






 本文详细介绍了Transformer模型的架构,包括编码器和解码器的位置编码以及多头注意力机制。位置编码通过泰勒展开和复数思想实现,多头注意力机制则是通过集成多个注意力机制来增强模型表现。此外,还提及了残差连接防止梯度消失以及layernorm相对于BN的优点。虽然Decoder部分的mask部分讲解不够清晰,但整体内容对理解Transformer模型有较大帮助。
本文详细介绍了Transformer模型的架构,包括编码器和解码器的位置编码以及多头注意力机制。位置编码通过泰勒展开和复数思想实现,多头注意力机制则是通过集成多个注意力机制来增强模型表现。此外,还提及了残差连接防止梯度消失以及layernorm相对于BN的优点。虽然Decoder部分的mask部分讲解不够清晰,但整体内容对理解Transformer模型有较大帮助。
学习视频地址:
https://www.bilibili.com/video/BV1Di4y1c7Zm?from=search&seid=16737619548015070094
总体来说是这样一个架构。

encoding/decoding:
位置编码详解:
下面这个视频讲的很清晰。
https://www.bilibili.com/video/BV1vA411V71k?from=search&seid=16094804352675454411
大概就是说,通过泰勒展开,设H=I,然后二维位置可以采用复数思想,要做到(5)式,pq乘积可以表示一个相对位置

通过计算发现:

扩展到多维:
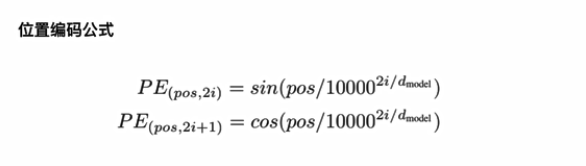
多头注意力机制:
多头+注意力机制
多头其实就是一个集成,将很多个注意力机制集成起来。
注意力机制:Q,K,V
残差:
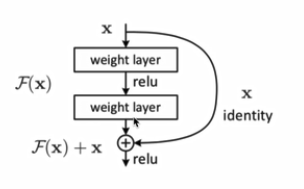
防止梯度变为0.
layernorm:
BN有很多缺点:
例如size较小时候,用批量的mean和var估计所有的,可能会不准。
decoder部分的mask部分我觉得讲的不太清楚。。。以后再看。。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









