







 本文详细介绍了数据库管理系统中关于元组、记录的概念及其转换,包括元组的临时性和记录的持久性。讨论了记录到元组的转化过程,并列举了不同类型的记录编码方式。还探讨了在PostgreSQL中的元组结构,包括元组头信息和数据存储。此外,文章还涉及了关系操作、成本模型,以及不同操作如插入、删除的代价分析。
本文详细介绍了数据库管理系统中关于元组、记录的概念及其转换,包括元组的临时性和记录的持久性。讨论了记录到元组的转化过程,并列举了不同类型的记录编码方式。还探讨了在PostgreSQL中的元组结构,包括元组头信息和数据存储。此外,文章还涉及了关系操作、成本模型,以及不同操作如插入、删除的代价分析。
Tuples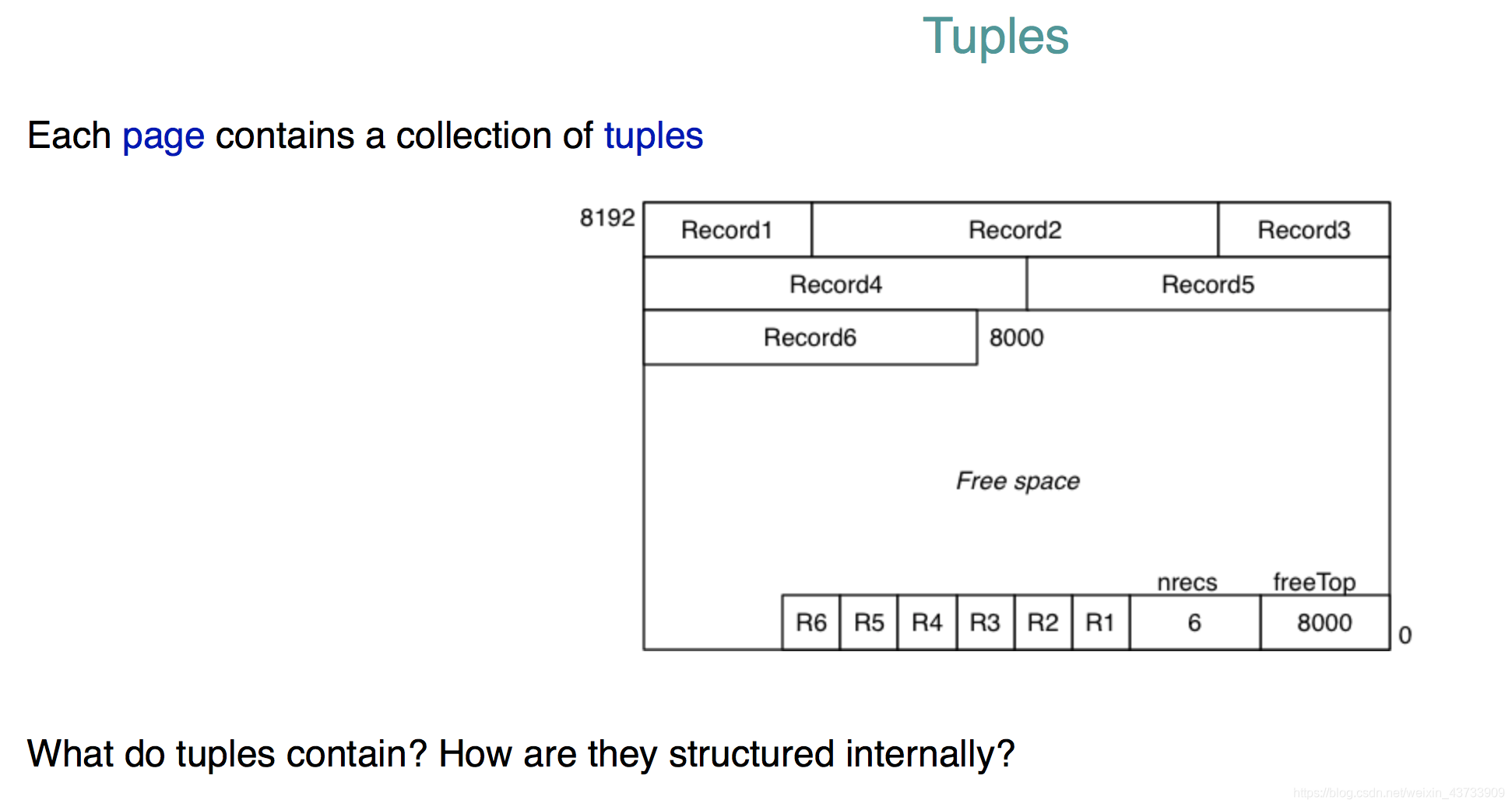

以上信息存在schema.sql。

Tuples是一个schema上属性值的集合,Record则是tuple上data的对应的一串bytes。
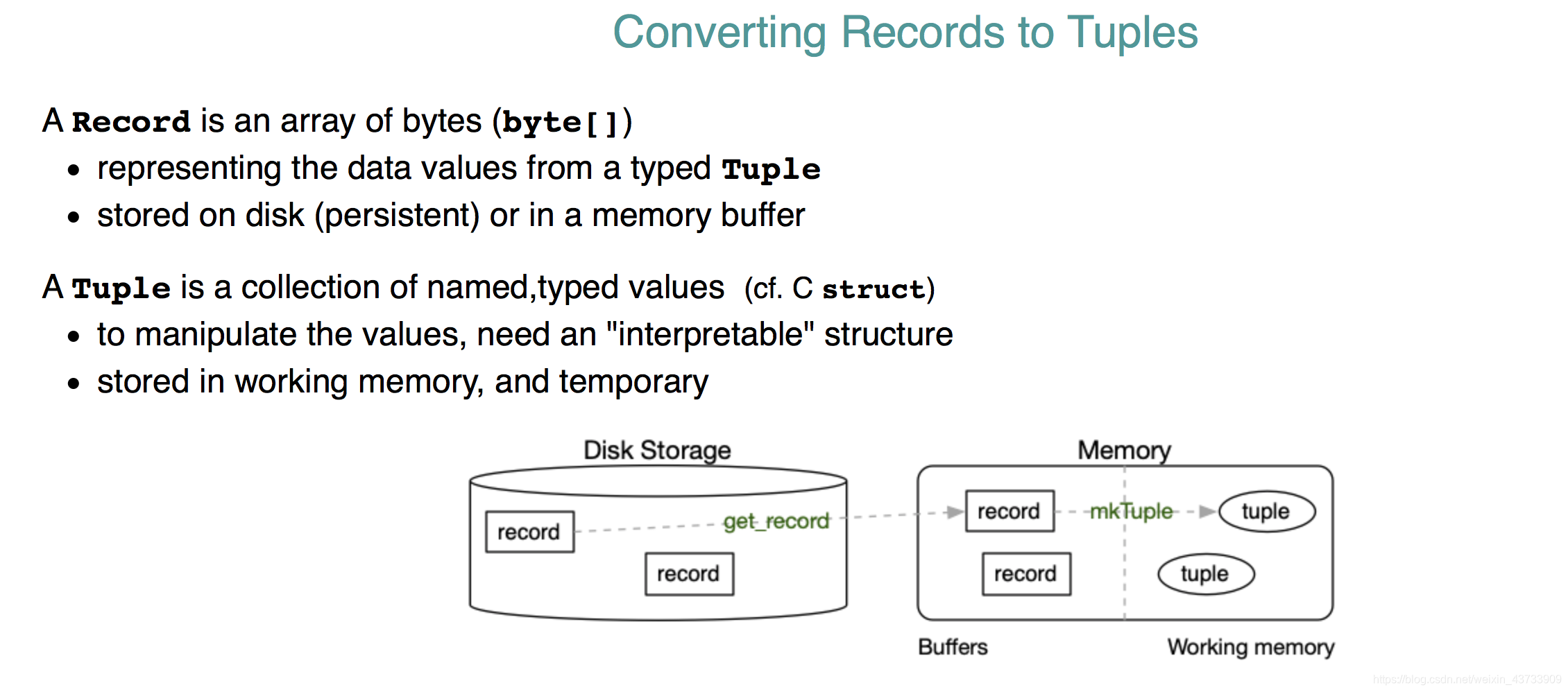
Record既存在在Disk中也存在在Buffers中。当读一个8K page(get_record)时,一些record对应在buffers中。Records需要在working memory里将其转化为tuple。(mkTuple).
Tuple是临时的,而Disk里的record是永久的。

Record转化为Tuple的信息:
1.可能显示在catalog文件里的meta-data。
2.可能存在于page directory。
3.可能存在于record自身(比如在header中)。
4.可能部分存在于record,部分存在于schema,部分存在于page header。
对于可变长度的record,一些format成tuple的信息必须存于record本身(通常情况下)或者page directory中。至少需要知道它的值占多少bytes。
Operations on Records
从Disk中获得record:
Record get_record(Relation rel, RecordId rid){
(pid,tid)=rid;
Page *buf = request_page(rel,pid);
return get_bytes(rel,buf,tid);
}
不太能直接用record,需要一个tuple
Relation rel = ... //relation schema
Record rec = get_record(rel, rid)
Tuple t = mkTuple(rel, rec)
一旦我们获得了tuple,就可以获取单个的attribute。

一旦得到了tuple,我们想继续得到它的filed,也就是它对应类型的值。
eg. x= getIntField(t,l), char *s = getStrField(t,2)
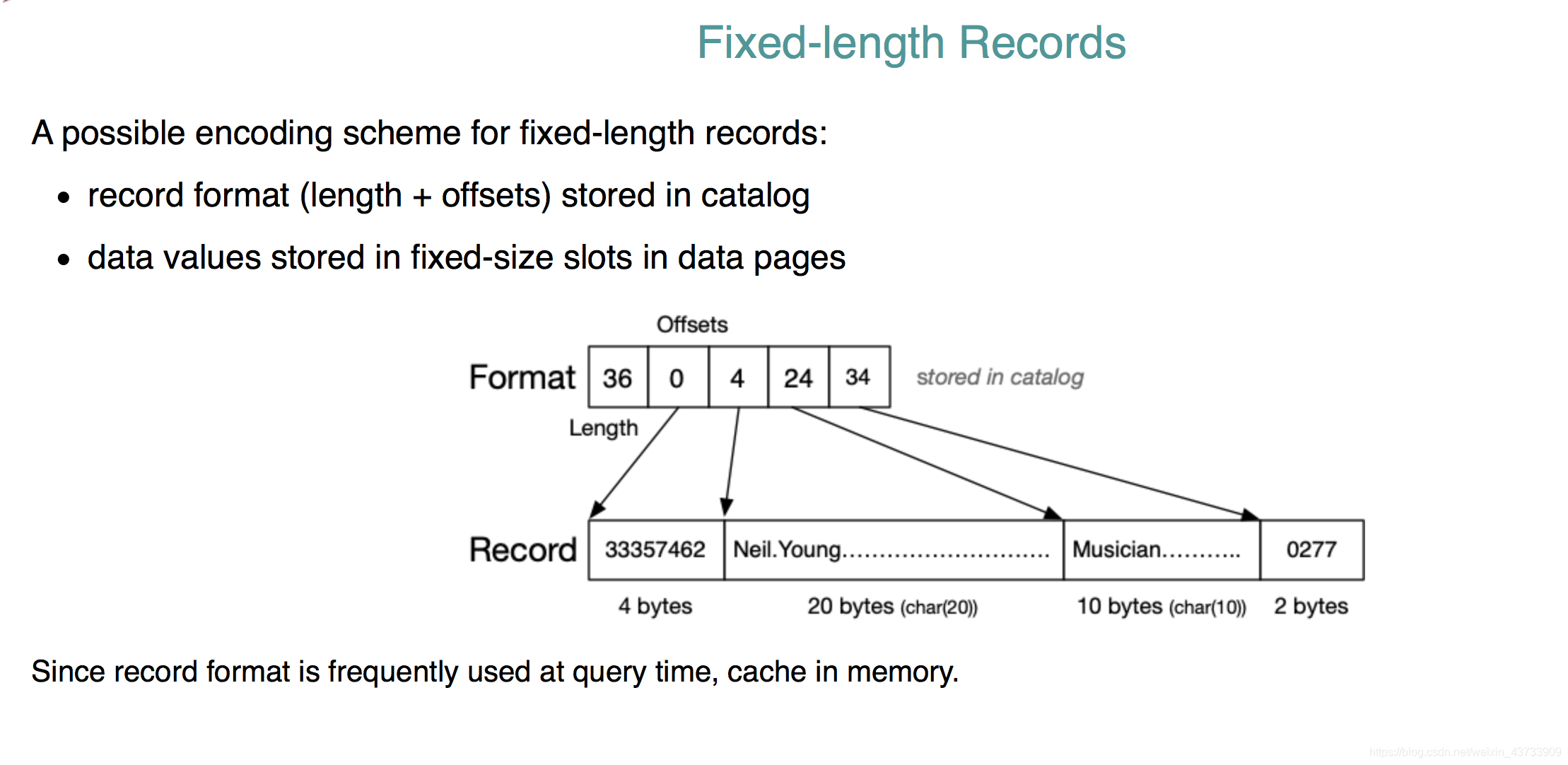
固定长度的record的meta-data编码:
1.在catalog中保存record format(length+offset)
2.data值保存在data pages中固定长度的slots中。
在同一个relation里,record有相同的size。varchar->char.
我们在初始时填0. 所以实际上getStrField(t,2)返回的是20bytes+’/0’=21bytes。
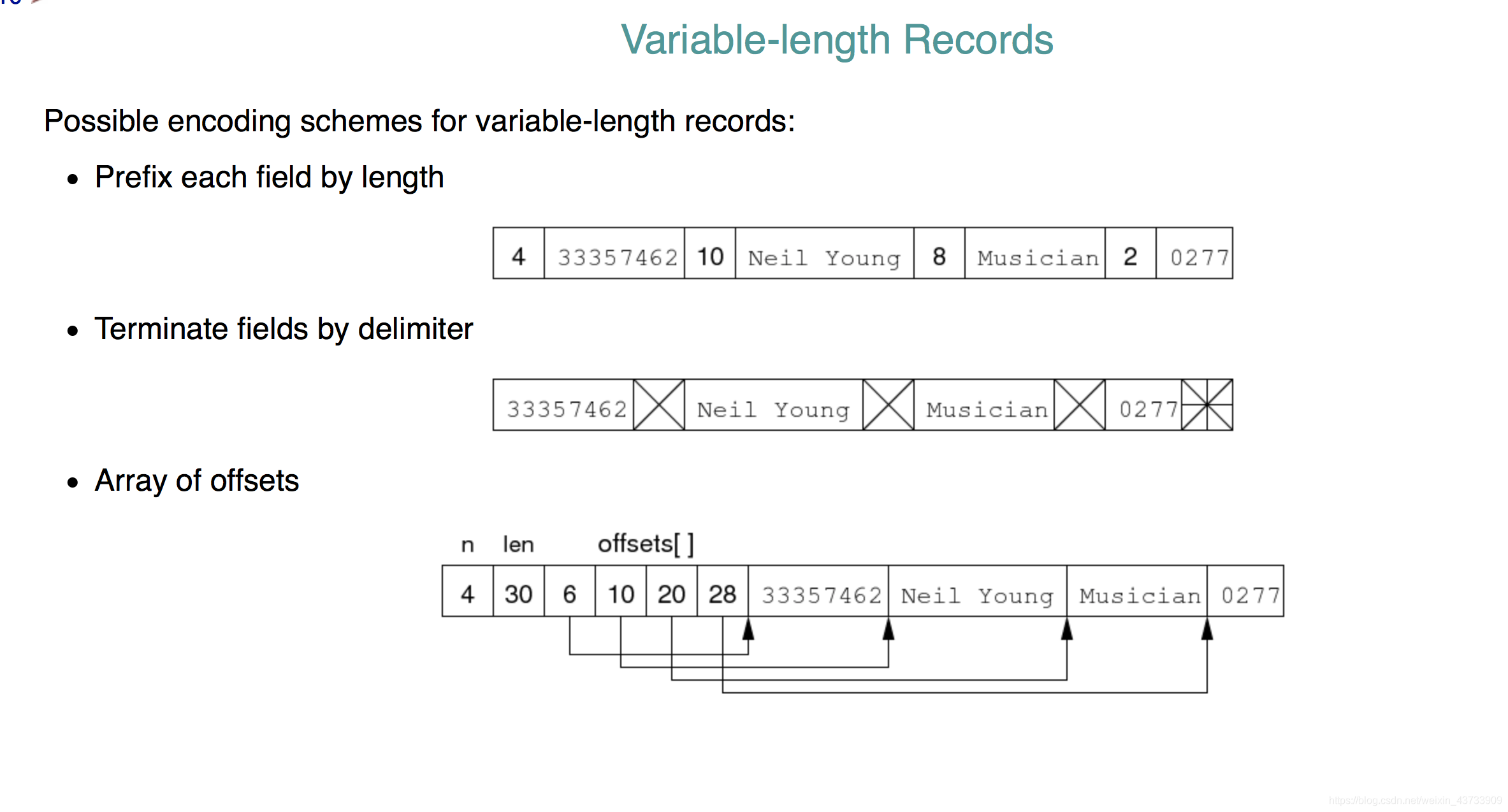
对于可变的records,有3种方式编码:
1.每个field(属性)的长度作为前缀。
2.delimiter作为终止field。(比如全是1的bytes)
3. offsets的数组。(有一个包含offset信息的header)



PSQL使用的Tuple structure:
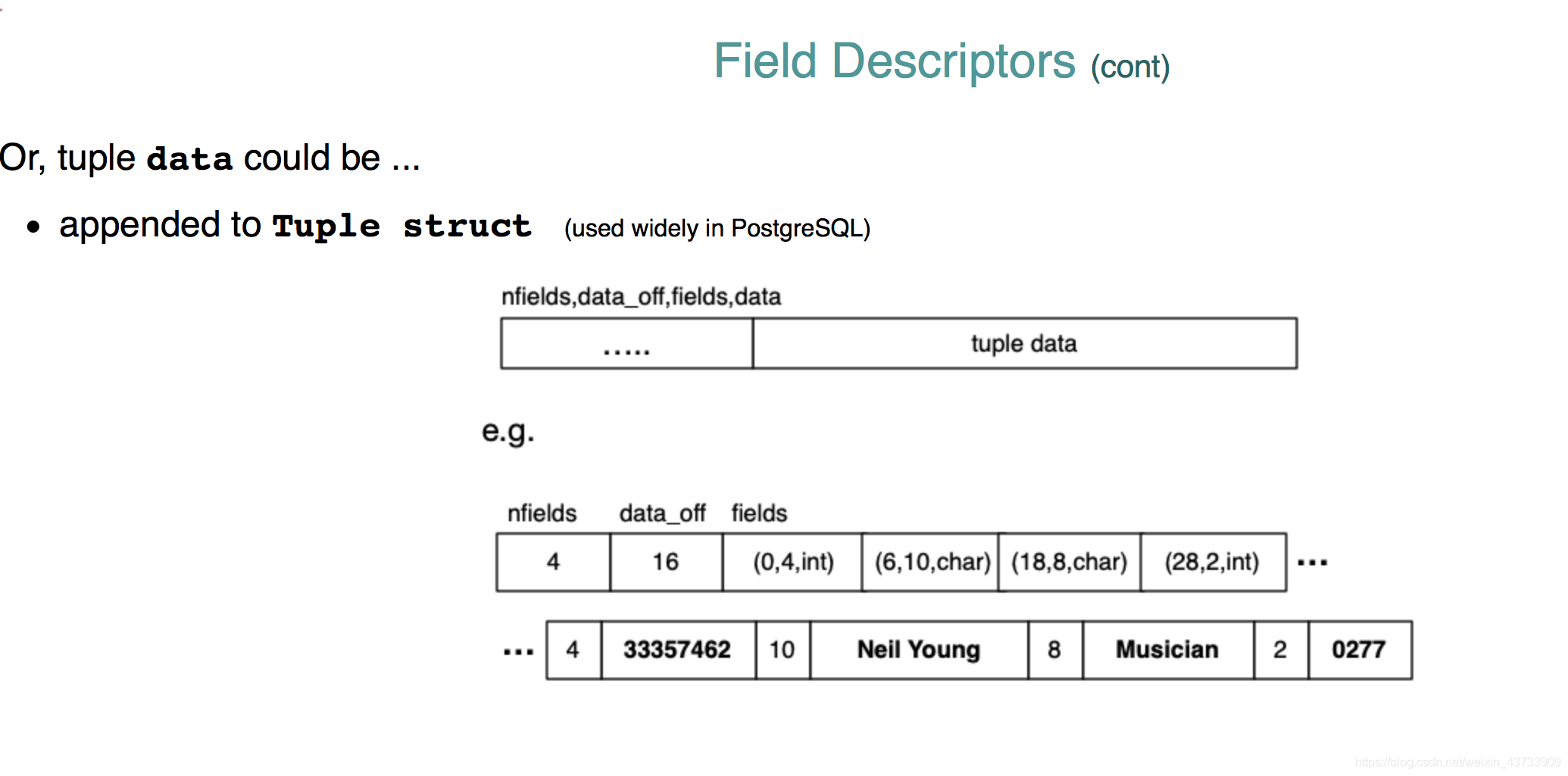
把tuple的information保存在tuple的开头,后面是tuple的data,因此这样所有的objects都存在内存中,即不需要buffers。即将在field descriptor的末尾加上一串bytes数据。

PSQL中page是8k,如果我们假设所有tuple以一个4byte 的边界开始,我们就要使用word offsets。
FieldDesc values可能是64bits = 8 bytes。
Offsets:
max offset = 8KB-1
表示所有offsets的bits数量 = 13—>2^13=8K
当用word offset时,我们知道开始的bytes是被四整除的,所以我们可以将用11bits来表示。
Length:
对于每个attribute的长度,大约是11bits,即最大是2^11=2K.
如果attribute的值保存在data file之外,比如大的数据,attribute就保存一个其他页的reference(类似于recordID),则attribute的长度就是固定的。
for large variable length attires = store record id = 32 bits
FieldDesc
Types:
我们保存oid of pg_type tuples, oid是32bits长。

PSQL里使用heap_form_tuple(desc, values[], isnull[]),而不是maketuple(), 因为null不是integer,所以用另外的数组isnull[]区分来标记那些attribute的值是null。
heap_deform_tuple是用于tuple重新构造。
PSQL实现tuples通过一块连续的内存,以一个header开始(包括了#field,nulls等信息),紧跟着data的值。

每个SQL statements叫做command。Command的ID会随着table的创建和删除改变。
相同类型的tuples相互linked。当delete或update tuple时,旧的tuple会依旧存在,新的tuple被创建,然后引用旧的tuple。
一些masks告诉我们例如tuple是否有null。
hoff是data的初始的offset。
bits是NULL的bitsmap。
前四个用于multi-version concurrency control。
infomask也存在一些attribute的信息。
当HasNulls=false时,bits可能被免除,因为整个bitmap都为0.
每一个tuple都有这样一个包含以上所有的header。
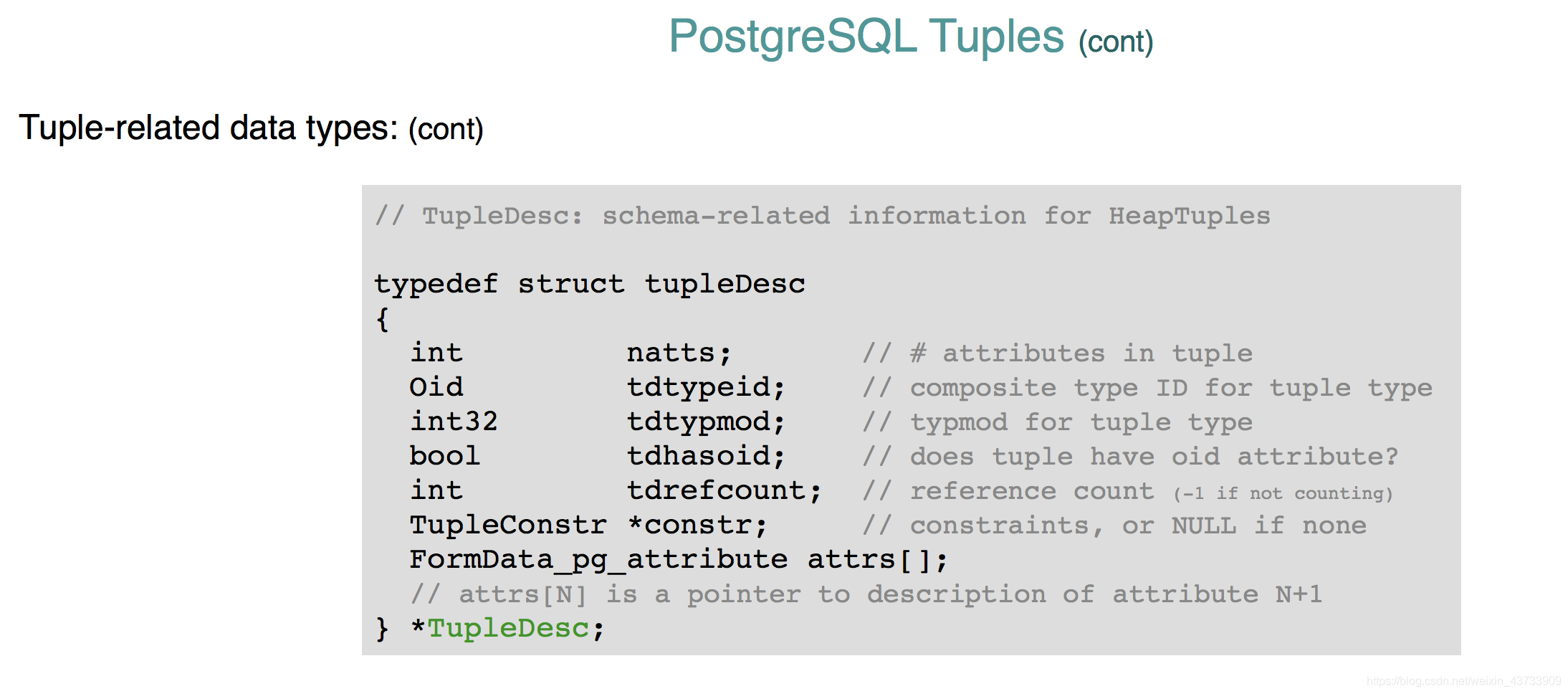
每当构建PSQL的所有statement时,也定义了tuple的type。
如果想节约空间可以删掉oid。
tdrefcount时有多少transactions正在被tuple使用。
constr是对于attribute的值的限制。
attrs[]是field descriptor,更加高效。
field descriptor的结构:
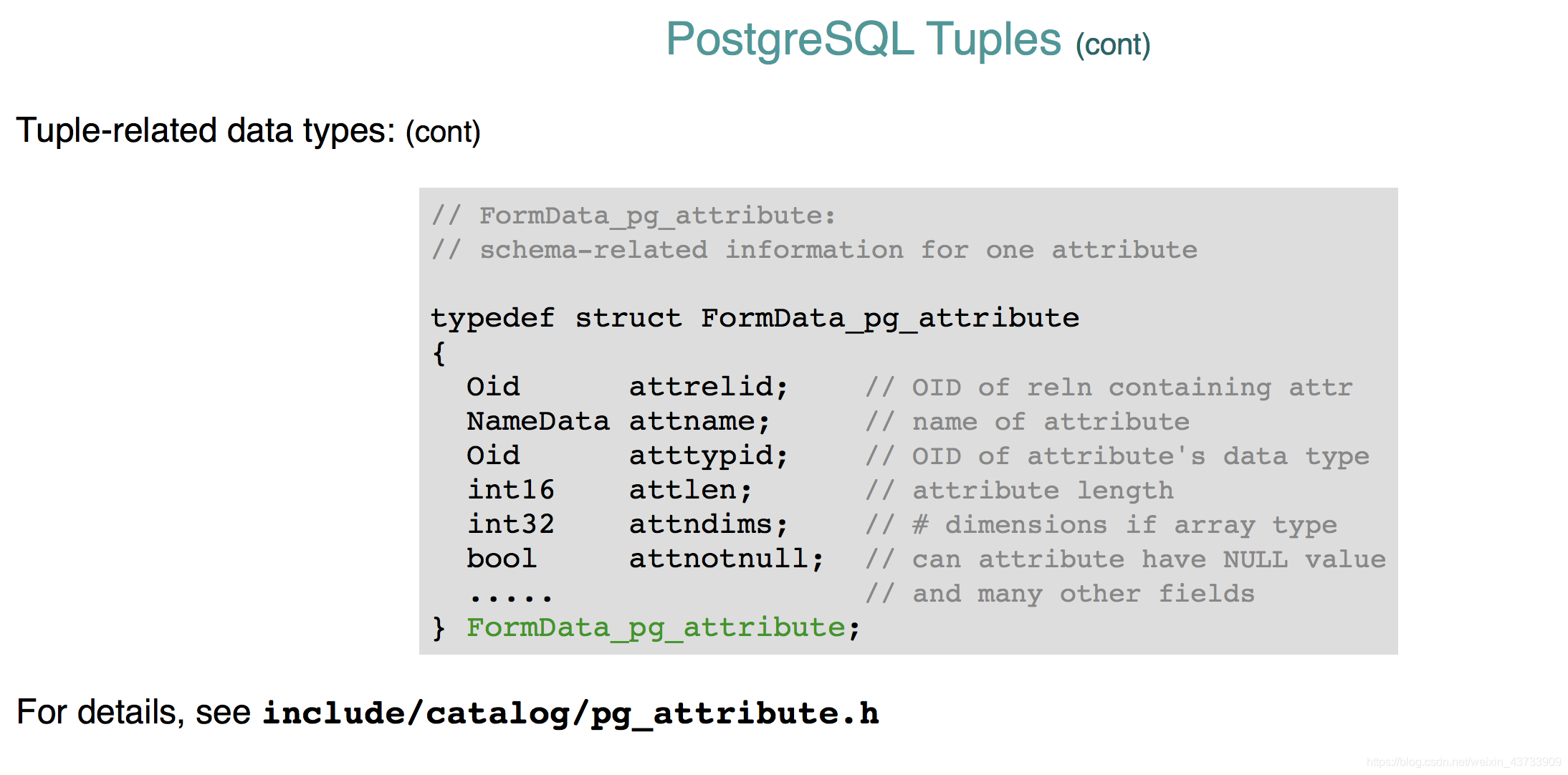
attrelid是每一个attribute的关系。
atttypid是引用type table中的类型。
attlen是attribute长度,int16代表长度是16bits,即最大是2^16 .
attndims是attribute的维度。
attnotnull是告诉是否attribute有NULL。
PSQL的tuple:

tuple的单个data block:
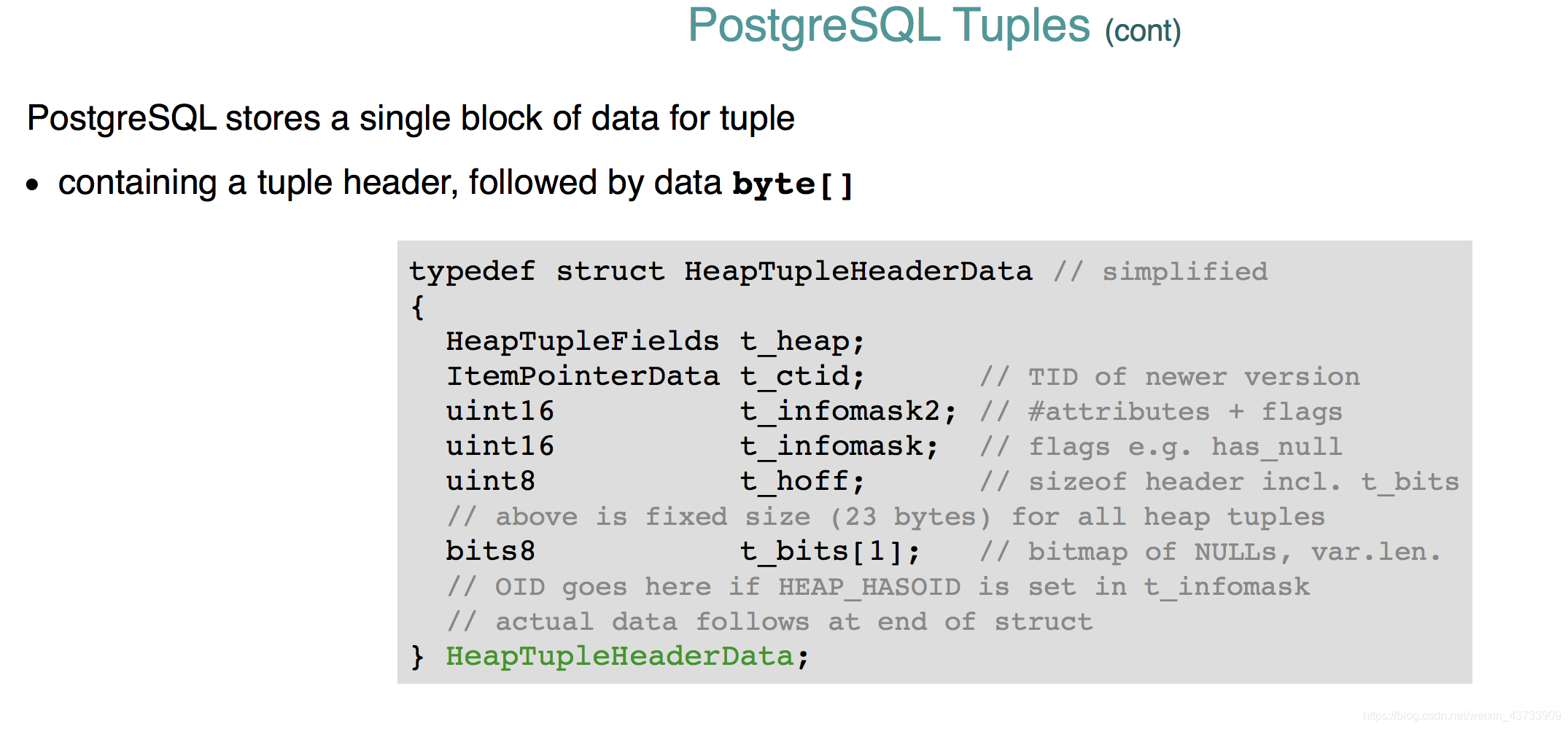
PS:t_bits[]不是总为1,根据所有属性的长度确定。
infomask中的bits:


PSQL的tuple的attribties的值打包成Datums类型:

实际的data值:
可能存在Datum中(如int)
可能header中长度信息(对于可变长度attribute)
可能存在TOAST文件中或多个文件(对于非常大的值)
PSQL从tuple中获取attributes:

因为null与其他的值类型不同,所以需要isnull作flag。
attnum可以是负数,当需要取system attributes(比如OID)时。
PSQL中Datum的操作的宏:

第一个宏是用于取包含布尔类型值的datum(field descriptor会告诉你是否包含布尔类型值)。
第二个宏用于讲布尔值打包成datum。
Relational operation
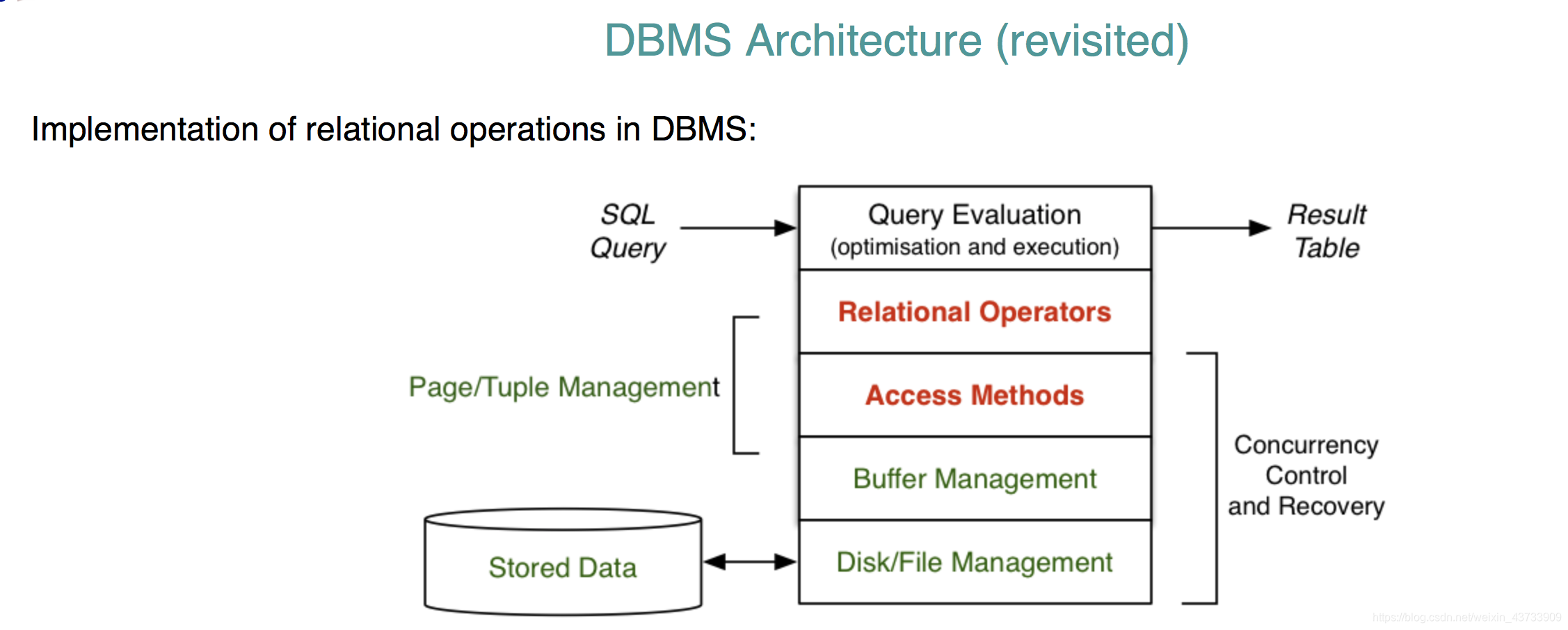

DBMS 是一个relational engine。其它的操作都是不同版本的selection。


Cost Models

在内存里获得record并将它转化为tuple代价是小的,因为是in-memory type operation。
将records放入内存代价是昂贵的。
Request Page:如果buffer里已经加载了page,则不需要做任何I/O;如果buffer没有任何page,则需要读取page,而且如果要替换的buffer被修改,需要再写入这个buffer的内容,所以这需要2个I/O操作。I/O操作非常耗时。

如果page 不在memory buffer里第一次query的时候比较慢。
之后的时间会大致相同。(因为PSQL的“timing”是sampling的)。
但我们计算时先忽略buffer。

一个relation是一些page集合,page包含了一些records。


Scan query是读取一个table中的所有的tuples。
Proj也是读取一个table中的所有的tuples,但只提取tuple的attribute的子集。
Sort:通过order by实现。
第一个selection保证给我们一个最多一个结果(selection on primary key)。
第二个selection的条件可以是相等,大于或小于,会返回多个结果。通过tuple的分布可以得到大约多少个结果。
Join:一个table中tuple与其他table中的tuple在某个地方一一对应合并。
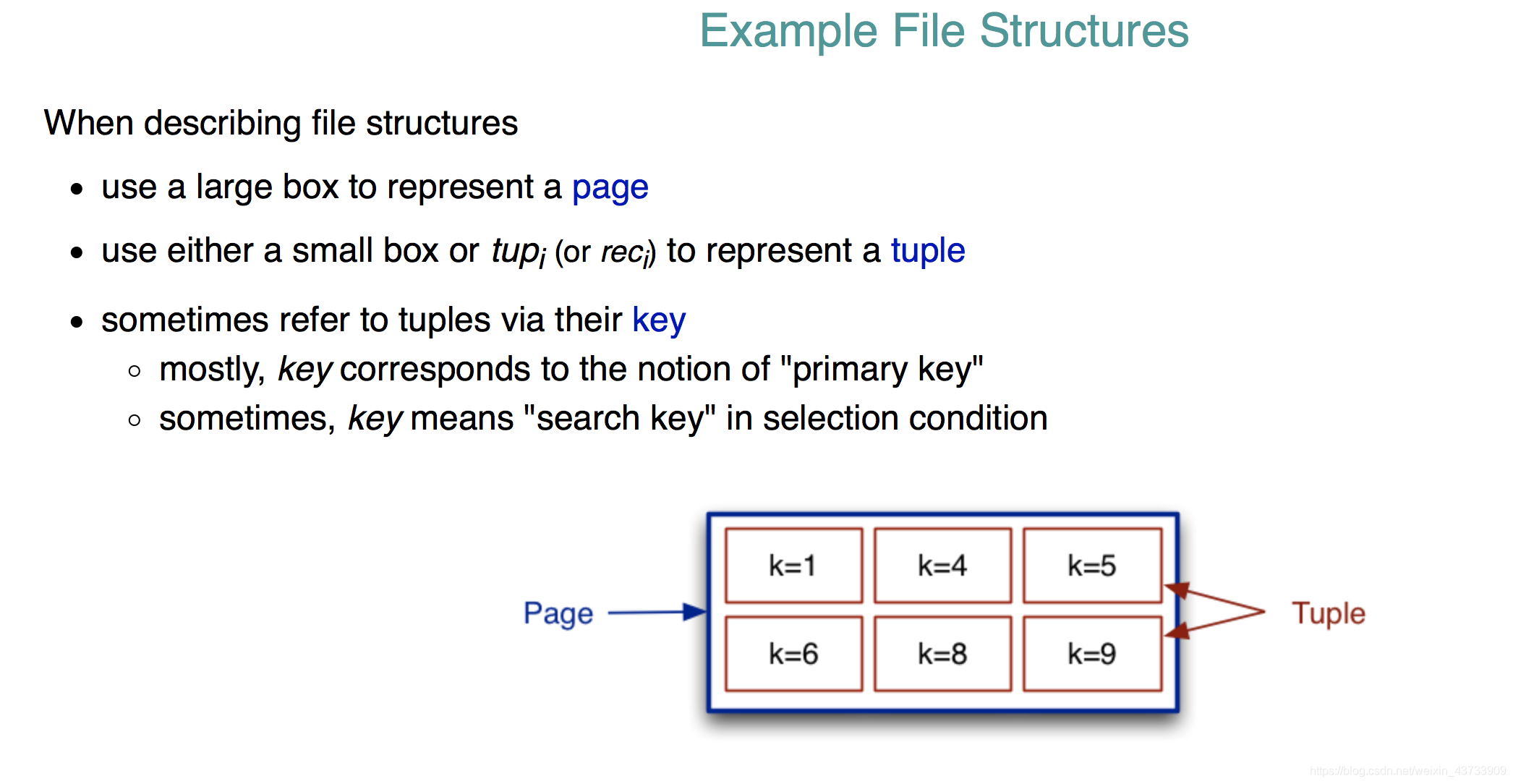
Scan所有的tuples并检查k的值相对于(首次)read page代价是微不足道的。

3个基本的文件结构:
1.heap file----> tuples 添加到有空间的page上
2.sorted file----> tuples在文件中以key order排序
3.hash file-----> tuples 根据hash function 放入pages中。
PSQL所有的都是heap file,不考虑顺序。

r: tuples的总数
R:tuples的平均size
b:pages的总数
B:每个page的size
c:capacity
file header告诉我们下一个有空间的page在哪。
各个操作的代价:
Insert from heap:

我们已经知道了header page ,读取下一个有空余空间的page,检查table是否符合page的剩余空间大小,如果是,则插入到page中,修改page的header(比如其中的R属性)并写回。如果填完了不够,没有下一个时,则另创建一个空页再加入tuple,更新header并写回。
总体来说读取并检查page,如果有空余则写入+更新header写回,无空余则新开page写入写回。则cost = 1 read+2writes。
Delete from heap:

如果只有一个匹配,扫描所有的page直到找到匹配的tuple,更新page并写回,更新header page并写回。
最好的情况:1 read + 2 writes
最坏情况:b reads + 2 writes
如果有多个匹配:
Best:b reads + 2 writes(page+header file)
worst:b reads + b writes(b个page) + 1 write (header page)
---->
b_q = number of pages containing matches
b reads + b_q writes + 1 write(header page)
(不管多少个匹配的tuple在一个page上,对于这个page我们只写一次)
insert into Sorted:
use binary search to find relevant page
可以根据page里tuple最大值和最小值来决定是否插入。
当插入之后,如果page容量超了,它后面的需要继续push到下一页,所以当很多匹配的时候不太好。---->解决办法:overflow pages。当page容量满了,则给它加一个overflow page并将溢出的tuple放入写回,再写回data page。
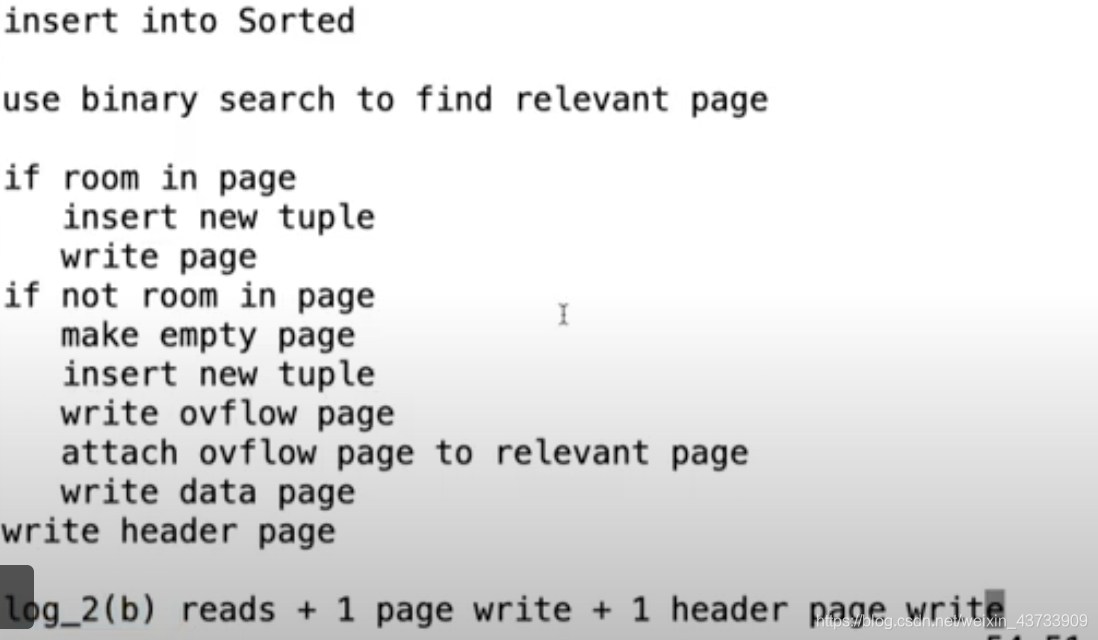
if room in page
insert new tuple
write page
if not room in page
make empty page
insert new tuple
write overflow page
attach overflow page to relevant page
write data page
write header page
当插入一个tuple:
如果page中有空余 :log2(b) reads + 1 page write + 1 header page write
如果page中没有空余:log2(b) reads + 2 page write + 1 header page write
REFERENCE
Comp9315 week4a lecture


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









