






问题-0 QT-UI显示过程与特性
-
根据QT文档,QT的UI显示,最终都会落到“Window”和“View”上,“window”是逻辑层面,“View”是物理层面
-
绘制时,坐标系在逻辑层面,但显示效果又和view相关。
-
不在显示区域的元素,Qt不会刷新。以QTableView为例,其 默认仅渲染当前可见区域内的单元格(通过 viewport() 区域计算),滚动时会动态请求新数据。viewport()函数本身也是继承自虚基类,总体来说,所有的UI应该都是不可见区域不刷新。
-
对于Model-View,当模型通过 dataChanged() 等信号通知视图时,若信号中的索引(QModelIndex)位于当前可见区域,则视图会立即刷新对应单元格;若在不可见区域,视图仅标记数据变化,但不会主动刷新
-
全局刷新视图
调用 tableView->viewport()->update() 或 tableView->reset(),强制视图重新加载所有数据(包括不可见区域)。
缺点:性能开销大,可能影响用户体验,尤其是数据量较大时。 -
局部刷新
通过 dataChanged() 信号或其他信号,指定具体变化的索引范围:
QModelIndex topLeft = model->index(start_row, start_col);
QModelIndex bottomRight = model->index(end_row, end_col);
emit dataChanged(topLeft, bottomRight);
随后View会相应该信号,若变化范围包含不可见区域的索引,视图会在滚动到该区域时自动加载最新数据
问题-1
Qt Model-View架构,Model可以使用fetchMore()方法,来实现分段动态加载。
分阶段加载思想
- 改写rowCount()方法,让返回值小于数据真实行数
return parent.isValid() ? 0 : fileCount;
- 改写canFetchMore()方法:
return (fileCount < fileList.size());
- 改写fetchMore()方法,如下:
int remainder = fileList.size() - fileCount;
int itemsToFetch = qMin(100, remainder);
if (itemsToFetch <= 0)
return;
beginInsertRows(QModelIndex(), fileCount, fileCount + itemsToFetch - 1);
fileCount += itemsToFetch;
endInsertRows();
emit numberPopulated(itemsToFetch); // 自定义的信号
部分加载思想(分页加载或滚动条进度加载)
基本思想是:获得页面或区域对应的行号范围,然后重写data() 函数,实现对特定范围数据的显示。
具体参见相关实例,比较多,不在赘述。
问题-2 QStringLiteral(“hello world”)有啥用
(节选自:https://blog.youkuaiyun.com/u013001137/article/details/104103590)
- QStringLiteral(“str”) 是个宏,可以在编译期把代码里的常量字符串 str 直接构造为 QString 对象,避免运行时开销。
- 生成的字符串数据存储在编译的目标文件的只读段中。
- 对于不支持创建编译时字符串的编译器,QStringLiteral 的使用效果将与使用 QString::fromUtf8() 一样。
对于下面语句,将创建一个临时 QString 作为 hasAttribute 函数的参数传递,涉及内存分配以及将数据复制和转换为 QString 的内部编码数据,比较耗时。
if (node.hasAttribute("http-contents-length"))
// 改为下面:
if (node.hasAttribute(QStringLiteral("http-contents-length")))
使用 QStringLiteral 而不是双引号的 ascii 文字可以大大加快从编译时已知的数据中创建 QString 的速度。
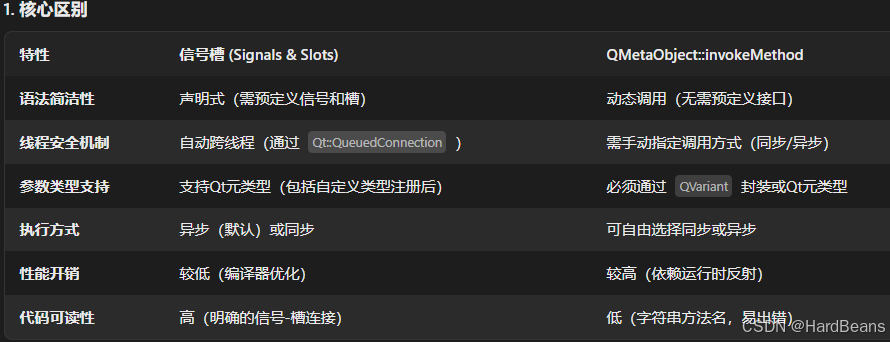
问题-3 QT信号槽与QMetaObject::invokeMethod静态函数的区别。
虽然没看代码,但我想内部机理应当是相同的,无非就是利用元数据系统的架构,将要调用的函数放到某个列表里,通过事件系统实现线程安全。
我用QMetaObject::invokeMethod静态函数主要在全局观察着模式上,一个典型的类如下:
// H文件
typedef struct {
QString trigger;
QObject* reciver;
const char* method; // InvokeMethod used!
} RELATIONMAP;
// Q_DECLARE_METATYPE(RELATIONMAP)
class gOB : public QObject {
Q_OBJECT
private:
explicit gOB(QObject* parent = nullptr)
: QObject { parent }
{
}
gOB(const gOB&) = delete;
gOB& operator=(const gOB&) = delete;
~gOB()
{
// free Data
QList<RELATIONMAP*>::iterator iter = m_RelationList.begin();
while (iter != m_RelationList.end()) {
delete *iter;
iter++;
}
qDebug() << "Singleton cleared!";
}
public:
static gOB* getInstance()
{
if (m_pInst == NULL) {
m_Mutex.lock();
if (m_pInst == NULL) {
m_pInst = new gOB();
qDebug() << "Singleton Constructed!";
}
m_Mutex.unlock();
}
return m_pInst;
}
static void killInstance()
{
if (m_pInst != NULL) {
delete m_pInst;
m_pInst = NULL;
}
qDebug() << "Singleton Destructed!";
}
void attach(const QString trigger, QObject* reciver, const char* method);
void detach(const QString trigger, const QObject* reciver);
void notify(const QString trigger,
Qt::ConnectionType connectiontype = Qt::AutoConnection,
QGenericArgument val0 = QGenericArgument(nullptr),
QGenericArgument val1 = QGenericArgument(),
QGenericArgument val2 = QGenericArgument(),
QGenericArgument val3 = QGenericArgument(),
QGenericArgument val4 = QGenericArgument(),
QGenericArgument val5 = QGenericArgument(),
QGenericArgument val6 = QGenericArgument(),
QGenericArgument val7 = QGenericArgument(),
QGenericArgument val8 = QGenericArgument(),
QGenericArgument val9 = QGenericArgument());
private:
static gOB* m_pInst;
static QMutex m_Mutex;
QList<RELATIONMAP*> m_RelationList {};
signals:
// add your speed-required sigs
void sig_todo();
};
/**************************initilize static parameters*************************/
gOB* gOB::m_pInst = NULL;
QMutex gOB::m_Mutex;
/*******************************methods impliments*****************************/
void gOB::attach(const QString trigger, QObject* reciver, const char* method)
{
RELATIONMAP* pRelationMap = new RELATIONMAP();
pRelationMap->trigger = trigger;
pRelationMap->reciver = reciver;
pRelationMap->method = method;
m_RelationList.append(pRelationMap);
}
void gOB::detach(const QString trigger, const QObject* reciver)
{
QList<RELATIONMAP*>::iterator iter = m_RelationList.begin();
while (iter != m_RelationList.end()) {
if ((*iter)->trigger.compare(trigger) == 0 && (*iter)->reciver == reciver) {
// RELATIONMAP* pRelationMap = *iter;
// delete pRelationMap;
delete *iter;
m_RelationList.removeOne(*iter);
return;
}
iter++;
}
}
void gOB::notify(const QString trigger,
Qt::ConnectionType connectionType,
QGenericArgument val0,
QGenericArgument val1,
QGenericArgument val2,
QGenericArgument val3,
QGenericArgument val4,
QGenericArgument val5,
QGenericArgument val6,
QGenericArgument val7,
QGenericArgument val8,
QGenericArgument val9)
{
QList<RELATIONMAP*>::iterator iter = m_RelationList.begin();
while (iter != m_RelationList.end()) {
if ((*iter)->trigger.compare(trigger) == 0) {
QMetaObject::invokeMethod((*iter)->reciver, (*iter)->method, connectionType, val0, val1, val2, val3, val4, val5, val6, val7, val8, val9);
}
iter++;
}
}
- 使用时,在合适的位置:
gOB::getInstance()->attach("trg_Upd", this,
"do_Upd");
主要特点
QMetaObject::invokeMethod
- 运行时调用:QMetaObject::invokeMethod 在运行时动态调用方法,适用于需要在运行时决定调用哪个方法的场景。
- 灵活的参数传递:可以传递多个参数,支持返回值。
- 线程安全:支持跨线程调用,可以通过 Qt::QueuedConnection 实现线程间的同步。
- 手动调用:需要手动调用 QMetaObject::invokeMethod,不会自动调用。
信号槽
- 编译时检查:信号和槽的连接在编译时进行检查,确保信号和槽的签名匹配。
线程安全:信号槽机制支持跨线程的通信,可以通过 Qt::QueuedConnection 和 Qt::BlockingQueuedConnection 实现线程间的同步。
自动调用:当信号被发射时,槽函数会自动被调用,无需手动调用。
多对多关系:一个信号可以连接到多个槽,一个槽也可以连接到多个信号。
相同点
- 动态调用:两者都可以在运行时动态调用对象的方法。
- 线程安全:两者都支持跨线程调用,可以通过 Qt::QueuedConnection 实现线程间的同步。
不同点
调用方式:
- 信号槽机制:通过 connect 函数将信号和槽连接起来,当信号被发射时,槽函数自动被调用。
- QMetaObject::invokeMethod:需要手动调用 QMetaObject::invokeMethod,不会自动调用。
编译时检查:
- 信号槽机制:在编译时进行检查,确保信号和槽的签名匹配。
- QMetaObject::invokeMethod:在运行时进行调用,不会在编译时检查方法的存在性和签名。
使用场景:
- 信号槽机制:适用于对象之间需要通信的场景,特别是需要响应事件的场景。
- QMetaObject::invokeMethod:适用于需要在运行时动态调用方法的场景,特别是在反射和插件系统中。
另外,咨询DeepSeek后得到的结果
关键选择建议
- 优先使用信号槽的情况:
需要明确的接口定义(如长期维护的代码)。
涉及大量跨线程通信(性能更优)。
参数类型复杂(避免手动封装QVariant)。 - 优先使用invokeMethod的情况:
需要动态调用未知方法(如插件系统)。
强制同步执行(如等待主线程完成操作)。
临时或少量跨线程调用(减少信号槽声明)。
性能对比
信号槽:在编译时生成元对象代码,调用路径优化较好。
invokeMethod:依赖运行时反射查找方法,效率略低(但对大多数应用影响不大)。
线程间通信原理
两者的底层均依赖Qt的事件循环:
信号槽:通过QMetaCallEvent将调用请求加入接收线程的事件队列。
invokeMethod:直接生成事件并投递到目标线程。
在UI更新场景中,推荐优先使用信号槽机制,仅在需要动态调用或同步阻塞时选择QMetaObject::invokeMethod。
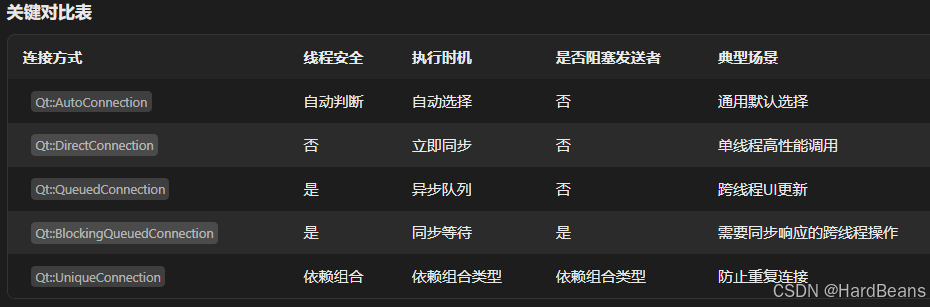
连接方式
- Qt::QueuedConnection 异步队列(多线程用)也可实现同一线程异步
- Qt::DirectConnection 直接连接(同一线程用)
- Qt::BlockingQueuedConnection(阻塞队列连接) 等待槽函数执行完成
跨线程传递参数:
- Q_DECLARE_METATYPE(MyDataType) // 头文件声明
- qRegisterMetaType(“MyDataType”); // 运行时注册
问题4 一个并发批量ringbuffer
#pragma once
#include <cstring>
#include <qglobal.h>
#include <qmutex.h>
#include <qobject.h>
#include <qobjectdefs.h>
#include <qsemaphore.h>
#include <qvector.h>
template <typename T>
class RingBuffer : public QObject
{
Q_OBJECT
public:
RingBuffer(size_t capacity = 1024, QObject* parent = nullptr)
:QObject{ parent },
m_capacity(capacity),
m_buffer(capacity),
m_head(0),
m_tail(0),
m_freeSize(capacity),
m_usedSize(0),
m_freeSpace(capacity),
m_usedSpace(0)
{
Q_ASSERT_X((capacity & (capacity - 1)) == 0,
"RingBuffer", "Capacity must be power of two");
}
// 批量写入(线程安全)
size_t batchWrite(const T* data, size_t count) {
QMutexLocker locker(&m_mutex);
const size_t freeSize = m_freeSize;
// const size_t writeCount = qMin(count, freeSize); // 本次写入的数量,取最小值,防止覆盖,但本处需要可以覆盖。
const size_t writeCount = count; // 不判断是否覆盖,直接写入
//const size_t available = m_freeSpace.available();
//const size_t writeCount = qMin(count, available);
if (writeCount == 0) return 0;
// 分两段拷贝处理缓冲区回绕
const size_t firstChunk = qMin(writeCount, m_capacity - (m_tail & (m_capacity - 1)));
const size_t secondChunk = writeCount - firstChunk;
std::memcpy(m_buffer.data() + (m_tail & (m_capacity - 1)), data, firstChunk * sizeof(T));
if (secondChunk > 0) {
std::memcpy(m_buffer.data(), data + firstChunk, secondChunk * sizeof(T));
}
m_tail += writeCount;
m_usedSize += writeCount;
m_freeSize -= writeCount;
//m_usedSpace.release(writeCount);
//m_freeSpace.acquire(writeCount);
return writeCount;
}
// 批量读取(线程安全)
size_t batchRead(T* output, size_t count) {
QMutexLocker locker(&m_mutex);
const size_t available = m_usedSpace.available();
const size_t readCount = qMin(count, available);
if (readCount == 0) return 0;
// 分两段拷贝处理缓冲区回绕
const size_t firstChunk = qMin(readCount, m_capacity - (m_head & (m_capacity - 1)));
const size_t secondChunk = readCount - firstChunk;
std::memcpy(output, m_buffer.data() + (m_head & (m_capacity - 1)), firstChunk * sizeof(T));
if (secondChunk > 0) {
std::memcpy(output + firstChunk, m_buffer.data(), secondChunk * sizeof(T));
}
m_head += readCount;
m_freeSpace.release(readCount);
m_usedSpace.acquire(readCount);
return readCount;
}
// 获取可用数据量(原子操作)
size_t available() const {
return m_usedSpace.available();
}
private:
const size_t m_capacity;
QVector<T> m_buffer;
size_t m_head; // 读取位置
size_t m_tail; // 写入位置
QSemaphore m_freeSpace; // 空闲空间信号量
QSemaphore m_usedSpace; // 已用空间信号量
size_t m_freeSize;
size_t m_usedSize;
QMutex m_mutex; // 互斥锁
};



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











