







DataX学习
DataX3.0概览
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。学习可见官网资料(https://github.com/alibaba/DataX)。
设计理念:
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
DataX框架设计
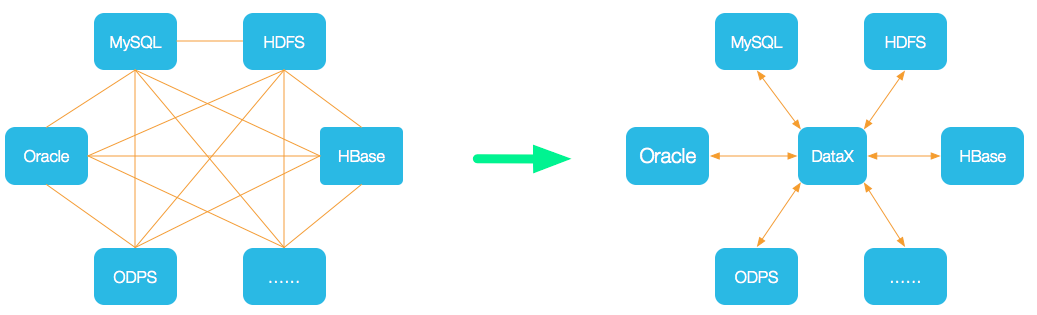
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX插件体系
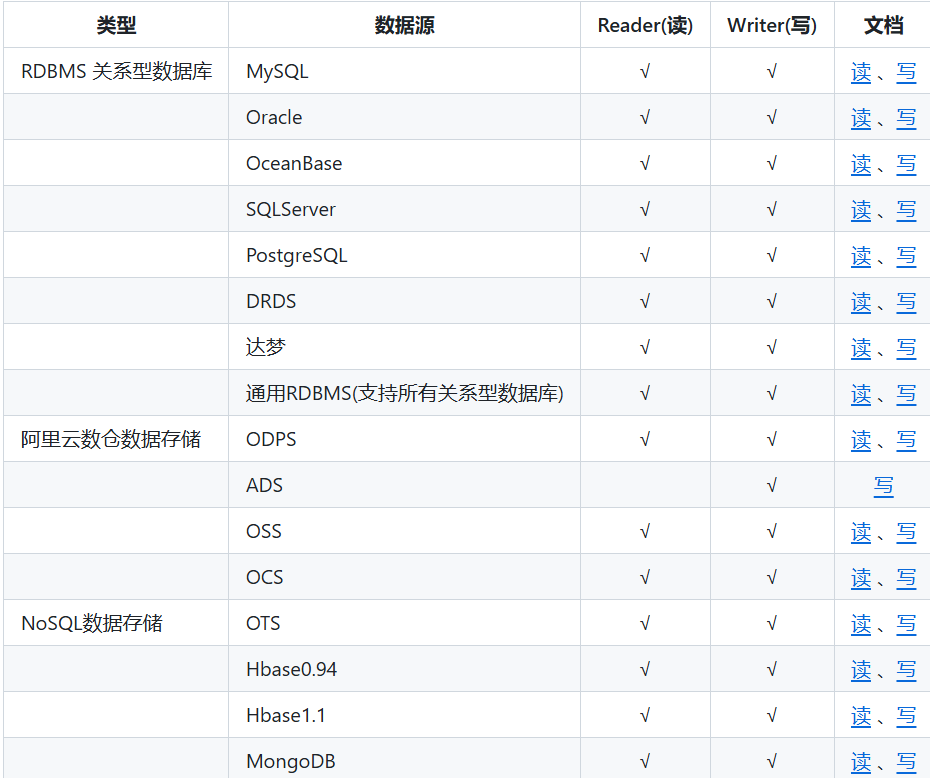
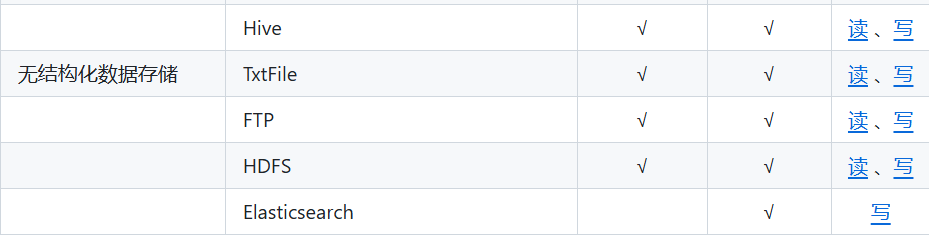
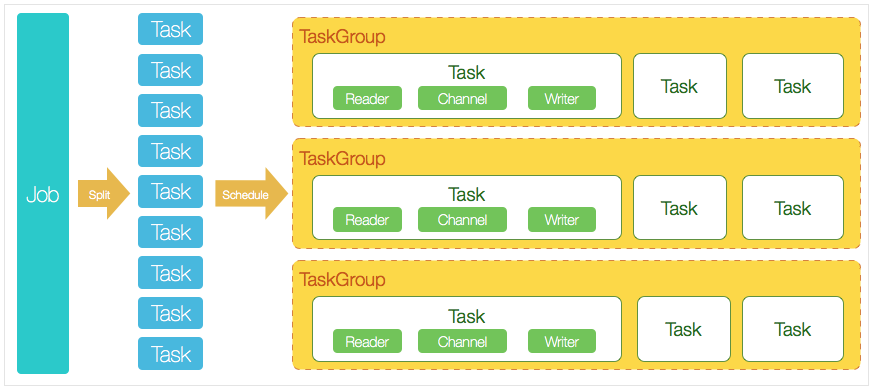
DataX核心架构
DataX六大核心优势
可靠的数据质量监控
丰富的数据转换功能
精准的速度控制
强劲的同步性能
健壮的容错机制
极简的使用体验
DataX与sqoop对比
| 功能 | DataX | Sqoop |
|---|---|---|
| 运行模式 | 单进程多线程 | MR |
| 分布式 | 不支持,可以通过调度系统规避 | 支持 |
| 流控 | 有流控功能 | 需要定制 |
| 统计信息 | 已有一些统计,上报需定制 | 没有,分布式的数据收集不方便 |
| 数据校验 | 在core部分有校验功能 | 没有,分布式的数据收集不方便 |
| 监控 | 需要定制 | 需要定制 |
DataX部署
1.下载datax jar包
地址:(https://github.com/alibaba/DataX?tab=readme-ov-file)
2.上传jar包 解压并配置环境变量
tar -zxvf datax.tar.gz
#添加环境变量
DATAX_HOME=/usr/local/soft/datax
export PATH=$DATAX_HOME/bin:$PATH
#生效
source /etc/profile
3.自检
#给bin目录下的datax.py赋予执行权限
chmod +x datax.py
#查看是否成功安装
python ./bin/datax.py ./job/job.json
DataX使用
在bigdata30目录下创建datax_jsons文件夹用于存储脚本
mkdir datax_jsons
小例子:创建stream2stream.json
{
"job": {
"setting": {
"speed": {
"channel":1
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column" : [
{
"value": "我是",
"type": "string"
},
{
"value": "大",
"type": "string"
},
{
"value": "帅",
"type": "string"
},
{
"value": "哥",
"type": "string"
},
{
"value": "哈哈哈",
"type": "string"
}
],
"sliceRecordCount": 10 // 打印次数
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true, //是否打印
"encoding": "UTF-8"
}
}
}
]
}
}
运行 datax.py stream2stream.json
结果:
DataX配置文件格式
编写json文件的步骤:
1、根据你确定的reader和writer来使用命令生成对应的模板
2、去github上找到对应参数值的写法,主要是看参数是否是必须项,有什么影响
如果你不知道怎么写模版 可以去官网查看 或者使用如下命名查看DataX配置文件模板。
datax.py -r mysqlreader -w hdfswriter #以mysql-->hdfs为例
生成模版:
解读:json最外层是一个job,job包含setting和content两部分,其中setting用于对整个job进行配置,content用户配置数据源和目的地。
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
然后,可以根据官网给出的样例进行更改:

在参数说明中还能了解哪些参数必选和默认值等内容ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3321
3321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









