






 本文介绍Hadoop框架,涵盖HDFS、MapReduce和YARN等关键组件,阐述其在大数据处理中的作用,以及HDFS的架构和数据存储原理。
本文介绍Hadoop框架,涵盖HDFS、MapReduce和YARN等关键组件,阐述其在大数据处理中的作用,以及HDFS的架构和数据存储原理。
Hadoop 初步认识
开始认识 hadoop 的时候就觉得 hadoop 的作者非常有意思,利用自己孩子的玩具的名字,来命名自己利用两年的业余时间开发的适用于当前大数据时代的大量的信息收集 分析 处理的架构集群(这就是所谓的玩着玩着就把活干了的典型代表),下面是我偷来的知识总结。
简介
Apache Hadoop(http://hadoop.apache.org/)是⼀款框架,允许使⽤简单的编程模型跨计算机集群 分布式处理⼤型数据集。Hadoop开源免费,具备稳定可靠、可扩展、分布式计算等特性。
体系架构
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
Hadoop YARN: A framework for job scheduling and cluster resource management.
Hadoop MapReduce: A YARN-based system for parallel(并⾏) processing of large data sets.
我觉得其实就是这么回事:
数据计算的 资源调配,数据储存,信息的筛选处理 都是hadoop的比较核心的需要处理的问题,HDFS , MapReduce , Yarn 都是解决这些问题的组件。来 来 先来一张(鸟瞰图)图片.........
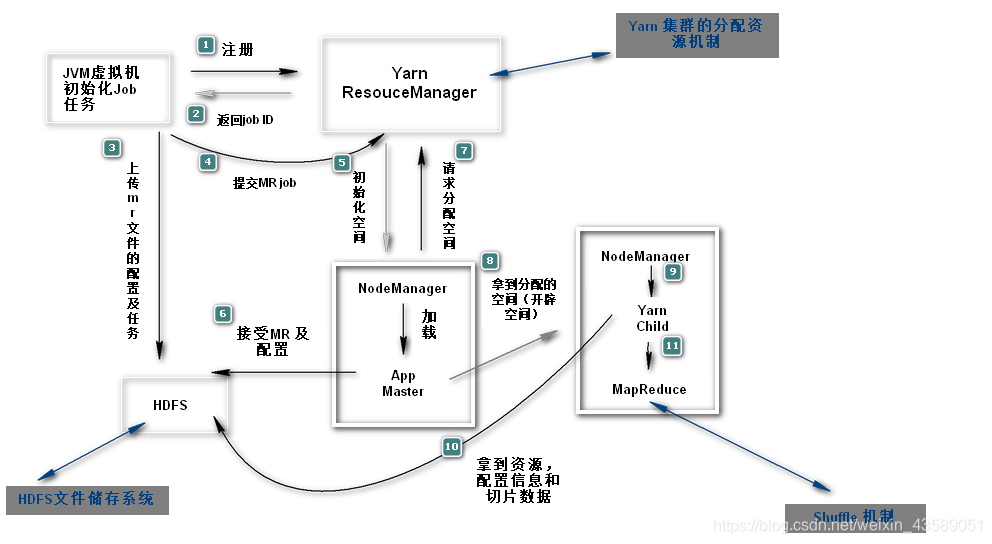
其实这是一张 MapReduce 的执行流程图,这张图放在这,是因为方便 理解整体各个组件(配合之间)的作业流程。。。我继续往下说。。
先从冰山一角说起....
HDFS
HDFS是Hadoop的分布式⽂件系统(Hadoop Distributed File System ),类似于其它的分布式⽂件。 HDFS⽀持⾼度容错,可以部署在廉价的硬件设备上,特别适宜于⼤型的数据集的分布式存储。
完成这样的操作少不了其中的核心组件:NameNode,DataNode,Block,SecondaryNameNode. 先来介绍一下这几个组件的作用及关系。
Namenode : 存储系统元数据、namespace、管理datanode、接受datanode状态汇报。
Datanode: 存储块 数据,响应客户端的块的读写,接收namenode的块管理指令。
Block(储存块): HDFS存储数据的基本单位,默认 值是128MB,实际块⼤⼩0~128MB。
SecondaryNameNode:辅助Namenode 的工具组件,可以加快Namenode的启动速度。(下有图示讲解)
Rack: 机架,对datanode所在主机的物理标识,标识主机的位置, 优化存储和计算
HDFS采⽤master/slave架构。⼀个HDFS集群是由⼀个Namenode和⼀定数⽬的Datanodes组成。 Namenode是⼀个中⼼服务器,负责管理⽂件系统的名字空间(namespace)以及客户端对⽂件的访问。 集群中的Datanode⼀般是⼀个节点⼀个,负责管理它所在节点上的存储。HDFS暴露了⽂件系统的名字 空间,⽤户能够以⽂件的形式在上⾯存储数据。从内部看,⼀个⽂件其实被分成⼀个或多个数据块, 这些块存储在⼀组Datanode上。Namenode执⾏⽂件系统的名字空间操作,⽐如打开、关闭、重命名 ⽂件或⽬录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理⽂件系统客户端的 读写请求。在Namenode的统⼀调度下进⾏数据块的创建、删除和复制。(下有图示)
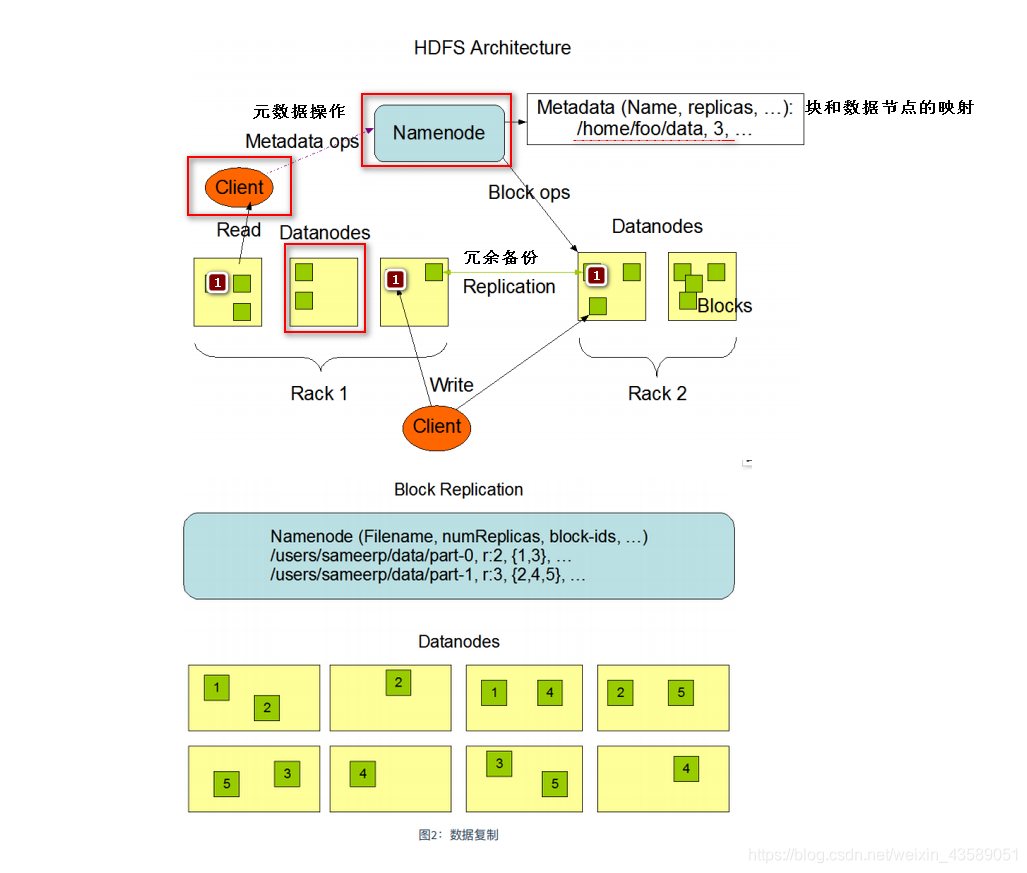
结合上图所示,我们可以看到 一个数据块上的数据进行了在不同机架上的备份,可以预防数据的丢失,提高了容错率。
* HDFS 适用于大数据集的储存,那么它能不能储存小文件呢????小视频啥的,,像FastDFS 一样。
答案是:当然可以! 但是!
1)⼩⽂件过多,会过多占⽤namenode的内存,并浪费block 。
2)HDFS适⽤于⾼吞吐量,⽽不适合低时间延迟的访问。⽂件过⼩,寻道时间⼤于数据读写时 间,这不符合HDFS的设计。
* 对于SecondaryNameNode 与 NameNode 关系的详解。。
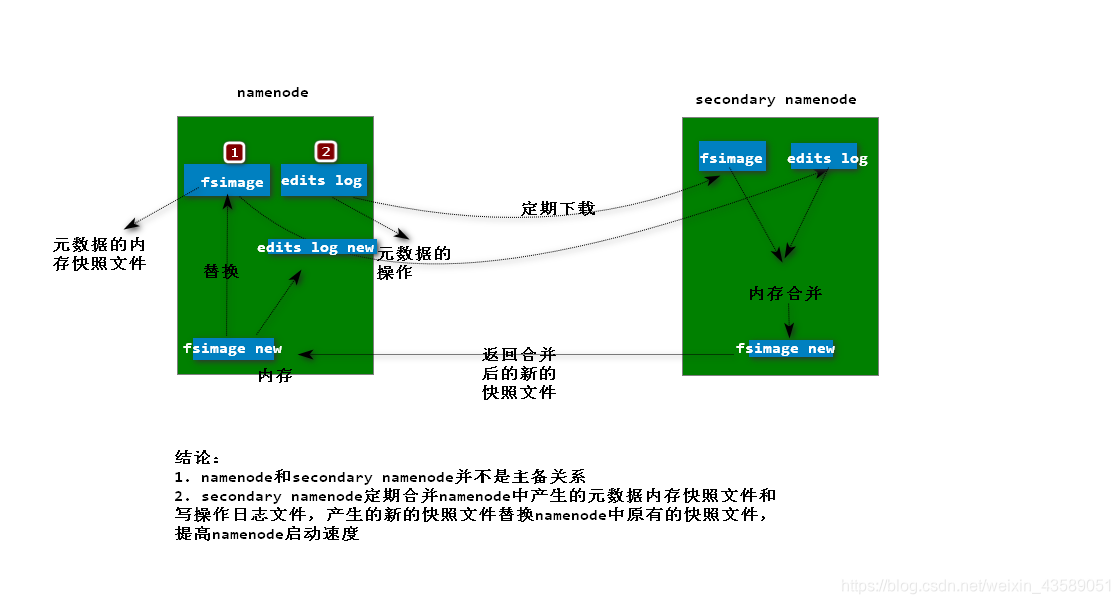
Namenode主要维护两个⽂件,⼀个是 fsimage ,⼀个是 editlog
1) fsimage保存了最新的元数据检查点,包含了整个HDFS⽂件系统的所有⽬录和⽂件的信息。 对于⽂件来说包括了数据块描述信息、修改时间、访问时间等;对于⽬录来说包括修改时间、 访问权限控制信息(⽬录所属⽤户,所在组)等。(快照)
2) editlog主要是在NameNode已经启动情况下对HDFS进⾏的各种更新操作进⾏记录,HDFS客户 端执⾏所有的写操作都会被记录到editlog中。(日志)
** 为了避免editlog不断增⼤,secondary namenode会周期性合并fsimage和edits成新的fsimage **
(未完待续......)

















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









