




 本文介绍了一次使用Python的Selenium和BeautifulSoup库进行丁香园论坛爬虫的实战经验,包括模拟登录、抓取论坛人员基本信息及回复帖子内容的过程。
本文介绍了一次使用Python的Selenium和BeautifulSoup库进行丁香园论坛爬虫的实战经验,包括模拟登录、抓取论坛人员基本信息及回复帖子内容的过程。
任务
【Task7 实战大项目】:(1天)
实战大项目:模拟登录丁香园,并抓取论坛页面所有的人员基本信息与回复帖子内容。
丁香园论坛:http://www.dxy.cn/bbs/thread/626626#626626 。
思路
- 找到登录页面
- selenium模拟登录
- 抓取回帖内容
找到登录页面
登录网页:
https://auth.dxy.cn/accounts/login?service=http://www.dxy.cn/bbs/
browser = webdriver.Firefox()
return browser
def web_login(browser, url):
browser.get(url)
sleep(random.random()*3) #等待一段随机时间
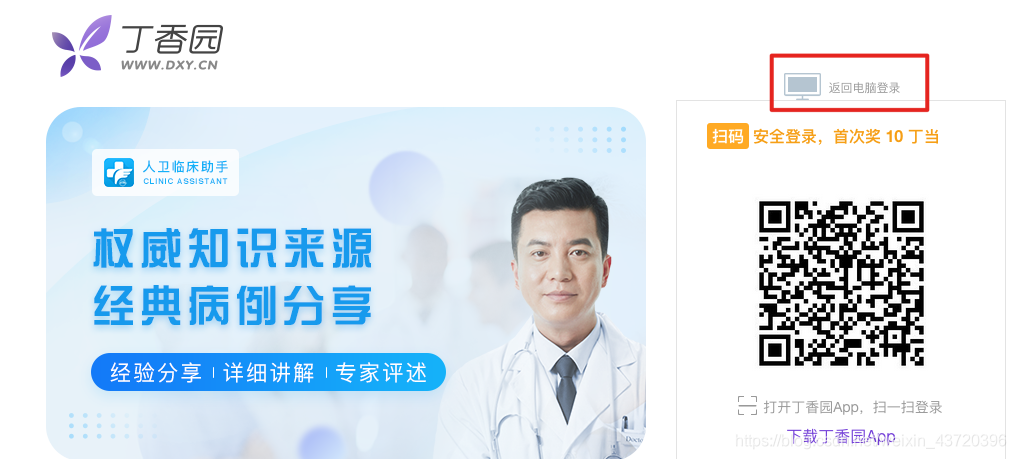
需要点击“返回电脑登录”,才会显示用户名、密码框
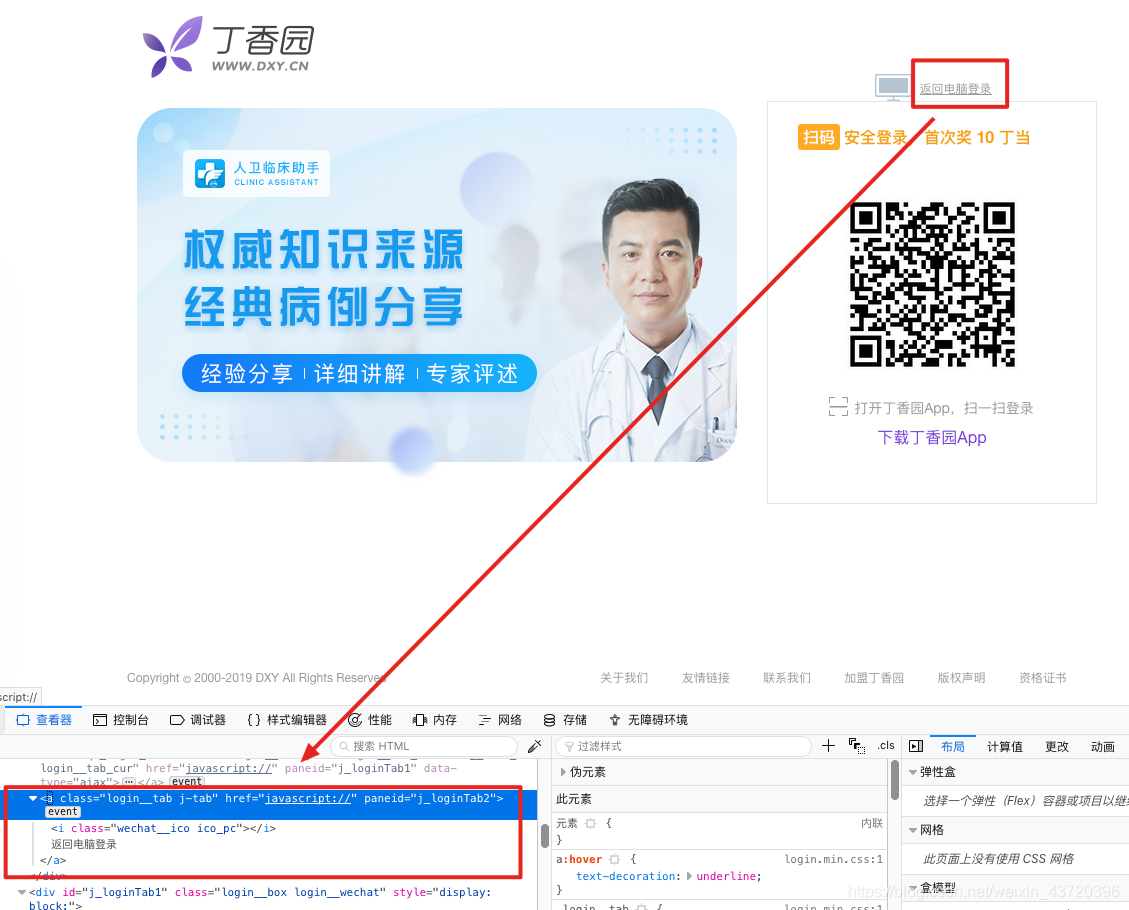
login_link = browser.find_element_by_link_text('返回电脑登录')
login_link.click()
Inspect:
继续,定位用户名、密码框:
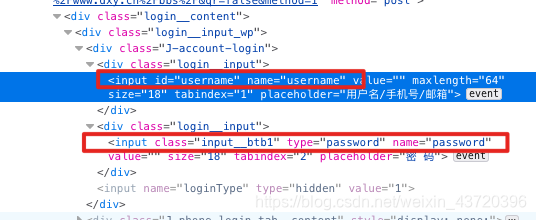
username = browser.find_element_by_name('username')
username.clear()
username.send_keys('username')
sleep(random.random()*3) # 等待一段随机时间
password = browser.find_element_by_name('password')
password.send_keys('********')
sleep(random.random()*3) # 等待一段随机时间
browser.find_element_by_class_name('button').click()
sleep(10)
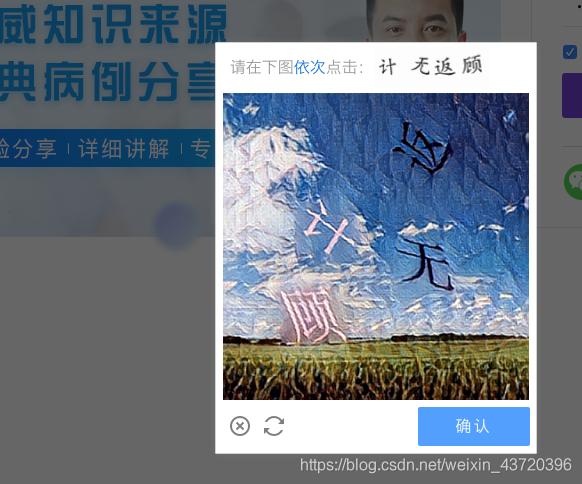
出现需要点击图片验证,搞不定,手工点击:
获取网页内容
大致参照前几天BS4的内容:
https://blog.youkuaiyun.com/weixin_43720396/article/details/88087934
def get_web_detail(browser, url):
browser.get(url)
sleep(random.random()*8) # 等待一段随机时间
data = {}
soup = BeautifulSoup(browser.page_source, 'html.parser')
data['title'] = soup.title.string
data['replies'] = soup.select('.postbody')
data['authors'] = soup.select('.auth')
return data
def show_data(data):
print(f'Title: {data["title"]}')
replies = []
for reply in data['replies']:
replies.append(reply.text.strip())
authors = []
for author in data['authors']:
authors.append(author.text)
for i in range(len(replies)):
print(f'作者: {authors[i]} \n 回复内容: {replies[i]}')
可以得到以下结果

全部代码如下:
from selenium import webdriver
from time import sleep
import random
from bs4 import BeautifulSoup
import json
def open():
browser = webdriver.Firefox()
# browser = webdriver.Chrome()
return browser
def web_login(browser, url):
browser.get(url)
sleep(random.random()*3) # 等待一段随机时间
login_link = browser.find_element_by_link_text('返回电脑登录')
login_link.click()
sleep(random.random()*3) # 等待一段随机时间
username = browser.find_element_by_name('username')
username.clear()
username.send_keys('username')
sleep(random.random()*3) # 等待一段随机时间
password = browser.find_element_by_name('password')
password.send_keys('password')
sleep(random.random()*3) # 等待一段随机时间
browser.find_element_by_class_name('button').click()
sleep(10)
cookie = browser.get_cookies()
return {i['name']: i['value'] for i in cookie}
def get_web_detail(browser, url):
browser.get(url)
sleep(random.random()*8) # 等待一段随机时间
data = {}
soup = BeautifulSoup(browser.page_source, 'html.parser')
data['title'] = soup.title.string
data['replies'] = soup.select('.postbody')
data['authors'] = soup.select('.auth')
return data
def show_data(data):
print(f'Title: {data["title"]}')
replies = []
for reply in data['replies']:
replies.append(reply.text.strip())
authors = []
for author in data['authors']:
authors.append(author.text)
for i in range(len(replies)):
print(f'作者: {authors[i]} \n 回复内容: {replies[i]}')
def main():
browser = open()
web_login(browser, login_url)
data = get_web_detail(browser, url)
show_data(data)
if __name__ == '__main__':
login_url = 'https://auth.dxy.cn/accounts/login'
url = 'http://www.dxy.cn/bbs/thread/626626# 626626'
main()

















 41
41

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









