







上次介绍了线性回归问题,用平方误差计算出w。本节课介绍Logistic regression:逻辑斯蒂回归。
一、Logistic regression问题
学习流程图,比如我们要看病人是否有心脏病,
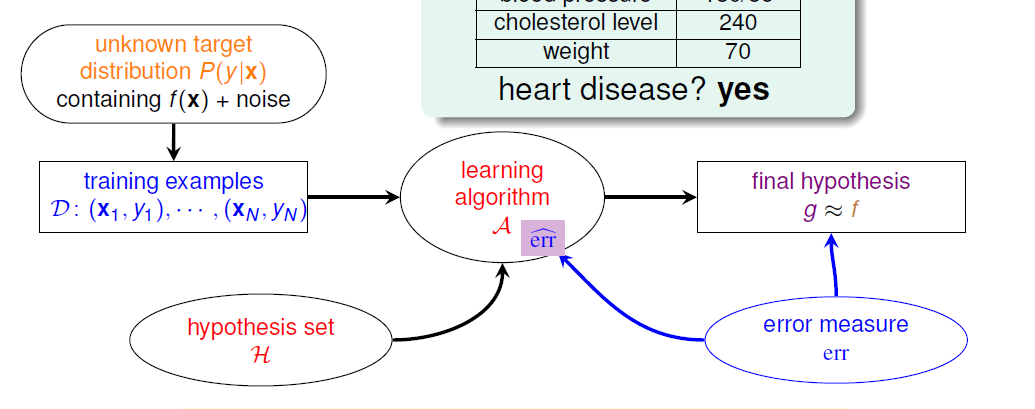
左上角说我们拿到的资料可能有noise,x是病人特征,这个目标分布P会对应一个理想的目标函数f,
当我们想知道病人有没有心脏病,做二分类问题:
![]()
今天一个类似的问题,我们不想知道他有没有心脏病,我们想知道病人心脏病的可能性是多少?我们想要得到一个[0,1]之间的值P(y|x),我们的目标函数f就变为
![]()
这个值越接近1,表示正类的可能性越大;越接近0,表示负类的可能性越大。
所以,比如在病人问题中,我们希望的资料是label y是病人患病的可能性,如,

但是实际中我们并不能拿到这样的label,医院里的病人只知道病人的病历(是否心脏病发),所以实际我们不知道具体的概率数字是多少。

我们可以把手上的的资料看做上面理想资料的有noise版本:

比如第一行 的label:0.9(真实)+0.1(noise)=1(我们实际拥有的)
我们现在要讨论的问题是:我们手上的资料是原来二分类问题的资料,现在想得到的目标函数f的输出是一个0~1之间的值,那么我们如何选择h?
根据我们之前的做法,对病人x所有的特征值进行加权处理,计算出一个分数。
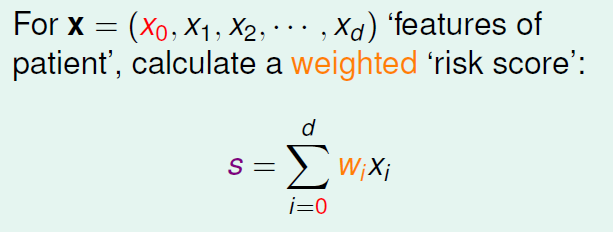
此刻分数并不是我们首要在乎的,想得到的目标函数f的输出是一个0~1之间的值。如何将前者“分数”转化为后者呢?
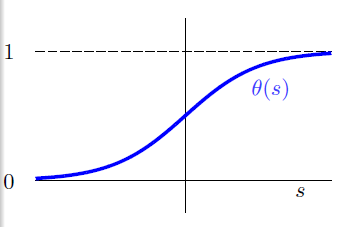
横轴是分数s,纵轴是0-1之间的数字,这样任何的分数s都可以转化为[0,1]之间。我们把这个转化函数叫做Logistic函数,记作。
Logistic函数公式
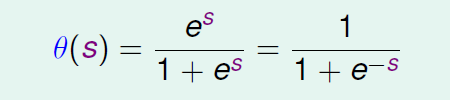
这个公式希望当分数越高时候,输出越靠近1,分数越低,输出越靠近0.
我们学习到的h就是:
![]()
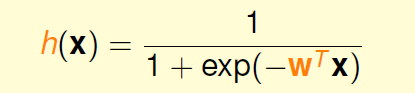
二、Logistic回归误差
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









