







中文名:反向传播算法
用于Gradient Descent 来train 一个neural network时用到
BackPropagation的核心是通过链式法则改变微分形式,并用forward pass 与 backward pass求出对应微分
Gradient Descent
在进行Gradient Descent 步骤的时候,我们需要计算 ∇ L \nabla L ∇L ,也就是要计算L对各个parameter的偏微分,如果我们的parameter非常多,我们的layers也比较多(例如在做语音识别模型的时候可能有7,8层)
To compute the gradients efficiently,we use backpropagation

Math premise
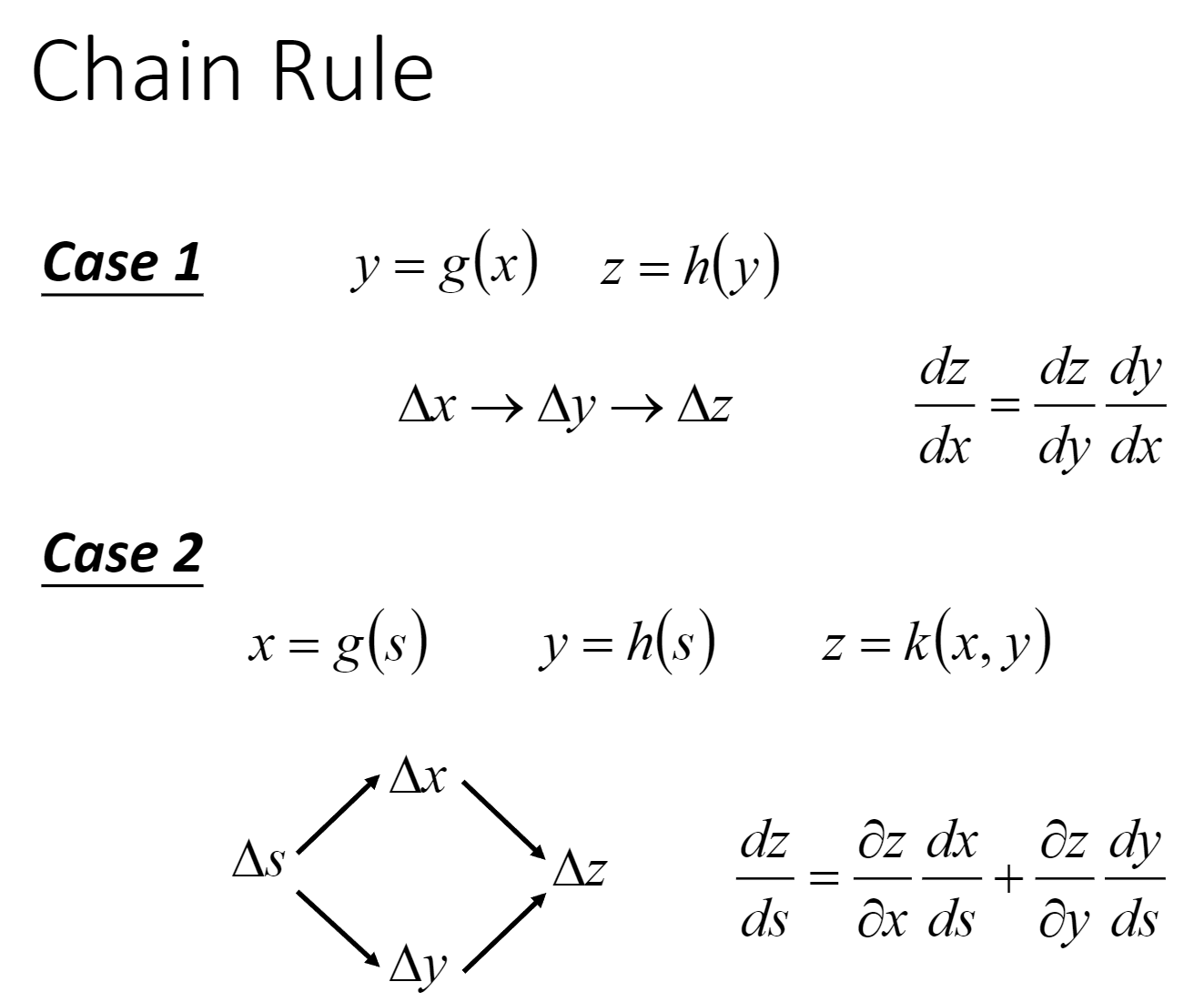
数学前置知识:Chain Rule
不懂的自行学习Calculus
Back Propagation
这里 C n C^n Cn 代表预测值 y n y^n yn 与 真实值 y ^ n \hat y^n y^n 的距离
对公式整体取偏微分可以得到右式
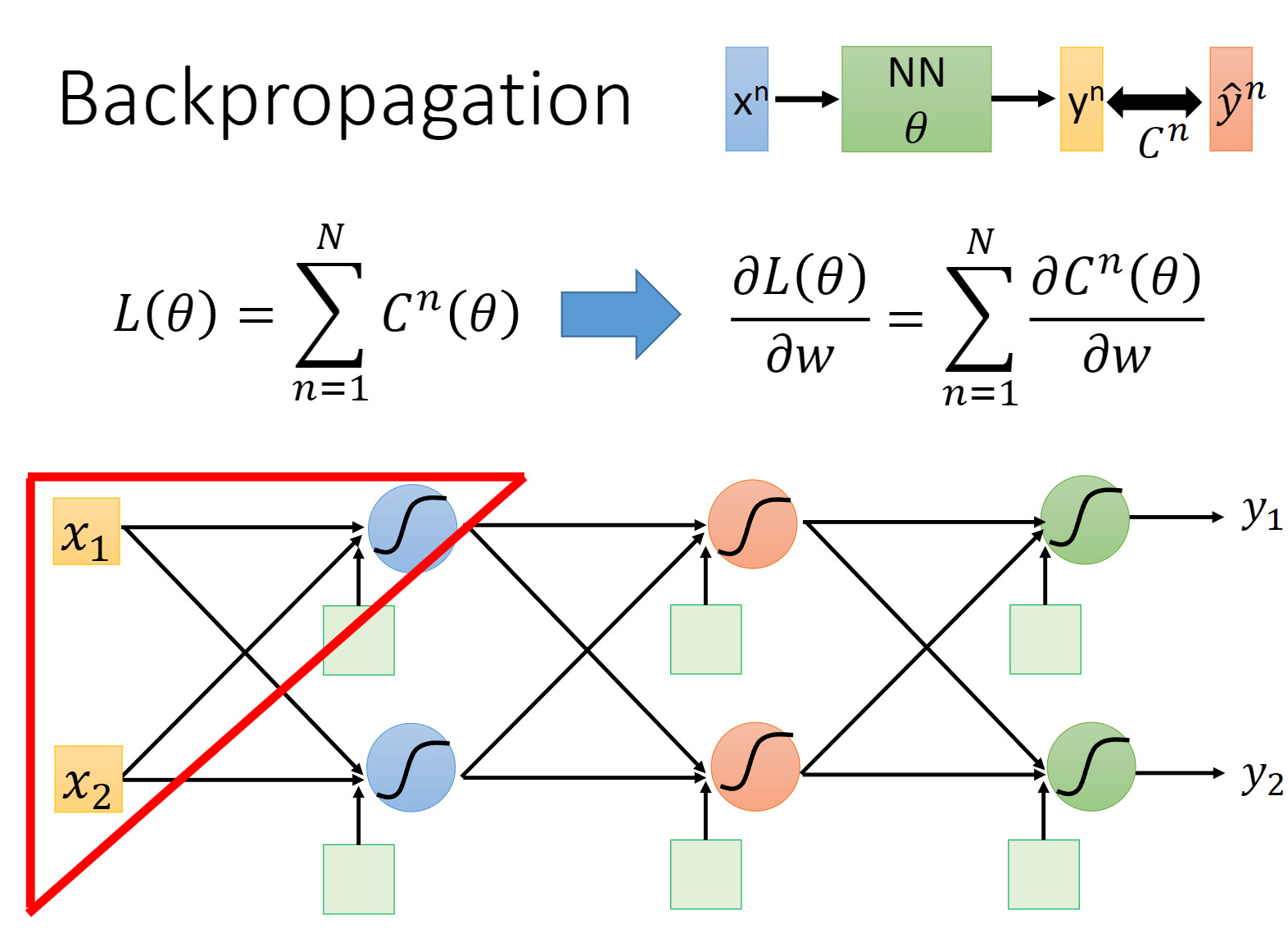
我们先取三角形中的neuron出来考虑
我们想要计算 ∂ C ∂ w \frac { \partial C } { \partial w } ∂w∂C ,根据一阶微分形式不变性可得 $\frac { \partial C } { \partial w } = \frac { \partial z } { \partial w } \frac { \partial C } { \partial z } $
我们将前面的 ∂ z ∂ w \frac {\partial z}{\partial w} ∂w∂z 称为Forward Pass:commute ∂ z ∂ w \frac {\partial z}{\partial w} ∂
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4355
4355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









