







DataX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
Features
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
System Requirements
- Linux
- JDK(1.8以上,推荐1.8)
- Python(2或3都可以)
- Apache Maven 3.x (Compile DataX)
工具部署
(1)、下载DataX源码:
$ git clone git@github.com:alibaba/DataX.git
(2)、通过maven打包:
$ cd {DataX_source_code_home}
$ mvn -U clean package assembly:assembly -Dmaven.test.skip=true
打包成功,日志显示如下:
[INFO] BUILD SUCCESS
[INFO] -----------------------------------------------------------------
[INFO] Total time: 08:12 min
[INFO] Finished at: 2015-12-13T16:26:48+08:00
[INFO] Final Memory: 133M/960M
[INFO] -----------------------------------------------------------------
打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
$ cd {DataX_source_code_home}
$ ls ./target/datax/datax/
bin conf job lib log log_perf plugin script tmp
直接下载
http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
yum install python3
使用例子
配置示例:从stream读取数据并打印到控制台
-
第一步、创建作业的配置文件(json格式)
可以通过命令查看配置模板: python datax.py -r {YOUR_READER} -w {YOUR_WRITER}
cd {YOUR_DATAX_HOME}/bin $ python datax.py -r streamreader -w streamwriter
根据模板配置json如下:
#stream2stream.json
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}
- 第二步:启动DataX
$ cd {YOUR_DATAX_DIR_BIN}
$ python datax.py ./stream2stream.json
mysql到本地
配置文件
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"user_type",
"user_id",
"code",
"open_id",
"ip",
"gmt_time"
],
"splitPk": "user_id",
"connection": [
{
"table": [
"t_user_login_log"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/develop_xiaoyi_wumei"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print":true
}
}
}
]
}
}
DataX3.0版本提供的Reader插件和Writer插件,每种读插件都有一种和多种切分策略
"reader": {
"name": "mysqlreader", #从mysql数据库获取数据(也支持sqlserverreader,oraclereader)
"name": "txtfilereader", #从本地获取数据
"name": "hdfsreader", #从hdfs文件、hive表获取数据
"name": "streamreader", #从stream流获取数据(常用于测试)
"name": "httpreader", #从http URL获取数据
}
"writer": {
"name":"hdfswriter", #向hdfs,hive表写入数据
"name":"mysqlwriter ", #向mysql写入数据(也支持sqlserverwriter,oraclewriter)
"name":"streamwriter ", #向stream流写入数据。(常用于测试)
}
/root/datax/plugin/reader/._rdbmsreader/plugin.json]不存在
rm -rf ._* |xargs rm -rf
python bin/datax.py script/mysqlReader.json
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [
{
"querySql": [
"select * from t_user_login_log;"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/develop_xiaoyi_wumei"
]
}
]
}
},
"writer": {
"name": "txtfilewriter",
"parameter": {
"path": "/root/datax/export",
"fileName": "log.txt",
"writeMode": "truncate",
"dateFormat": "yyyy-MM-dd HH:mm:ss"
}
}
}
]
本地到阿里云oss
#下载ossutil工具
wget https://gosspublic.alicdn.com/ossutil/1.7.9/ossutil64
#运行以下命令修改文件执行权限
chmod 755 ossutil64
#使用交互式配置生成配置文件。
./ossutil64 config
#根据提示设置配置文件路径。
#建议直接按回车使用默认配置文件的路径。
请输入配置文件名,文件名可以带路径(默认为:/home/user/.ossutilconfig,回车将使用默认路径。
#如果用户设置为其它路径,在使用命令时需要将--config-file选项设置为该路径):
#ossutil默认使用/home/user/.ossutilconfig作为配置文件,若您设置了配置文件的路径,则每次使用命令时需增加-c选项指定配置文件。例如配置文件保存为/home/config,使用ls时,命令格式如下:
#./ossutil64 ls oss://examplebucket -c /home/config
根据提示设置工具的语言。
#请输入语言CH或EN。工具使用的语言默认与操作系统保持一致。该配置项将在此次config命令设置成功后生效。
#根据提示分别设置Endpoint、AccessKey ID、AccessKey Secret和STSToken参数。
#参数说明如下:
#endpoint:填写Bucket所在地域的Endpoint。各地域Endpoint详情,请参见访问域名和数据中心。
#您也可以增加http://或https://指定ossutil访问OSS使用的协议,默认使用HTTP协议。例如使用HTTPS协议访问深圳的Bucket,设置为https://oss-cn-shenzhen.aliyuncs.com。
#accessKeyID、accessKeySecret:填写账号的AccessKey。
#使用阿里云账号或RAM用户访问时,AccessKey的获取方式,请参见获取AccessKey。
#使用STS临时授权账号访问时,AccessKey的获取方式,请参见使用STS临时访问凭证访问OSS。
#stsToken:使用STS临时授权账号访问OSS时需要配置该项,否则置空即可。stsToken生成方式参见临时访问凭证。
oss-cn-beijing.aliyuncs.com
LTAI5t9xTbpEDaPiy4L6JPeJ
mIQzsqlV8qtQJUJ8e1f3HDRxAVFhoM
上传文件命令
./ossutil64 cp file_url cloud_url
举个例子:
不应该按此格式输入 xxxxx.oss-cn-beijing-internal.aliyuncs.com
直接填入 xxxxx 即可。
[root@w1 export]# /root/ossutil64 cp log.txt oss://datax-demo/log.txt
Succeed: Total num: 1, size: 875. OK num: 1(upload 1 files).
average speed 5000(byte/s)
0.153771(s) elapsed
oss到clickhouse
{
"job": {
"setting": {
#不能为空
"speed": {
"byte":10485760
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "ossreader",
"parameter": {
"endpoint": "oss-cn-beijing.aliyuncs.com",
"accessId": "LTAI5t9xTbpEDaPiy4L6JPeJ",
"accessKey": "mIQzsqlV8qtQJUJ8e1f3HDRxAVFhoM",
"bucket": "datax-demo",
"object": [
"log.txt"
],
"column": [
{
"type": "long",
"index": 0
},
{
"type": "string",
"index": 1
},
{
"type": "long",
"index": 2
},
{
"type": "string",
"index": 3
},
{
"type": "string",
"index": 4
},
{
"type": "string",
"index": 5
},
{
"type": "date",
"index": 6,
"format": "yyyy-MM-dd HH:mm:ss"
}
],
"encoding": "UTF-8",
"fieldDelimiter": "\t",
"compress": "gzip"
}
},
"writer": {
"name": "clickhousewriter",
"parameter": {
"username": "testclickhouse",
"password": "123qweasdzxc!@#",
"column": ["id", "user_type", "user_id","code","open_id","ip","gmt_time"],
"connection": [
{
"jdbcUrl": "jdbc:clickhouse://172.17.0.8:8123/testdb",
"table": ["t_log"]
}
],
"preSql": [],
"postSql": [],
"batchSize": 65536,
"batchByteSize": 134217728,
"dryRun": false,
"writeMode": "insert"
}
}
}
]
}
}
Datax的执行过程调优
要想进行调优,一般先要了解执行过程,执行过程如下:
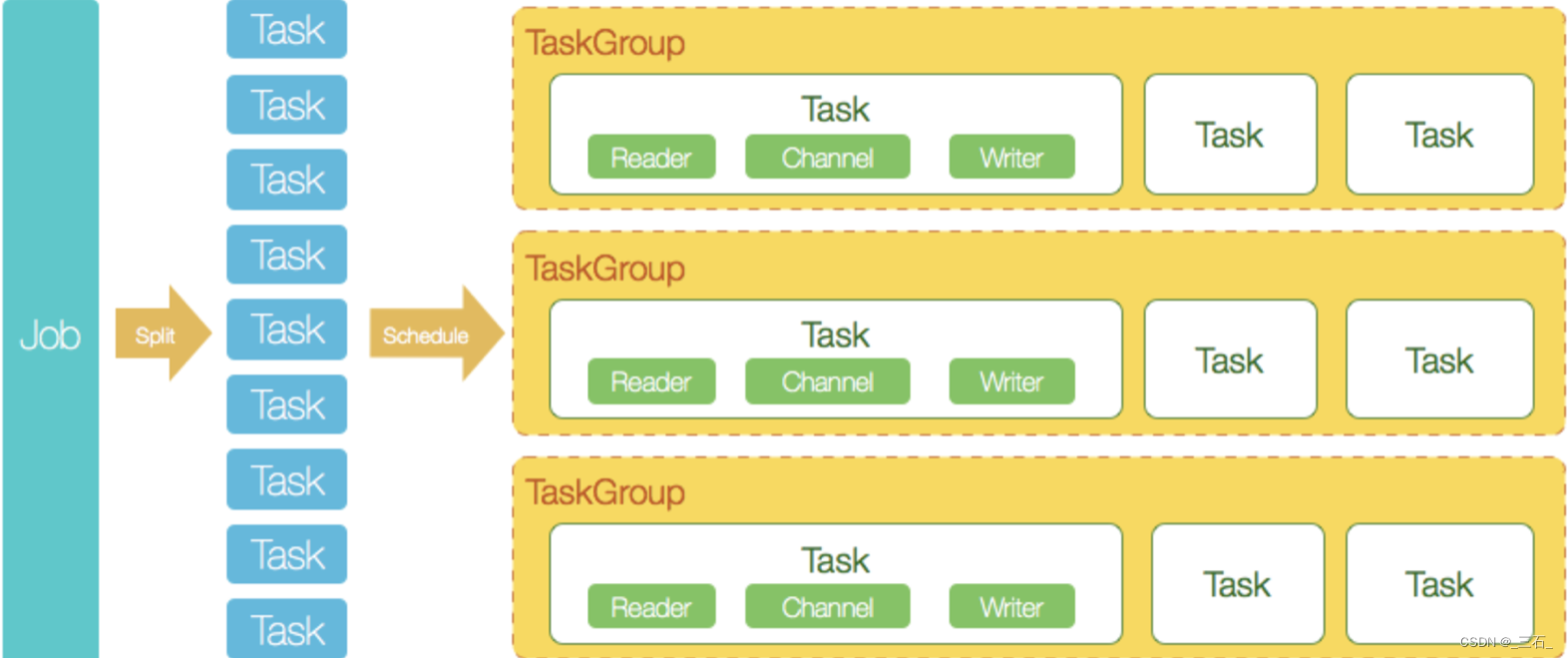
过程详细说明如下:
DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
优化1:提升每个channel的速度
在DataX内部对每个Channel会有严格的速度控制,分两种,一种是控制每秒同步的记录数,另外一种是每秒同步的字节数,默认的速度限制是1MB/s,可以根据具体硬件情况设置这个byte速度或者record速度,一般设置byte速度,比如:我们可以把单个Channel的速度上限配置为5MB
优化2:提升DataX Job内Channel并发数
并发数=taskGroup的数量每一个TaskGroup并发执行的Task数 (默认单个任务组的并发数量为5)。
提升job内Channel并发有三种配置方式:
配置全局Byte限速以及单Channel Byte限速,Channel个数 = 全局Byte限速 / 单Channel Byte限速
配置全局Record限速以及单Channel Record限速,Channel个数 = 全局Record限速 / 单Channel Record限速
直接配置Channel个数.
配置含义:
job.setting.speed.channel : channel并发数
job.setting.speed.record : 全局配置channel的record限速
job.setting.speed.byte:全局配置channel的byte限速
core.transport.channel.speed.record:单channel的record限速
core.transport.channel.speed.byte:单channel的byte限速
方式1:
举例如下:core.transport.channel.speed.byte=1048576,job.setting.speed.byte=5242880,所以Channel个数 = 全局Byte限速 / 单Channel Byte限速=5242880/1048576=5个,配置如下:
{
“core”:
{
“transport”:
{
“channel”:
{
“speed”: {“byte”: 1048576}
}
}
},
“job”:
{
“setting”:
{
“speed”: {“byte” : 5242880}
},
}
}
方式2:
举例如下:core.transport.channel.speed.record=100,job.setting.speed.record=500,所以配置全局Record限速以及单Channel Record限速,Channel个数 = 全局Record限速 / 单Channel Record限速=500/100=5
{“core”: {“transport”: {“channel”: {“speed”: {“record”: 100}
}
}
},“job”: {“setting”: {“speed”: {“record” : 500}
},
…
}
}
方式3:
举例如下:直接配置job.setting.speed.channel=5,所以job内Channel并发=5个
{“job”: {“setting”: {“speed”: {“channel” : 5}
},
…
}
}
注意事项
当提升DataX Job内Channel并发数时,调整JVMheap参数,原因如下:
-
当一个Job内Channel数变多后,内存的占用会显著增加,因为DataX作为数据交换通道,在内存中会缓存较多的数据。
-
例如Channel中会有一个Buffer,作为临时的数据交换的缓冲区,而在部分Reader和Writer的中,也会存在一些Buffer,为了防止jvm报内存溢出等错误,调大jvm的堆参数。
-
通常我们建议将内存设置为4G或者8G,这个也可以根据实际情况来调整
-
调整JVM xms xmx参数的两种方式:一种是直接更改datax.py;另一种是在启动的时候,加上对应的参数,如下:
python datax/bin/datax.py --jvm=“-Xms8G -Xmx8G” XXX.json
Channel个数并不是越多越好, 原因如下:
-
Channel个数的增加,带来的是更多的CPU消耗以及内存消耗。
-
如果Channel并发配置过高导致JVM内存不够用,会出现的情况是发生频繁的Full GC,导出速度会骤降,适得其反。这个可以通过观察日志发现


















 3321
3321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











