




 本文详细介绍了Python中字节顺序(大端、小端)、Struct模块的使用技巧,包括数据格式转换与网络传输处理。此外,还涵盖了原码、反码和补码的基本概念及其在编程中的应用。
本文详细介绍了Python中字节顺序(大端、小端)、Struct模块的使用技巧,包括数据格式转换与网络传输处理。此外,还涵盖了原码、反码和补码的基本概念及其在编程中的应用。
—计算机中以字节为单位,每个地址对应一个字节,一个字节8bit。在计算机系统中,如果大于一个字节,就需要区分字节顺序。
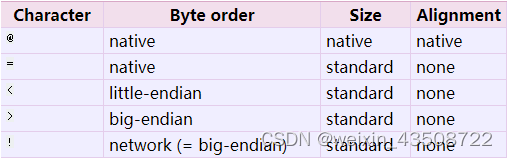
大端和小端即网络字节序,顾名思义,当数据在网络上传输时使用什么样的方式排序。常见的字节顺序分为:大端(Big Endian)和小段(Litter Endian)。想要理解什么是大端和小端,首先需要明确下面几个概念
一、基础知识
1.高字节和低字节
在一个n进制中,最左边的位叫最高有效位,最右边的叫最低有效位。
举例说明:
十进制整数:123456789
二进制表示:0000 0111 0101 1011 1100 1101 0001 0101
十六进制表示:07 5B CD 15
按照从右向左的方向,二进制中,0101是低字节、0000是高字节;
十六进制中,15是低字节,07是高字节。
2. 高地址和低地址
在内存中,多字节对象都是被存储为连续的字节序列。假设将int整型在内存中的起始地址(首个字节存储位置)为0x1000,那么另外三个字节就存储在0x1001~0x1003。不管存储的字节顺序是怎样的,内存地址的分配都是从小到大的增长。其中0x1000称为低地址端,0x1003称为高地址端。

3.大端和小端
大端:高字节存放在低地址,低字节存放在高地址
小端:低字节存放在低地址,高字节存放在高地址
还是以上面的int 123456789为例,十六进制表示: 07 5B CD 15
| 内存地址(低——>高) | 字节存储顺序 | |
|---|---|---|
| 大端(Big Endian) | 0x1000 0x1001 0x1002 0x1003 0x07 0x5B 0xCD 0x15 | 高字节存放在低地址,低字节存放在高地址 |
| 小端(Litter Endian) | 0x1000 0x1001 0x1002 0x1003 0x15 0xCD 0x5B 0x07 | 低字节存放在低地址高字节存放在高地址 |
二、Struct模块
用处:
按照指定格式将Python数据转换为字符串,该字符串为字节流,如网络传输时,不能传输int,此时先将int转化为字节流,然后再发送;
按照指定格式将字节流转换为Python指定的数据类型;
处理二进制数据,如果用struct来处理文件的话,需要用’wb’,’rb’以二进制(字节流)写,读的方式来处理文件;
处理c语言中的结构体;
struct 最常用的方法有两个:
- struct.pack(fmt,v1,v2,…)
返回的是一个字符串,是参数按照fmt数据格式组合而成 - struct.unpack(fmt,string)
按照给定数据格式解开(通常都是由struct.pack进行打包)数据,返回值是一个tuple
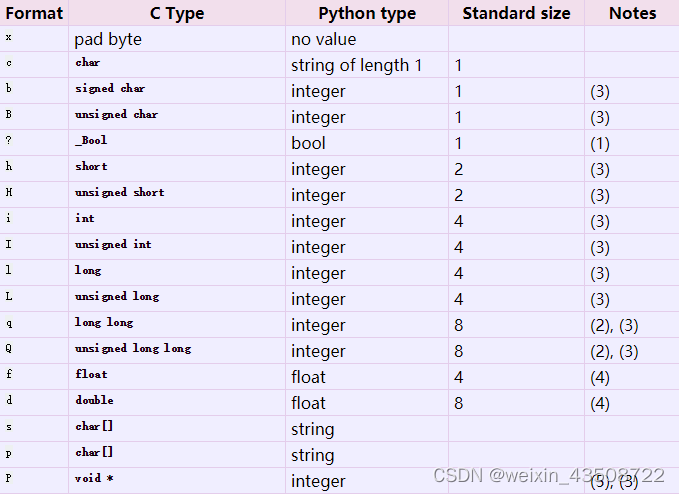
例子:
def demo1():
import struct
x = struct.unpack('<h', b'\xf0\xff')
print('struct:', x)
def demo2():
def hex_to_signed_dec(value):
return -(value & 0x8000) | (value & 0x7fff)
x= b'\xf0\xff'
d1 = int('0xf0', 16)
d2 = int('0xff', 16)
d_dec = (d2 << 8) + d1
print(hex_to_signed_dec(d_dec))
if __name__ == "__main__":
demo1() # struct: (-16,)
demo2() # -16
三、Python decoding
- Python decode() 方法以 encoding 指定的编码格式解码字符串。默认编码为字符串编码。
- str.decode(encoding=‘UTF-8’,errors=‘strict’)
- encoding – 要使用的编码,如"UTF-8"。
- errors – 设置不同错误的处理方案。默认为 ‘strict’,意为编码错误引起一个UnicodeError。 其他可能得值有 ‘ignore’, ‘replace’, ‘xmlcharrefreplace’, ‘backslashreplace’ 以及通过 codecs.register_error() 注册的任何值。
个人注解:常将收到的字节流bytes信息转化为str字符串,方便切分包头包数据。
同理有
2. Python encode() 方法以 encoding 指定的编码格式编码字符串。errors参数可以指定不同的错误处理方案。
str——bytes
a = bytes.decode(encoding='ISO-8859-1')
b = str(bytes,encoding='ISO-8859-1')
a、b等价
encode:编码
decode:解码
python内部编码方式为unicode,decode将其他编码方式转换成unicode编码方式,encode将unicode转换成其他编码方式。
因此unicode相当于一个中转:
(1)decode->unicode->encode
(2)encode->unicode->decode
四、原码、反码、补码
- 原码:原码是二进制数字的一种简单的表示法。二进制首位为符号位,1代表负,0代表正。
- 反码:反码可由原码得到。如果是正数,反码与原码相同;如果是负数,反码是其原码(符号位除外)各位取反而得到的。
- 补码:补码可由原码得到。如果是正数,补码与原码相同;如果是负数,补码是对其原码(除符号位外)各位取反,并在末位加1而得到的(有进位则进位,但不改变符号位)。
通常,整形数在内存中是以 补码 的形式存放的,输出的时候同样也是按照 补码 输出的。


















 1715
1715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









