







自我注意力蒸馏来自文章(链接):Learning Lightweight Lane Detection CNNs by Self Attention Distillation
项目地址:Codes-for-Lane-Detection
说到蒸馏,可能想到最多的就是知识蒸馏、注意力蒸馏,他们三者关系是什么?
下面是作者逆风g做的总结:
- 知识蒸馏(Knowledge distillation):用于把大网络学习到的内容(knowledge)迁移到小网络中。具体有两个目标要学习,一是小网络输出与真值的相似,二是让小网络与大网络的输出相似。
- 注意力蒸馏(Attention distillation):用于把大网络学习到的注意力特征图(attention map)迁移到小网络中。具体在知识蒸馏基础上,再对网络中间层特征进行迁移,以保证大小网络中间的注意力特征图相似。
- 自注意力蒸馏(Self Attention Distillation):抛弃大网络,单独在小网络中对不同层学习到的注意力特征图进行迁移学习。
知识蒸馏
知识蒸馏首次在论文Distilling the Knowledge in a Neural Network中提出
参照知识蒸馏是什么?一份入门随笔先来说下深度学习中的知识蒸馏:
什么是知识蒸馏?深度学习中的知识蒸馏可以理解为,将复杂“模型”中的“知识”,应用到简单模型中。
知识蒸馏中大网络为教师网络(teacher network:复杂、但推理性能优越),小网络为学生网络(student network:精简、低复杂度),知识蒸馏将教师网络相关的软目标(soft-target)作为total loss的一部分,以诱导学生网络(student network:精简、低复杂度)的训练,实现知识迁移(knowledge transfer)。
为什么要进行知识蒸馏呢?
“大网络”更复杂,网络学习能力非常强,往往能够获得较好的效果,但需要的计算量和计算资源很大。这时希望有一个规模较小的网络,能达到和大网络一样或相当的结果。从头训练一个小模型,从经验上看是很难达到上述效果的,也许我们能先训练一个大而强的模型,然后将其包含的知识转移给小的模型。
如何将大网络包含的“知识”转移给小网络呢?
如果从头学习一个小网络就是从有限的数据中近似一个未知的函数,即需要让小网络的softmax分布与真实标签(即:hard target,网络拟合非0即1)匹配,相当于从头开始训练小网络,可能达不到预期效果。
如果让小网络近似大网络,由于大网络的函数是已知的,我们可以使用很多非训练集内的伪数据来训练新模型,这显然要更可行,即让小网络拟合大网络在给定输入下的softmax分布(soft target)。
因为hard target 包含的信息量(信息熵)很低,soft target包含的信息量大,拥有不同类之间关系的信息(比如同时分类驴和马的时候,尽管某张图片是马,但是soft target就不会像hard target 那样只有马的index处的值为1,其余为0,而是在驴的部分也会有概率,因为相对于狗和驴,马更接近驴。)
如何将teacher网络学到数据的相似信息传达给student网络呢?因此,提出了softmax-T

其中
T
T
T 是温度,是从统计力学中的玻尔兹曼分布中借用的概念。这里
q
i
q_i
qi 是student网络学习的对象(soft targets),
z
i
z_i
zi 是teacher网络softmax前的输出logit。
- 如果将T取1,这个公式就是softmax,根据logit输出各个类别的概率。
- 如果T接近于0,则最大的值会越近1,其它值会接近0,近似于onehot编码。
- 如果T越大,则输出的结果的分布越平缓,相当于平滑的一个作用,起到保留相似信息的作用。
- 如果T等于无穷,就是一个均匀分布。
因此,在训练student网络的时候,可以使用较高的
T
T
T 使得softmax产生的分布足够软,这时让student网络的softmax输出近似原模型;在训练结束以后再使用正常的温度
T
=
1
T=1
T=1 来预测。具体地,在训练时我们需要最小化两个分布的交叉熵(Cross-entropy),记student网络利用上述公式产生的分布是
q
q
q ,teacher网络产生的分布是
p
p
p ,则我们需要最小化:

当然,如果转移时使用的是有标签的数据,那么也可以将标签与student网络softmax分布的交叉熵加入到损失函数中去。
在化学中,蒸馏是一个有效的分离沸点不同的组分的方法,大致步骤是先升温使低沸点的组分汽化,然后降温冷凝,达到分离出目标物质的目的。在前面提到的这个过程中,我们先让温度 T T T 升高,然后在测试阶段恢复「低温」,从而将teacher网络中的知识提取出来,因此将其称为是蒸馏。
自注意力蒸馏
注意力特征图包含两种类型:一种是activation-based attention maps,另一种是gradient-based attention maps,二者区别为是否使用激活函数。
Activation-based attention distillation
A m ∈ R C m × H m × W m A_m\in R^{C_m\times H_m\times W_m} Am∈RCm×Hm×Wm表示网络第 m m m 层的激活输出,其中 C m C_m Cm、 H m H_m Hm和 W m W_m Wm分别表示通道、高度和宽度。注意图的生成等价于寻找一个映射函数 g g g:
R
C
m
×
H
m
×
W
m
→
R
H
m
×
W
m
R^{C_m\times H_m\times W_m} \to R^{H_m\times W_m}
RCm×Hm×Wm→RHm×Wm
该映射中每个元素的绝对值表示该元素对最终输出的重要性,因此,可以通过这些跨通道维度的值的计算统计来构造此映射函数。具体来说,可以通过以下三种操作作为映射函数:

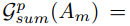
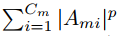

其中,p > 1和
A
m
i
A_{mi}
Ami表示
A
m
A_m
Am在通道维度中的第
i
i
i 个切片。下面展示了这三种映射函数的区别。

在训练中添加SAD:
前一层的attention maps可以从后续层中提取有用的上下文信息。还在
G
s
u
m
2
(
A
m
)
G^2_{sum} (Am)
Gsum2(Am)上执行空间
s
o
f
t
m
a
x
softmax
softmax 操作
Φ
(
:
)
Φ(:)
Φ(:)。如果原始注意图大小与目标不同,则在
s
o
f
t
m
a
x
softmax
softmax 操作前添加双线性上采样
B
(
:
)
B(:)
B(:) 。
将SAD添加到现有的网络中是很直接的。可以在训练的不同时间点引入SAD,这会影响收敛时间。

一个使用SAD的实例。E1 ~ E4包含ENet的编码器,D1和D2构成了ENet的解码器。后面添加一个小网络来预测
l
a
n
e
lane
lane的存在性,记为P1。AT-GEN是注意力发生器。在ENet的每个E2、E3和E4编码器块之后添加了一个注意力生成器,缩写为AT-GEN。
形式上,AT-GEN由一个函数表示:
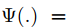
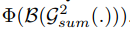
连续的分层蒸馏损失公式如下:

L
d
L_d
Ld通常定义为
L
2
L_2
L2损失和
Ψ
(
A
m
+
1
)
Ψ(A_{m+1})
Ψ(Am+1)是蒸馏损失的目标。全部损失包括四项:

前两个词是分割损失,包括标准交叉熵损失Lseg和IoU损失LIoU。IoU损失的目的是增加预测车道像素和ground truth车道像素的相交超联合。


















 4849
4849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











