






 本文深入探讨SparkSession与SparkApplication的区别,解析RDD、Dataset和DataFrame的概念及其演进过程。重点对比createOrReplaceTempView与createGlobalTempView的使用场景,并通过示例代码展示两者的生命周期管理。
本文深入探讨SparkSession与SparkApplication的区别,解析RDD、Dataset和DataFrame的概念及其演进过程。重点对比createOrReplaceTempView与createGlobalTempView的使用场景,并通过示例代码展示两者的生命周期管理。
在讲解 createOrReplaceTempView 和createGlobalTempView的区别前,先了解下Spark Application 和 Spark Session区别
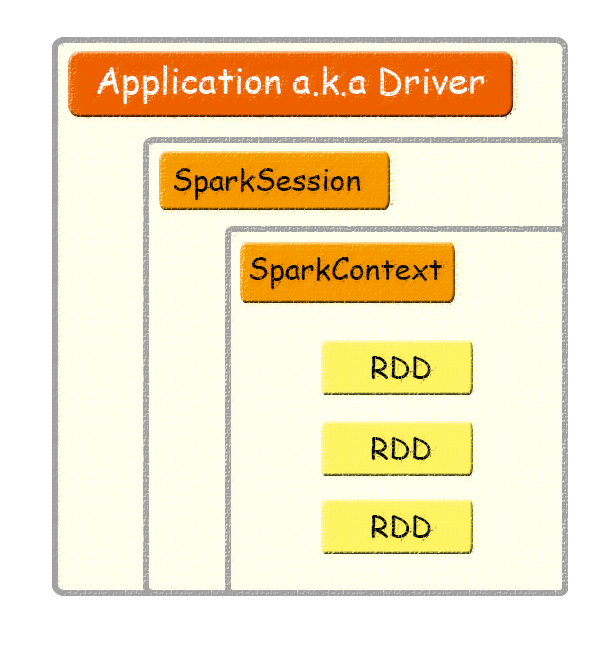
关系明细
一个Appliction可以包含多个SparkSession,但是一个Appliction只能有一个SparkContext,RDD是Spark计算的最小单元
Spark Application
用户编写的Spark应用程序,Driver 即运行上述 Application 的 main() 函数并且创建 SparkContext。
针对单个批处理作业
多个job通过session交互式
不断满足请求的,长期存在的server
一个Spark job 可以包含多个map和reduce
Spark Application 可以包含多个session实例
Spark Session
SparkSession与Spark应用程序相关联:
session 是两个或更多实体之间的交互媒介
在Spark 2.0中,你可以使用SparkSession创建
可以在不创建SparkConf,SparkContext或SQLContext的情况下创建SparkSession(它们封装在SparkSession中)
SparkContext
整个应用的上下文,控制应用的生命周期。
RDD
不可变的数据集合,可由 SparkContext 创建,是 Spark 的基本计算单元。
createOrReplaceTempView使用
createOrReplaceTempView:创建临时视图,此视图的生命周期与用于创建此数据集的[SparkSession]相关联。
createGlobalTempView:创建全局临时视图,此时图的生命周期与Spark Application绑定。
df.createOrReplaceTempView(“tempViewName”)
df.createGlobalTempView(“tempViewName”)
createOrReplaceTempView(): 创建或替换本地临时视图。
此视图的生命周期依赖于SparkSession类,如果想drop此视图可采用dropTempView删除
spark.catalog.dropTempView(“tempViewName”)
或者 stop() 来停掉 session
self.ss = SparkSession(sc)
…
self.ss.stop()
createGlobalTempView使用
createGlobalTempView():创建全局临时视图。
这种视图的生命周期取决于spark application本身。如果想drop此视图可采用dropGlobalTempView删除
spark.catalog.dropGlobalTempView(“tempViewName”)
或者stop() 将停止
ss = SparkContext(conf=conf, …)
…
ss.stop()
注:Spark 2.1.0版本中引入了Global temporary views 。
当您希望在不同sessions 之间共享数据并保持活动直到application结束时,此功能非常有用。
为了说明createTempView和createGlobalTempView的用法,展现实例如下:
object NewSessionApp {
def main(args: Array[String]): Unit = {
val logFile = "data/README.md" // Should be some file on your system
val spark = SparkSession.
builder.
appName("Simple Application").
master("local").
getOrCreate()
val logData = spark.read.textFile(logFile).cache()
logData.createGlobalTempView("logdata")
spark.range(1).createTempView("foo")
// within the same session the foo table exists
println("""spark.catalog.tableExists("foo") = """ + spark.catalog.tableExists("foo"))
//spark.catalog.tableExists("foo") = true
// for a new session the foo table does not exists
val newSpark = spark.newSession
println("""newSpark.catalog.tableExists("foo") = """ + newSpark.catalog.tableExists("foo"))
//newSpark.catalog.tableExists("foo") = false
//both session can access the logdata table
spark.sql("SELECT * FROM global_temp.logdata").show()
newSpark.sql("SELECT * FROM global_temp.logdata").show()
spark.stop()
}
}
RDD的拓展
上面提到了 Dataset 和 DataFrame,这两者概念是 RDD 的演化版本,图表说明了它们的演进过程和主要区别:
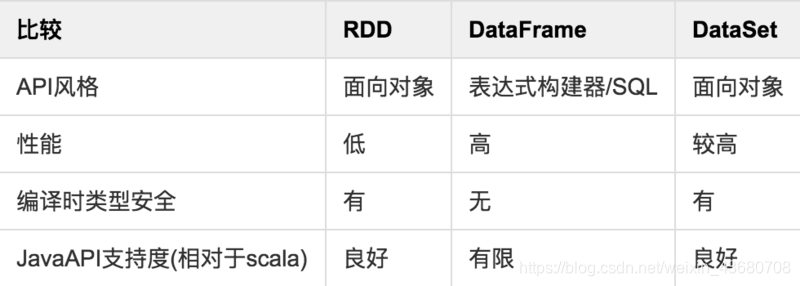
另外 Spark 的设计本身并不支持跨应用共享RDD,想要共享数据可采取以下3种方式:
1.从外部存取
2.使用 Global Temporary View
3.Ignite提供了一个Spark RDD抽象的实现,他可以在内存中跨越多个Spark作业容易地共享状态
hive on spark 与sparkSql的区别
https://www.cnblogs.com/lixiaochun/p/9446350.html

















 1612
1612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









