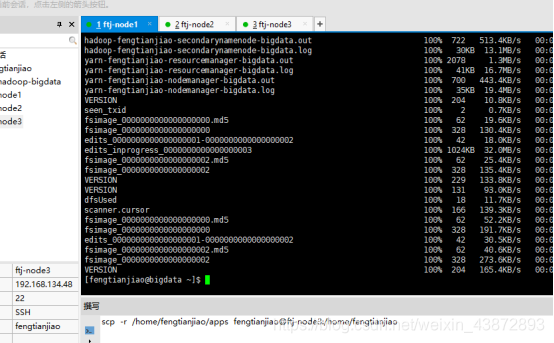
图29
将/etc/profile(配置环境变量的文件)分发到另外两台机器
scp /etc/profile fengtianjiao@ftj-node2 :/home/fengtianjiao
scp /etc/profile fengtianjiao@ftj-node3:/home/fengtianjiao

图30

图31
分别在ftj-node2和ftj-node3执行source /etc/profile命令
8.进行格式化(在namenode主节点格式化)
hdfs namenode -format
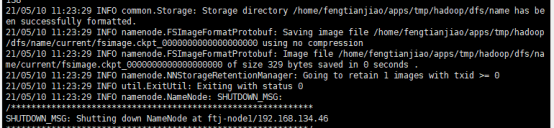
图32
9.启动HDFS
9.1执行启动命令
hdfs主节点配置在ftj-node1上,在ftj-node1中启动hdfs
9.2JSP查看每个节点的进程
ftj-node1:
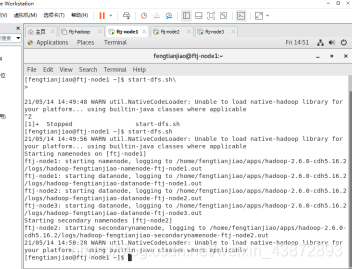

图33
ftj-node2:
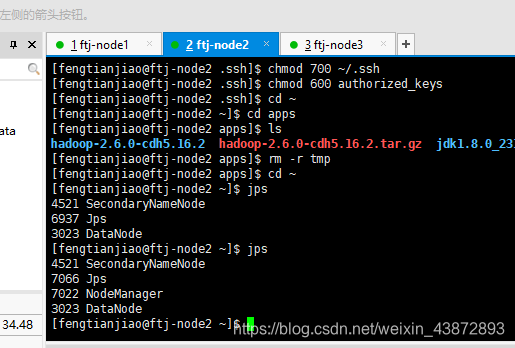
图34
Hadoop103
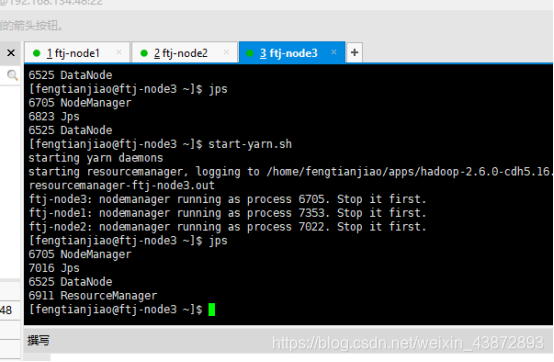
图35
9.3通过web网页查看
192.168.134.46:50070
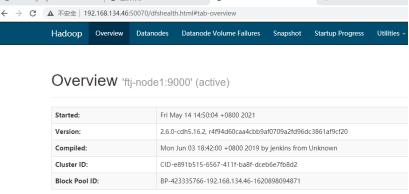
图36
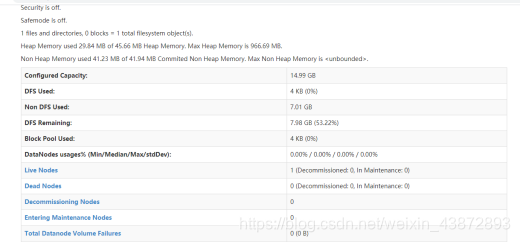
图37
10.启动YARN(必须在yarn的主节点启动)
10.1执行启动命令
Yarn的主节点配置在ftj-node3上,在ftj-node3启动
start-yarn.sh
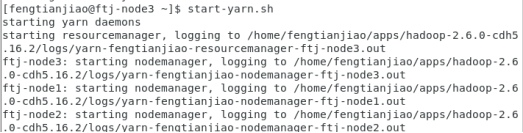
10.2JPS查看每个节点的进程
Ftj-node3的进程
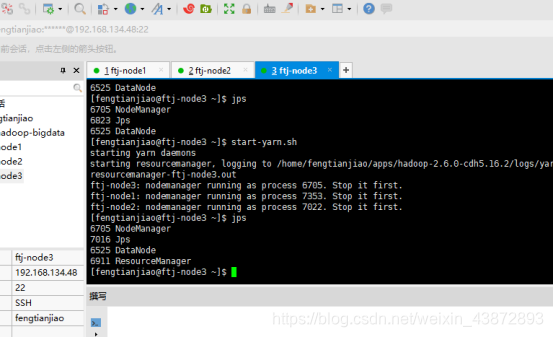
图38
Ftj-node2的进程
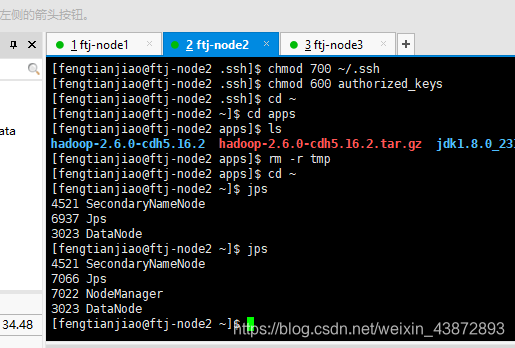
图39
Ftj-node1的进程
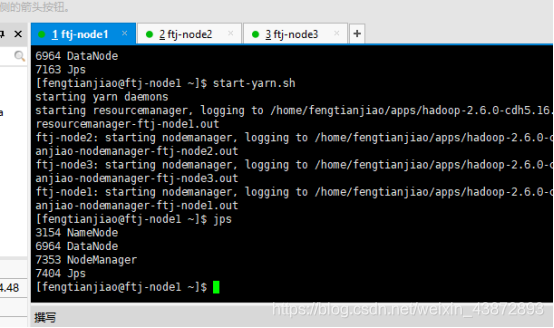
图40
10.3网页web查看
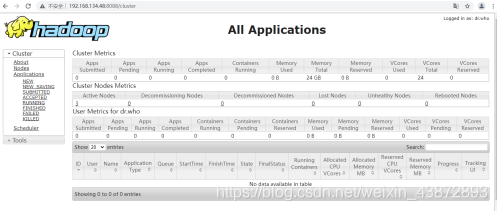
图41
11.hdfs与yarn启动时如果不在主节点
1.hdfs主节点hadoop101
在hadoop102中启动,所有的进程都正常启动了
2.启动yar 主节点hadoop103
在hadoop102中启动,resourceManager进程是无法启动的

















 1692
1692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









