







 文章探讨了BERT句向量表示在未微调时表现不佳的问题,以及SBERT如何改进这一情况。SBERT通过共享参数的双BERT模型和Sentence Pooling提高句子向量的质量,适用于语义相似度任务。SimBERT利用Seq2Seq结构进一步增强模型性能。
文章探讨了BERT句向量表示在未微调时表现不佳的问题,以及SBERT如何改进这一情况。SBERT通过共享参数的双BERT模型和Sentence Pooling提高句子向量的质量,适用于语义相似度任务。SimBERT利用Seq2Seq结构进一步增强模型性能。
bert句子向量表示相似度效果不好
BERT根据下游任务fine-tuning后,使用CLS和全部序列的效果并不差。但如果没有fine-tuning,直接用BERT预训练的向量,CLS和全部序列的效果都很差
之所以效果这么差,是因为CLS向量在预训练任务中,参与的loss是NSP,优化的目标是下一句话。
Bert中最常用的句向量方式是采用cls标记位或者平均所有位置的输出值,注意,在采用平均的方式的时候,我们需要先做一个mask的操作,计算均值时,除以mask的和。但bert的句子向量效果不理想。
为什么呢?
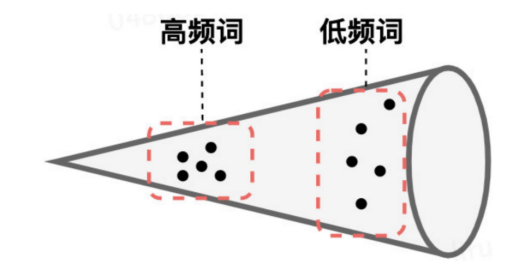
原因1:词频率影响词向量的空间分布。bert词向量表示与原点的L2距离的均值。高频的词更接近原点。
原因2:低频次分布偏向稀疏。度量词向量空间中与K近邻单词的 L2 距离的均值。我们可以看到高频词分布更集中,而低频词分布则偏向稀疏。然而稀疏性的分布会导致表示空间中存在很多“洞”,这些洞会破坏向量空间的“凸性”。考虑到BERT句子向量的产生保留了凸性,因而直接使用其句子embeddings会存在问题。
SBERT
BERT导出的句向量(不经过Fine-tune,对所有词向量求平均)质量较低,甚至比不上Glove的结果,因而难以反映出两个句子的语义相似
BERT对所有的句子都倾向于编码到一个较小的空间区域内,这使得大多数的句子对都具有较高的相似度分数,即使是那些语义上完全无关的句子对
BERT句向量表示的坍缩和句子中的高频词有关。具体来说,当通过平均词向量的方式计算句向量时,那些高频词的词向量将会主导句向量,使之难以体现其原本的语义。当计算句向量时去除若干高频词时,坍缩现象可以在一定程度上得到缓解。
在计算语义相似度时,需要将两个句子同时进入模型,进行信息交互,这造成大量的计算开销。例如,有10000个句子,我们想要找出最相似的句子对,需要计算(10000*9999/2)次,需要大约65个小时。Bert模型的构造使得它既不适合语义相似度搜索,也不适合非监督任务,比如聚类。
在问答系统任务中,往往会人为地配置一些常用并且描述清晰的问题及其对应的回答,我们将这些配置好的问题称之为“标准问”。当用户进行提问时,常常将用户的问题与所有配置好的标准问进行相似度计算,找出与用户问题最相似的标准问,并返回其答案给用户,这样就完成了一次问答操作。
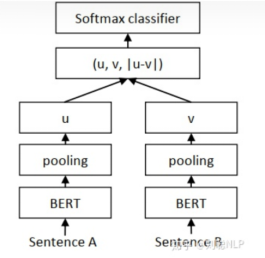
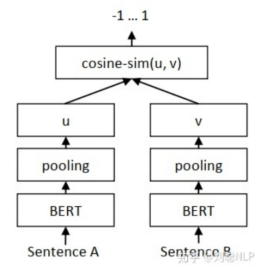
SBERT将句子对输入到参数共享的两个bert模型中,然后Bert输出句子的所有字向量传入Pooling层进行平均池化(既是在句子长度这个维度上对所有字向量求均值)获取到每个句子的句向量表示。
1.求句子向量
作者在文中定义了三种通过bert模型求句子向量的策略,分别是CLS向量,平均池化和最大值池化。
CLS向量策略,就是将bert模型中,开始标记【cls】向量,作为整句话的句向量。
平均池化策略,就是将句子通过bert模型得到的句子中所有的字向量进行求均值操作,最终将均值向量作为整句话的句向量。
最大值池化策略,就是将句子通过bert模型得到的句子中所有的字向量进行求最大值操作,最终将最大值向量作为整句话的句向量。
2.下游任务
Classification Objective Function
Regression Objective Function
Triplet Objective Function

SimBERT
https://spaces.ac.cn/archives/7427
UniLM
目前的一些对比实验证明,在其它条件相同的情况下,关于语言理解类的任务(参考Encoder-AE部分Google T5论文中的相关实验),Prefix LM结构的效果要弱于标准Encoder-Decoder结构。这里是值得深入思考下的,因为看上去Prefix LM和标准的Encoder-Decoder结构是等价的。那么,为什么它的效果比不过Encoder-Decoder结构呢?
一方面的原因估计是两者的参数规模差异导致的;
另外一方面,可能与它这种模式的Decoder侧对Encoder侧的Attention机制有关。
在Decoder侧,Transformer的每层 Block对Encoder做Attention的时候,标准的Encoder-Decoder模式,Attention是建立在Encoder侧的最后输出上,这样可以获得更全面完整的全局整合信息;
而Prefix LM这种结构,Decoder侧的每层Transformer对Encoder侧的Attention,是建立在Encoder的对应层上的,因为这种模式的Encoder和Decoder分割了同一个Transformer结构,Attention只能在对应层内的单词之间进行,很难低层跨高层。这可能是影响这种结构效果的原因之一
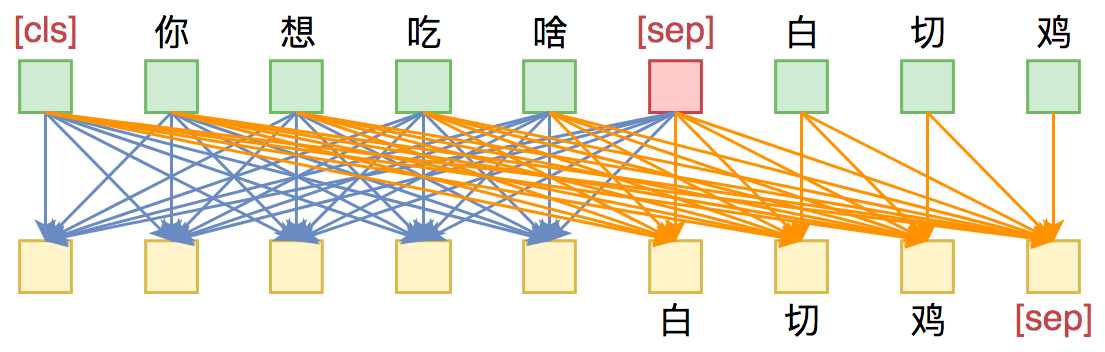
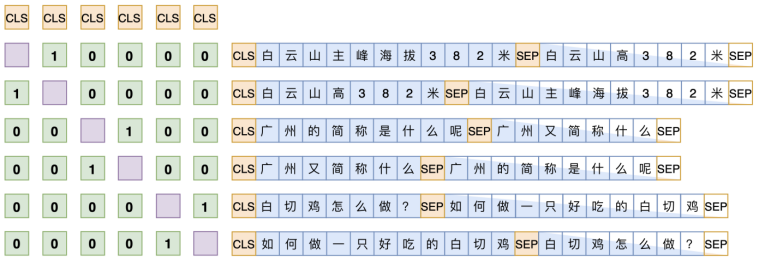
Seq2Seq只能说明UniLM具有NLG的能力,那前面为什么说它同时具备NLU和NLG能力呢?因为UniLM特殊的Attention Mask,所以 [CLS] 你 想 吃 啥 [SEP] 这6个token只在它们之间相互做Attention,而跟 白 切 鸡 [SEP] 完全没关系,这就意味着,尽管后面拼接了 白 切 鸡 [SEP] ,但这不会影响到前6个编码向量。再说明白一点,那就是前6个编码向量等价于只有 [CLS] 你 想 吃 啥 [SEP] 时的编码结果,如果[CLS]的向量代表着句向量,那么它就是 你 想 吃 啥 的句向量,而不是加上 白 切 鸡 后的句向量。
由于这个特性,UniLM在输入的时候也随机加入一些[MASK],这样输入部分就可以做MLM任务,输出部分就可以做Seq2Seq任务,MLM增强了NLU能力,而Seq2Seq增强了NLG能力,一举两得。
训练
训练语料是自行收集到的相似句对,通过一句来预测另一句的相似句生成任务来构建Seq2Seq部分

上一篇:算法面试之XLNet
下一篇:算法面试之生成模型BART、T5
注:本专题大部分内容来自于总结,若有侵权请联系删除。



















 5477
5477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











