







 本文介绍了BART和T5两种生成模型。BART是基于Transformer的序列到序列模型,通过去噪自编码器进行预训练,包括单词掩码、删除、句子排列、文档旋转和文本填充等任务。T5是Transformer编码器-解码器模型,最佳破坏策略是替换片段,预训练时采用无监督和有监督任务,统一转化为Seq2Seq格式。
本文介绍了BART和T5两种生成模型。BART是基于Transformer的序列到序列模型,通过去噪自编码器进行预训练,包括单词掩码、删除、句子排列、文档旋转和文本填充等任务。T5是Transformer编码器-解码器模型,最佳破坏策略是替换片段,预训练时采用无监督和有监督任务,统一转化为Seq2Seq格式。
BART
1.概述
使用标准的基于Transformer的序列到序列结构
主要区别在于用GeLU激活函数替换了原始结构中的ReLU
以及参数根据正态分布W(0,0.02)进行初始化
通过对含有噪声的输入文本去噪重构进行预训练,是一种典型的去噪自编码器
BART的预训练过程可以概括为以下两个阶段。首先,在输入文本中引入噪声,并使用双向编码器编码扰乱后的文本;然后,使用单向的自回归解码器重构原始文本。需要注意的是,编码器的最后一层隐含层表示会作为“记忆”参与解码器每一层的计算。BART模型考虑了多种不同的噪声引入方式,其中包括BERT模型使用的单词掩码。需要注意的是,BERT模型是独立地预测掩码位置的词,而BART模型是通过自回归的方式顺序地生成。
2.预训练任务
BART模型考虑了以下五种噪声引入方式:
(1)单词掩码
与BERT模型类似,在输入文本中随机采样一部分单词,并替换为掩码标记(如[MASK]):
(2)单词删除
随机采样一部分单词并删除。要处理这类噪声,模型不仅需要预测缺失的单词,还需要确定缺失单词的位置;
(3)句子排列变换
根据句号将输入文本分为多个句子,并将句子的顺序随机打乱。为了恢复句子的顺序,模型需要对整段输入文本的语义具备一定的理解能力;
(4)文档旋转变换
随机选择输入文本中的一个单词,并旋转文档,使其以该单词作为开始。为了重构原始文本,模型需要从扰乱文本中找到原始文本的开头;
(5)文本填充
随机采样多个文本片段,片段长度根据泊松分布进行采样得到。用单个掩码标记替换每个文本片段。当片段长度为0时,意味着插入一个掩码标记。要去除这类噪声,要求模型具有预测缺失文本片段长度的能力。
可以看到,BART的预训练任务结合了SOP、SpanBert等思路
3.下游任务
分类:
编码器和解码器使用相同输入,解码器最终时刻cls的隐含层作为输入文本的向量表示
序列标注:
编码器和解码器使用相同输入,解码器各个时刻的隐含层作为对应词向量表示
文本生成:
编码器输入,解码器生成
机器翻译:
把输入层embedding换成transformer编码器,把源语言中的词汇映射到目标语言的输入表示空间
也就是说由预训练encoder+预训练decoder变为新encoder+预训练encoder+预训练decoder
为了防止步调不一致,先固定Bart模型大部分参数,对源语言编码器、Bart模型位置向量和Bart预训练编码器的第一层自注意力输入投射矩阵进行训练;然后对所有参数少量迭代训练
T5
Transformer Encoder-Decoder 模型;
BERT-style 式的破坏方法;
Replace Span 的破坏策略;
15 %的破坏比;
3 的破坏小段长度。
1.预训练
–在Language Modeling策略(语言模型LM任务)、BERT-style策略(掩码语言模型MLM任务)和Deshuffling策略(复原打乱任务)中,BERT-style策略最优;
–在Mask策略(将每一个token用一个特殊字符替代)、Replace spans策略(将一个片段的token用个特殊字符替代)和Drop策略(将token舍弃)中,Replace spans策略最优;
–在掩码概率10%、15%、25%、50%的四种策略中,15%的策略最优;(也反向说明了BERT掩码15%的策略,不是空穴来风)
–在片段长度选择策略中,长度为3时最优。
T5 的预训练包含无监督和有监督两部分。
·无监督部分使用的是 Google 构建的近 800G 的语料(论文称之为 C4),而训练目标则跟 BERT 类似,只不过改成了 Seq2Seq 版本,我们可以将它看成一个高级版的完形填空问题:
输入:明月几时有,[M0] 问青天,不知 [M1],今夕是何年。我欲[M2]归去,唯恐琼楼玉宇,高处 [M3];起舞 [M4] 清影,何似在人间。
输出:[M0] 把酒 [M1] 天上宫阙 [M2] 乘风 [M3] 不胜寒 [M4] 弄
不同的掩码标记;只输出丢失的片段
·而有监督部分,则是收集了常见的 NLP 监督任务数据,并也统一转化为 SeqSeq 任务来训练。比如情感分类可以这样转化:
输入:识别该句子的情感倾向:这趟北京之旅我感觉很不错。
输出:正面
主题分类可以这样转化:
输入:下面是一则什么新闻?八个月了,终于又能在赛场上看到女排姑娘们了。
输出:体育
2.相对位置编码

https://kexue.fm/archives/8130
以下为self-attention部分:
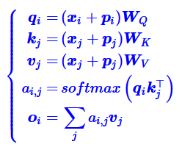
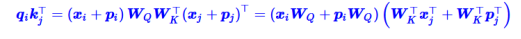
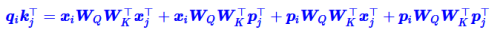
“输入-输入”、“输入-位置”、“位置-输入”、“位置-位置” 四项注意力的组合
“输入-位置”、“位置-输入” 两项Attention可以删掉
T5直接改成了:
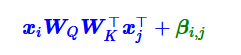
分桶处理:比较邻近的位置(0~7),我们需要比较得精细一些,所以给它们都分配一个独立的位置编码,至于稍远的位置(比如8~11),我们不用区分得太清楚,所以它们可以共用一个位置编码,距离越远,共用的范围就可以越大,直到达到指定范围再clip
XLNET式:
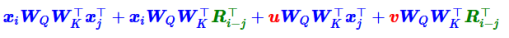
没有截断,而是直接用了Sinusoidal式的生成方案
上一篇:算法面试之Bert句表示、SBERT、SimBert
下一篇:算法面试之SimCSE
注:本专题大部分内容来自于总结,若有侵权请联系删除。



















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











