






 MapReduce是一种编程模型,专为大规模数据集(大于1TB)的并行运算设计。其核心思想在于“分而治之”,通过Map(映射)和Reduce(归约)两个阶段,实现数据的并行处理。MapReduce框架简化了编程人员在分布式系统上的编程难度,同时具备处理海量数据的能力。
MapReduce是一种编程模型,专为大规模数据集(大于1TB)的并行运算设计。其核心思想在于“分而治之”,通过Map(映射)和Reduce(归约)两个阶段,实现数据的并行处理。MapReduce框架简化了编程人员在分布式系统上的编程难度,同时具备处理海量数据的能力。
上次的接着说。。。
其实 hadoop 比较贴合我们比较近的,我感觉就是 mapreduce 的内容。
MapReduce
下面是百科过来的。。。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
感觉说的云里雾里的,大致的感觉重要的就是:
一,是软件框架,二,是并行处理,三,是可靠且容错,四,是大规模集群,五,是海量数据集
简单来说 可以将我们对数据操作的代码 运行起来。利用 mapreduce 中的机制,完成代码中的运算任务。
MapReduce擅⻓长处理理⼤大数据,它为什什么具有这种能⼒力力呢?这可由MapReduce的设计思想发觉。
MapReduce的思想就是“分⽽而治之”。
map是什么?
Mapper负责“分”,即把复杂的任务分解为若⼲干个“简单的任务”来处理理。“简单的任务”包含三层含
义:
是数据或计算的规模相对原任务要⼤大缩⼩;
是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;
是这些小任务可以并行计算,彼此间几乎没有依赖关系。
reduce又是什么?
Reducer负责对map阶段的结果进行汇总。
简单来理解mapreduce:
统计图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
现在我们到一起,把所有⼈的统计数加在一起。这就是“Reduce”。
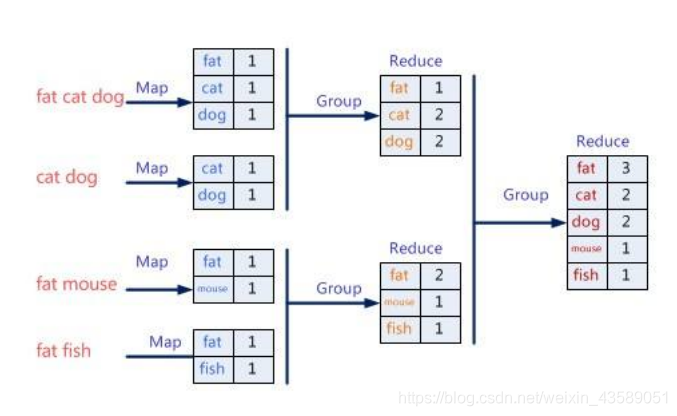
Reduce 的存在 可以统计,可以整合 相同的 Map 数据,减少 Map 结果的输出。
跟我们贴合比较近的部分就是 MR 任务的书写 就是 MapReduce 框架所代理的 代码。我们可以重点的了解一小下。。。
在代码中我们需要导入mapreduce相关的依赖。。

//-----------------------------------------分界线在此----------------------------------------------------//
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.0</version>
</dependency>
//-----------------------------------------我就一条分界线----------------------------------------------------//
首先,初始化MR任务:
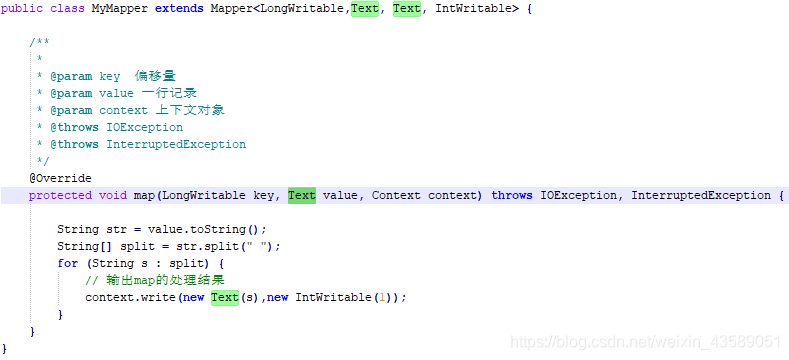
设置map 方法对于文档或者数据的需求操作(可以结合源码)分析:
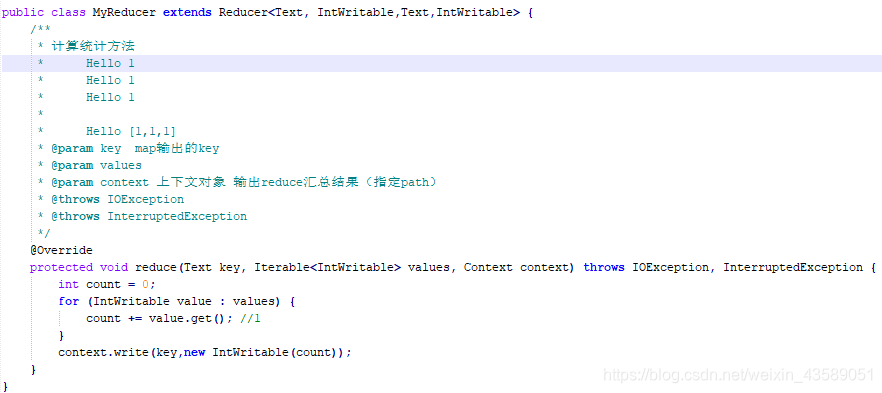
再就是 Reduce 对于Map 方法的统计,减少Map 的输出。
最后配置好 MR 的任务:
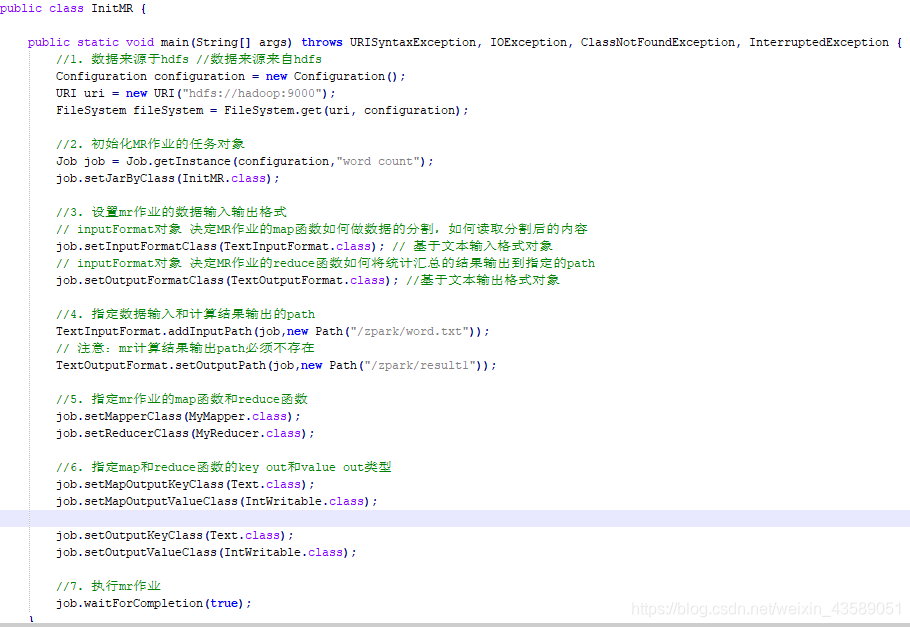
代码上的乱七八糟的还有点,我再啰嗦一下。
可以将项目打包成 jar 包 放在hadoop上所在的系统上运行。(效率较低,建议生产环境上使用)
可以本地上测试mian 方法(注意生成的可以访问文件信息的放置位置)
也可以通过配置,去数据库中查询信息,并且将处理好的信息放置到数据库中。(以后我会专门写的。。)
下面是比较丰富的图像展示 MapReduce 的执行流程:
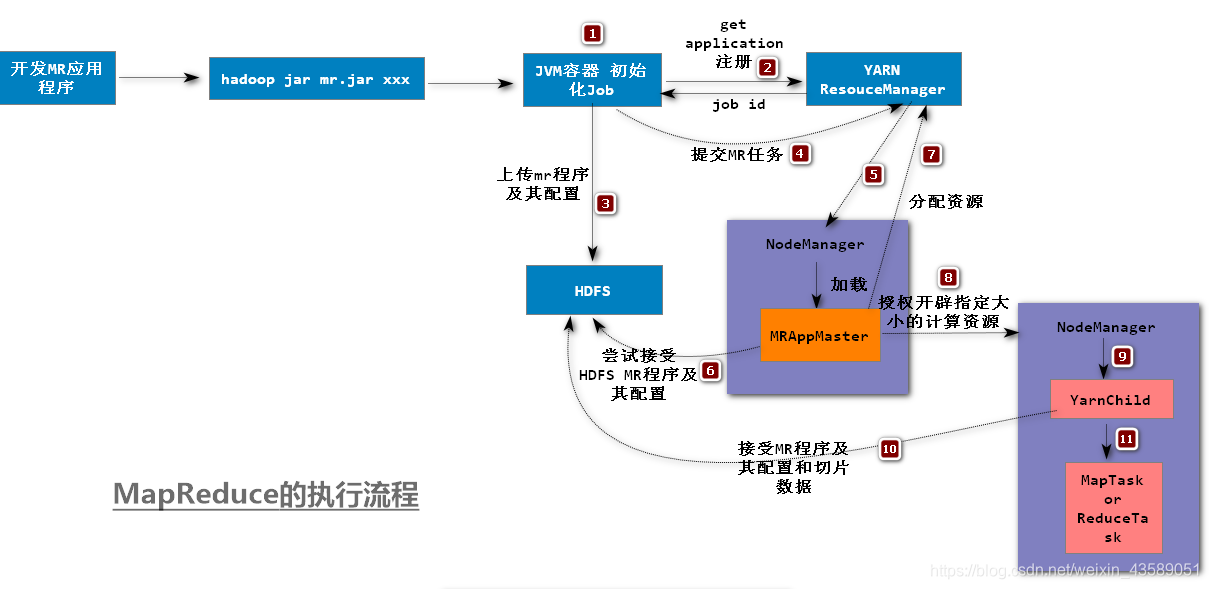
执行任务,需要空间,内存,cpu 占有。根据任务的大小,确定资源需要的多少,以避免不必要的浪费。这是一个很严重的问题。上面图上还有没讲到的,下面我会讲到 执行任务 需要的资源来自。。以及调配工作。。YARN 资源管理调度平台框架,先做一个预备。。
以上就是MapReduce的简单介绍,(发现用代码实现思想,实现具体的操作还是很酷的)深入了解的话,建议有条件的可以去扒看一下源码。。
Map对于搜集到的信息会作何处理?
Reduce对于数据怎么做到的重复的Key去除,以及整合的?
Yarn是什么?在MR中起了什么作用?
(未完待续......)

















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









