




 本文介绍如何使用beautifulsoup库从丁香园论坛抓取特定帖子的回复内容及作者信息,包括登录验证、解析HTML、提取所需数据并打印结果。
本文介绍如何使用beautifulsoup库从丁香园论坛抓取特定帖子的回复内容及作者信息,包括登录验证、解析HTML、提取所需数据并打印结果。
任务
【Task3 学习beautifulsoup】:(1天)
学习beautifulsoup,并使用beautifulsoup提取内容。
使用beautifulsoup提取下面丁香园论坛的特定帖子的所有回复内容,以及回复人的信息。
丁香园直通点:http://www.dxy.cn/bbs/thread/626626#626626
使用浏览器看到要抓取的内容
打开Chrome浏览器,输入网址,发现需要登录,才能看到更多的内容
于是注册,登录
使用cookie
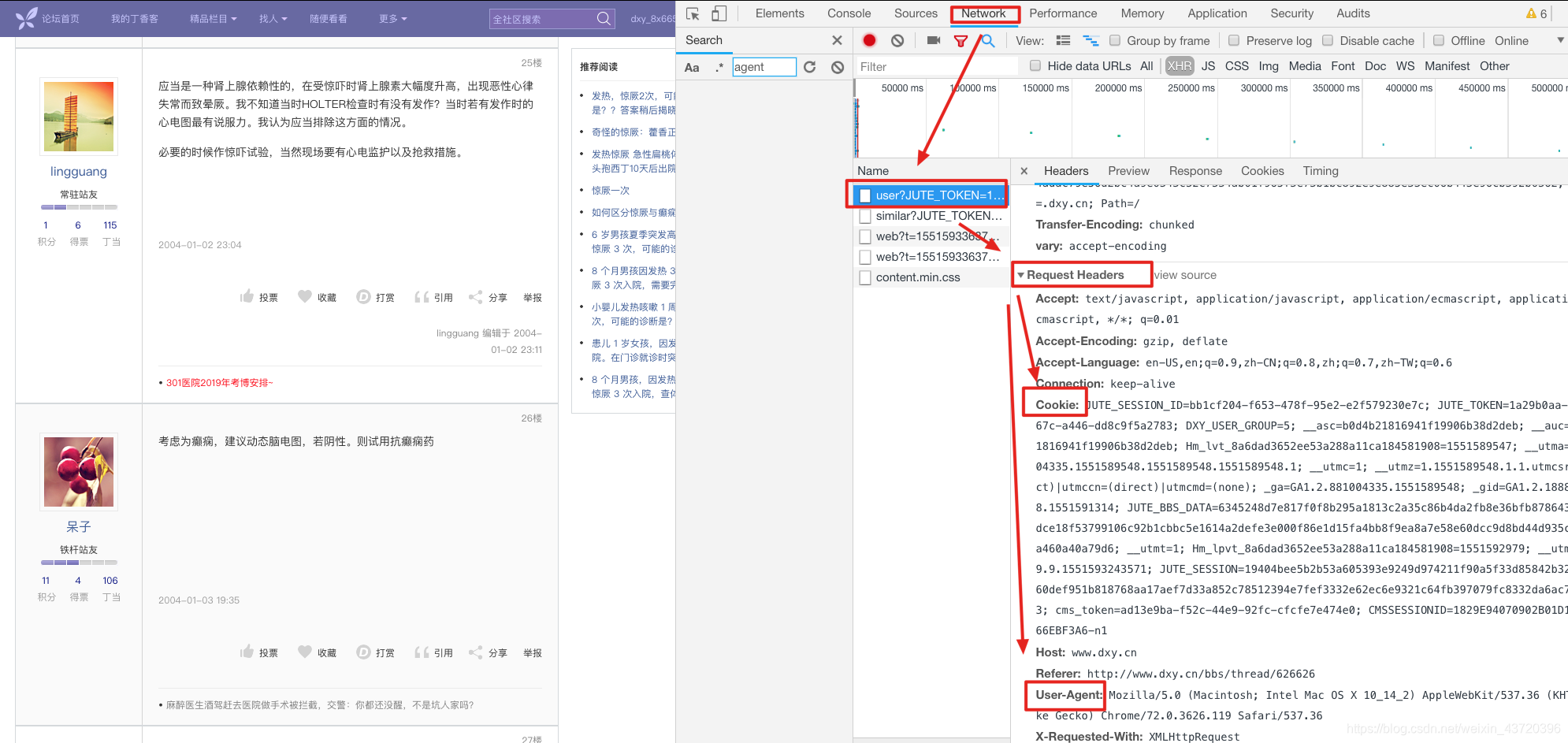
和以往访客就可以看到的页面不同,丁香园需要登录,该网站模拟已登录的状态还是比较简单的,登录后,把检查到的header复制到代码中就可以了:
我在代码中只采用了Cookie和User-Agent,没有使用其它的header:
def openurl(url):
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
cookie = 'JUTE_SESSION_ID=bb1cf204-f653-478f-95e2-e2f579230e7c; JUTE_TOKEN=1a29b0aa-d852-467c-a446-dd8c9f5a2783; cms_token=3507447d-28fa-42ad-b2c0-307891a9392f; DXY_USER...........'
headers = {'User-Agent': user_agent, 'Cookie': cookie}
try:
r = requests.get(url, headers = headers, timeout = 20)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('无法访问网页' + url)
分析结果
bs4使用select(’.xxx’)来获取特定css的内容
分析返回的HTML代码,发现作者所针对的css是auth,而回帖内容所针对的css是postbody:
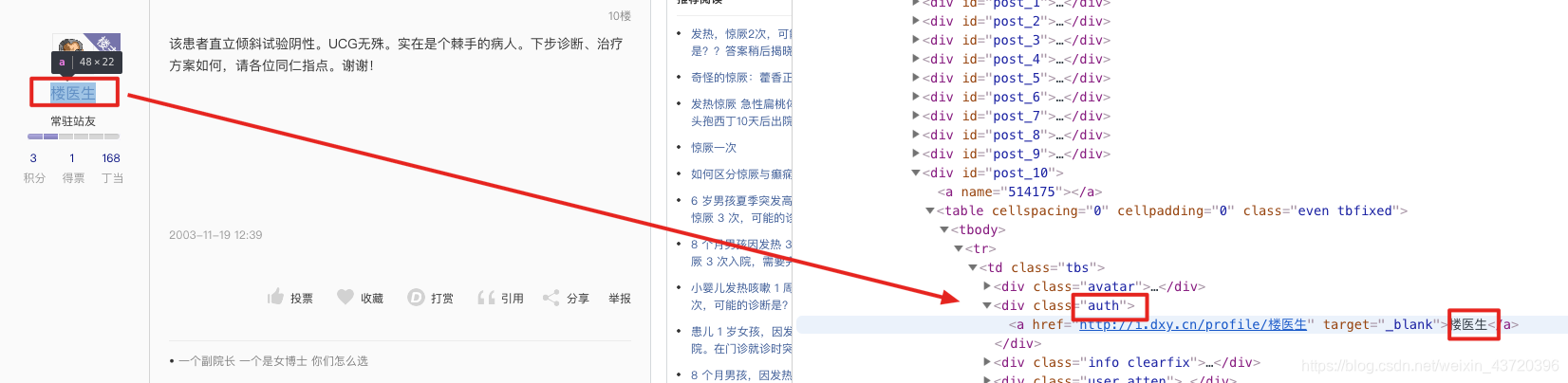

于是,采用如上代码来获取所有postbody和auth的CSS的内容(结果是列表)
data[‘replies’] = soup.select(’.postbody’)
data[‘authors’] = soup.select(’.auth’)
def get_html(response):
data = {}
soup = BeautifulSoup(response, 'html.parser')
data['title'] = soup.title.string
data['replies'] = soup.select('.postbody')
data['authors'] = soup.select('.auth')
return data
组织结果
这个比较简单,把结果打印出来:
text = open('bs4_learning.txt', 'r').read()
data = get_html(text)
print(f'Title: {data["title"]}')
replies = []
for reply in data['replies']:
replies.append(reply.text.strip())
authors = []
for author in data['authors']:
authors.append(author.text)
for i in range(len(replies)):
print(f'作者: {authors[i]} \n 回复内容: {replies[i]}')
最终结果如下:

下一步:获取内容中的图片,保存到本地
在回帖的内容中有图片,标签为img…
<img src="http://img.dxycdn.com/upload/2003/11/21/21394218.gif" class="labelImg">
今天没时间做了,先交作业,晚一些再研究一下怎么做。

















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









