







参考源码:
参考书籍:《神经网络与深度学习》
数据可以放在data 文件夹下
- mnist.py
# Standard library
import pickle
import gzip
# Third-party libraries
import numpy as np
def load_data():
"""Return the MNIST data as a tuple containing the training data,
the validation data, and the test data.
The ``training_data`` is returned as a tuple with two entries.
The first entry contains the actual training images. This is a
numpy ndarray with 50,000 entries. Each entry is, in turn, a
numpy ndarray with 784 values, representing the 28 * 28 = 784
pixels in a single MNIST image.
The second entry in the ``training_data`` tuple is a numpy ndarray
containing 50,000 entries. Those entries are just the digit
values (0...9) for the corresponding images contained in the first
entry of the tuple.
The ``validation_data`` and ``test_data`` are similar, except
each contains only 10,000 images.
This is a nice data format, but for use in neural networks it's
helpful to modify the format of the ``training_data`` a little.
That's done in the wrapper function ``load_data_wrapper()``, see
below.
"""
f = gzip.open('data/mnist.pkl.gz', 'rb')
training_data, validation_data, test_data = pickle.load(f, encoding="latin1")
f.close()
return (training_data, validation_data, test_data)
def load_data_wrapper():
"""Return a tuple containing ``(training_data, validation_data,
test_data)``. Based on ``load_data``, but the format is more
convenient for use in our implementation of neural networks.
In particular, ``training_data`` is a list containing 50,000
2-tuples ``(x, y)``. ``x`` is a 784-dimensional numpy.ndarray
containing the input image. ``y`` is a 10-dimensional
numpy.ndarray representing the unit vector corresponding to the
correct digit for ``x``.
``validation_data`` and ``test_data`` are lists containing 10,000
2-tuples ``(x, y)``. In each case, ``x`` is a 784-dimensional
numpy.ndarry containing the input image, and ``y`` is the
corresponding classification, i.e., the digit values (integers)
corresponding to ``x``.
Obviously, this means we're using slightly different formats for
the training data and the validation / test data. These formats
turn out to be the most convenient for use in our neural network
code."""
tr_d, va_d, te_d = load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
def vectorized_result(j):
"""Return a 10-dimensional unit vector with a 1.0 in the jth
position and zeroes elsewhere. This is used to convert a digit
(0...9) into a corresponding desired output from the neural
network."""
e = np.zeros((10, 1))
e[j] = 1.0
return e
- network1.py
import numpy as np
import random
import matplotlib.pyplot as plt
class Network(object):
def __init__(self, sizes):
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
def feedforward(self, a):
"""返回神经网络的输出如果a是输入"""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a) + b)
return a
def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None):
training_data = list(training_data)
n = len(training_data)
if test_data:
test_data = list(test_data)
n_test = len(test_data)
for j in range(epochs):
"""想迭代多少次,每一次都需要随机重排列"""
random.shuffle(training_data)
"""将training_date划分成小片,一片片的"""
mini_batches = [training_data[k:k + mini_batch_size]
for k in range(0, n, mini_batch_size)]
"""依次更新每个小切片"""
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
"""看看是否有测试数据"""
if test_data:
print("Epoch {}: {} / {}".format(
j, self.evaluate(test_data), n_test));
else:
print("Epoch %d complete", j)
def update_mini_batch(self, mini_batch, eta):
"""初始化和偏置矩阵和权重矩阵一样的矩阵,待更新"""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
"""利用BP算法算出梯度"""
delta_nabla_b, delta_nabla_w = self.backpro(x, y)
"""拿到梯度"""
nabla_b = [nb + dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw + dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
"""更新"""
self.weights = [w - (eta / len(mini_batch)) * nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b - (eta / len(mini_batch)) * nb
for b, nb in zip(self.biases, nabla_b)]
def backpro(self, x, y):
"""返回一个tuple(nabla_b, nabla_w) 表示代价函数C_x的梯度。
nabla_b和nabla_w是numpy数组的逐层列表,
类似于self.baises 和self.weights"""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# 正向传播
# 激活元
activation = x # 输入元
activations = [x] # 逐层存储所有的激活元
zs = [] # 存储z=wx+b 向量
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation) + b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
# l=1是倒数第一层,l=2倒数第二层
for l in range(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l + 1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l - 1].transpose())
return nabla_b, nabla_w
def evaluate(self, test_data):
#np.argmax(self.feedforward(x))找出最大值,即预测结果的index,和y放在一起
test_results = [(np.argmax(self.feedforward(x)), y)for (x, y) in test_data]
#比较result(预测值,标签)是否相等
return sum(int(x == y) for (x, y) in test_results)
def cost_derivative(self, output_activations, y):
return (output_activations - y)
def sigmoid(z):
return 1.0 / (1.0 + np.exp(-z))
def sigmoid_prime(z):
"""sigmoid函数的导数"""
return sigmoid(z) * (1 - sigmoid(z))
- run.py
import mnist_load
import network1
training_data,validation_data,test_data = mnist_load.load_data_wrapper()
net = network1.Network([784,30,10])
net.SGD(training_data, 10, 10, 3.0,test_data = test_data)
运行结果:
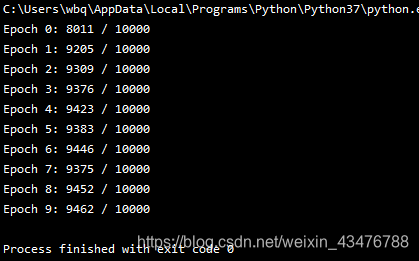
为了获得这些准确性,不得不对训练的迭代期数量、批量数据、和学习速率 η 做特别的选择。这些在神经网络中被称为超参数,以区别于学习算法所学到的参数(权重和偏置)。

















 6622
6622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









