







俗话说,没有对比就没有伤害,为了体现出Tensorflow2.0,PyTorch等深度学习框架的便捷性,这次我们使用科学计算库Numpy来实现在整个机器学习领域中最重要,也是最基础的迭代优化算法----梯度下降法。
话不多说,上菜
导包:
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
%matplotlib inline计算误差
def total_error_of_calculation(points,w,b):
error_total=0
length=len(point)
for i in range(length):
x_=point[i][0]
y_=point[i][1]
error_total+=(y_-(w*x_+b))**2
return error_total/float(100)生成梯度
def step_gradient(w_current,b_current,points,learning_rate):
w_gradient=0
b_gradient=0
N=float(len(points))
for i in range(int(N)):
x=points[i][0]
y=points[i][1]
w_gradient+=((2/N)*(w_current*x+b_current-y)*x)
b_gradient+=((2/N)*(w_current*x+b_current-y))
new_w=w_current-learning_rate*w_gradient
new_b=b_current-learning_rate*b_gradient
return [new_w,new_b]梯度下降法
def gradient_descent_runner(points,start_w,start_b,learning_rate,num_iterations):
w=start_w
b=start_b
for i in range(num_iterations):
w,b=step_gradient(w,b,points,learning_rate)
return w,b绘制图像
def drawing_images(points,w,b):
x=points[:,0]
y=points[:,1]
plt.scatter(x,y,c='r',marker='*')
plt.plot(x,w*x+b)
plt.show()
return None获取最终w和b
def runner():
X,y=datasets.make_regression(n_samples=100,n_features=1,noise=10,bias=10) # 生成100个样本点
points=np.concatenate([X,y.reshape(100,1)],axis=1) # 将其转换成数组
init_w=np.random.rand() # 初始化w
init_b=np.random.rand() # 初始化b
init_error=total_error_of_calculation(points,init_w,init_b)
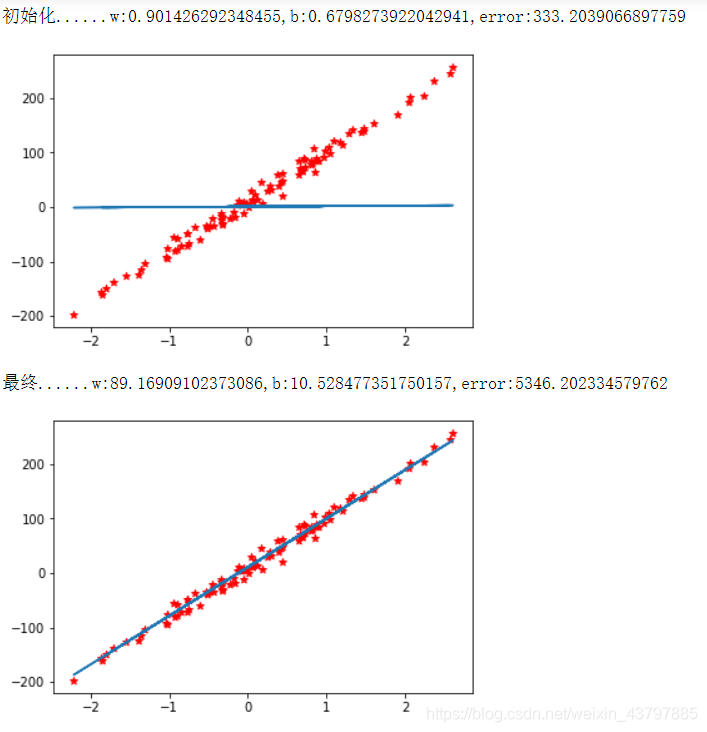
print("初始化......w:{},b:{},error:{}".format(init_w,init_b,init_error))
drawing_images(points,init_w,init_b)
# 迭代更新,生成新的w、b
learning_rate=0.001
num_iterations=2000
w,b=gradient_descent_runner(points,init_w,init_b,learning_rate,num_iterations) # 生成新的w和b
error=total_error_of_calculation(points,w,b)
print("最终......w:{},b:{},error:{}".format(w,b,error))
drawing_images(points,w,b)
runner()结果展示


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









