







文章目录
一、数据集
本次数据集是金融数据,做的是预测贷款用户是否会逾期。一共有89个特征,表格中 “status” 是结果标签:0表示未逾期,1表示逾期。部分数据集如下:
对数据进行处理:数据类型的分析、无关特征删除、数据类型转换、确失值处理
二、数据分析
1. 数据分析
1.1查看数据类型
import pandas
data = pandas.read_csv("data.csv",encoding='gbk')
# data.head(5)
data.describe()
输出:
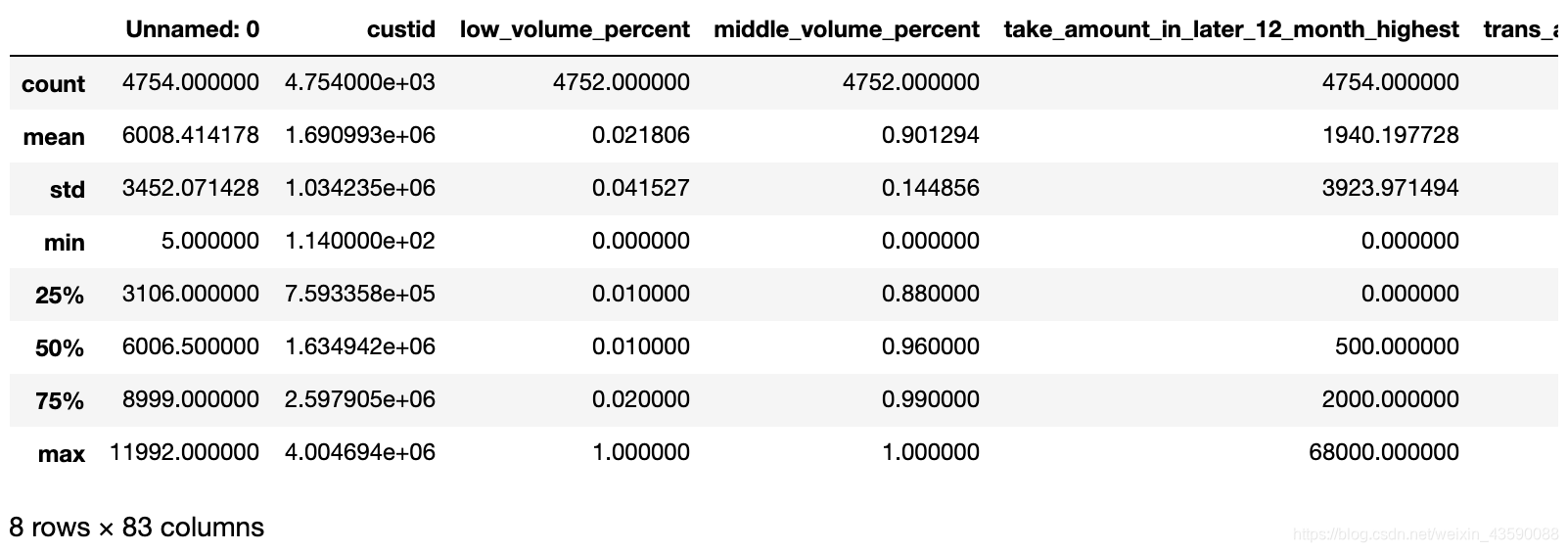
查看每个特征是什么类型,有多少行
data.info()
print("共有数据集:",data.shape[0])
输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4754 entries, 0 to 4753
Data columns (total 90 columns):
Unnamed: 0 4754 non-null int64
custid 4754 non-null int64
trade_no 4754 non-null object
bank_card_no 4754 non-null object
low_volume_percent 4752 non-null float64
middle_volume_percent 4752 non-null float64
take_amount_in_later_12_month_highest 4754 non-null int64
trans_amount_increase_rate_lately 4751 non-null float64
.......
consfin_product_count 4457 non-null float64
consfin_max_limit 4457 non-null float64
consfin_avg_limit 4457 non-null float64
latest_query_day 4450 non-null float64
loans_latest_day 4457 non-null float64
dtypes: float64(70), int64(13), object(7)
memory usage: 3.3+ MB
共有数据集: 4754
1.2 查看缺失值
data.isnull().sum().sort_values(ascending = False)
输出:
student_feature 2998
cross_consume_count_last_1_month 426
apply_credibility 304
query_cash_count 304
latest_six_month_apply 304
latest_three_month_apply 304
latest_query_time 304
query_sum_count 304
latest_one_month_apply 304
query_finance_count 304
.........
由上可得:
(1)发现有float、int、object这三种类型,特别注意object
查找类型是object的这列
for i in range(90):
if data.iloc[:,i].dtypes == "object":print(i)
输出:
2
3
28
45
48
55
75
把这几列单独展示
data_object = data.iloc[:,[2,3,28,45,48,55,75]]
data_object
输出:
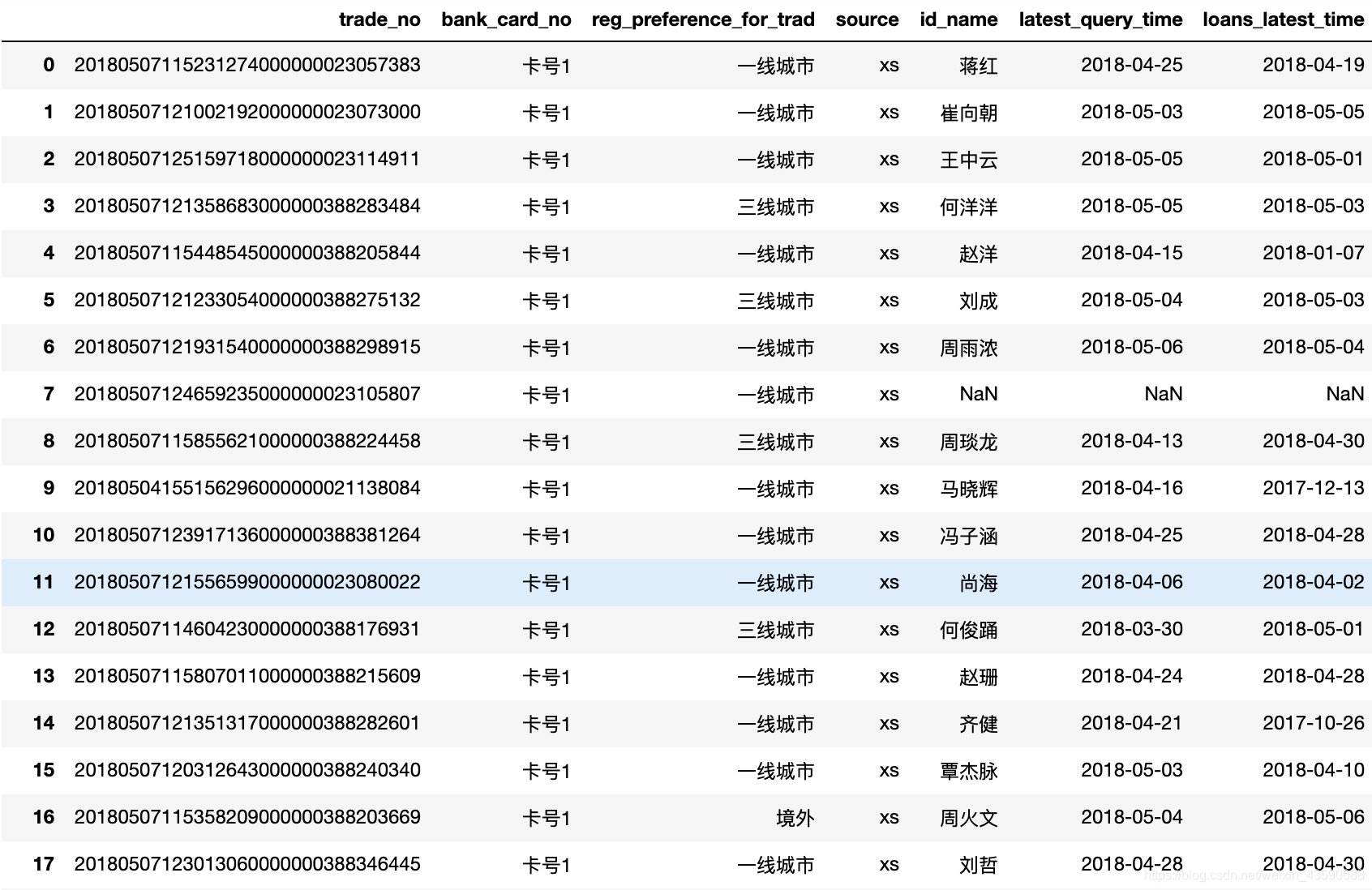
可以看到有两个列“bank_card_no”,“source”完全一样,是没有意义的数据,“id_name”,“trade_no”也没作用,在接下来的处理中需要删掉
(2)发现student_feature 这个特征缺失值较多,于是根据缺失值多少从大到小进行排序
1.3 查看每列某类重复值占的最大比例
import pandas as pd
# 计算每列出现频次最高的树的占比
def similar(df):
maxnum = (df.value_counts().max())/4754
return maxnum
data_similar = pd.DataFrame(data.apply(similar),columns={"similar"})
# 根据频次降序排列
data_similar = data_similar.sort_values("similar", ascending=False)
print(data_similar)
输出:
similar
source 1.000000
bank_card_no 1.000000
jewelry_consume_count_last_6_month 0.989272
is_high_user 0.988851
railway_consume_count_last_12_month 0.978334
status 0.749053
reg_preference_for_trad 0.715818
cross_consume_count_last_1_month 0.645351
latest_one_month_fail 0.621582
latest_one_month_loan 0.495793
pawns_auctions_trusts_consume_last_1_month 0.490745
latest_one_month_suc 0.482120
......
将占比超过97%的列删除,包括“source”,“bank_card_no”,“jewelry_consume_count_last_6_month”,“is_high_user ”,“railway_consume_count_last_12_month”
2. 无关特征删除
综上,去除与贷款用户是否会逾期的无关的特征
包括:“bank_card_no”,“source”,“id_name”,“trade_no”,“custid”,“jewelry_consume_count_last_6_month”,“is_high_user ”,“railway_consume_count_last_12_month”,“Unnamed: 0”
data = data.drop(['Unnamed: 0',"bank_card_no","source","id_name","jewelry_consume_count_last_6_month","is_high_user",
"railway_consume_count_last_12_month","custid","trade_no"],axis=1)
data.head()
输出:
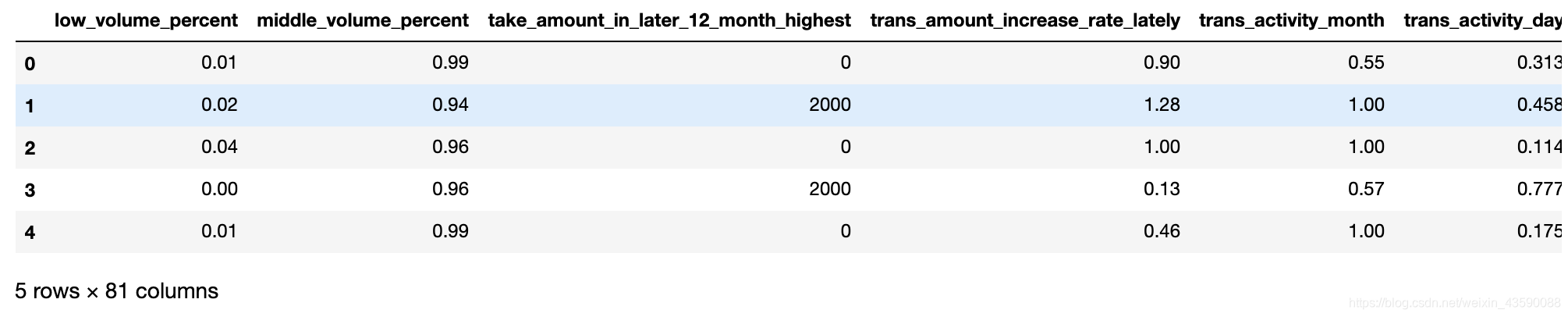
3. 数据类型处理
无关特征删除后,还存有3个 object 类型特征,其中两列latest_query_time,loans_latest_time为时间数据,需要另外处理
(1)先对reg_preference_for_trad做独热编码。
data = pd.get_dummies(data,columns=["reg_preference_for_trad"])
data = data.convert_objects(convert_numeric=True)
print(data.dtypes.value_counts())
输出:
float64 68
int64 10
uint8 5
object 2
dtype: int64
这里一列变成了5列
(2)对于latest_query_time和loans_latest_time,先变为dtype: datetime64[ns]
data['latest_query_time'] = pd.to_datetime(data['latest_query_time'])
data['loans_latest_time'] = pd.to_datetime(data['loans_latest_time'])
B = [(data['loans_latest_time'][i]-data['loans_latest_time'][2]).days for i in range(4754)]
A = [(data['latest_query_time'][i]-data['latest_query_time'][2]).days for i in range(4754)]
C = [(data['latest_query_time'][i]-data['loans_latest_time'][2]).days for i in range(4754)]
query_time_minus = pd.DataFrame(A,columns =["query_minus"])
loans_time_minus = pd.DataFrame(B,columns =["loans_time"])
query_loans_time_minus = pd.DataFrame(C,columns =["query_loans_time"])
data = pd.concat([query_time_minus,loans_time_minus,query_loans_time_minus, data], axis=1)
data = data.drop(['latest_query_time','loans_latest_time'], axis=1)
选择基准时间data_obj[‘loans_latest_time’][2],计算其他列时间数据,与它相距多少天,比方2018.7.20-2018.7.25,结果为-5天。
将列latest_query_time和loans_latest_time数据相减,得到一个相差多少天的数据。
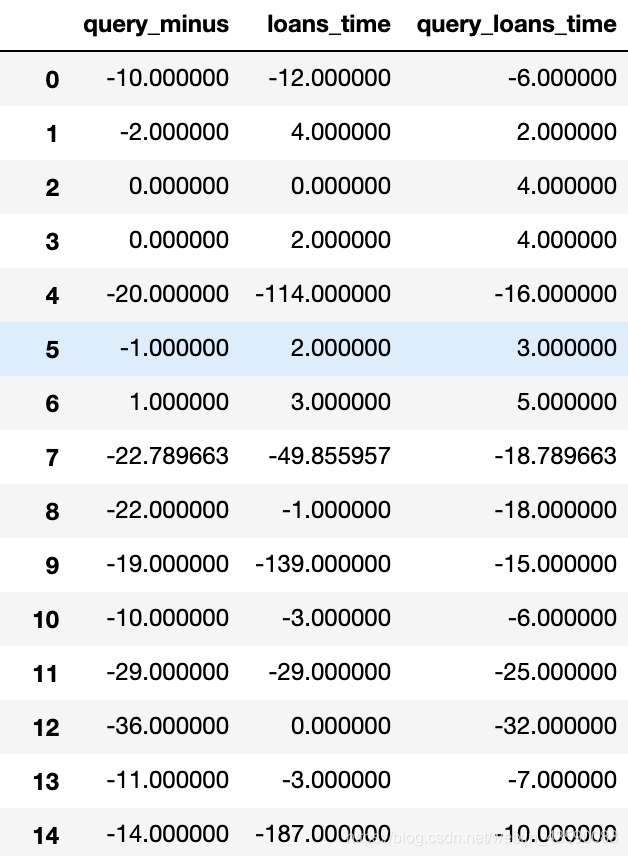
data = data.convert_objects(convert_numeric=True)
print(data.dtypes.value_counts())
输出:
float64 71
int64 10
uint8 5
dtype: int64
4. 缺失值填补
对于数值型的数据,采用均值填充
data = data.fillna(data.mean())
data
得到4754 rows × 86 columns
三、总结
拿到一个数据,首先是看缺失值,根据缺失值占比排序,删除前几个;再排除掉一列的值都相同的列;然后看数据类型,看如果存在非数值的,要处理这类,转换为数值型(注:时间类型可处理为时间序列);最后填充数据
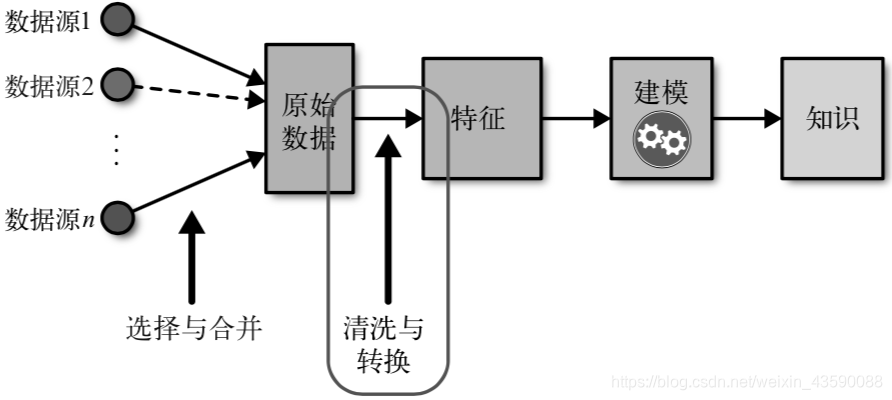
补充:机器学习流程
建模是以任务为导向的,处理得到需要的数据,筛选特征,特征与模型相辅相成。

















 2520
2520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









