







 SPP-net通过引入空间金字塔池化层,解决了深层CNN对固定尺寸输入的需求,实现了对任意尺寸图像的处理。论文展示了SPP-net在ImageNet2012、PASCAL VOC2007和Caltech101数据集上的出色分类和检测性能,同时提高了训练和测试阶段的效率。SPP-net不仅增强了对目标尺度和变形的鲁棒性,还允许使用多尺寸训练,从而提升了模型的准确性。
SPP-net通过引入空间金字塔池化层,解决了深层CNN对固定尺寸输入的需求,实现了对任意尺寸图像的处理。论文展示了SPP-net在ImageNet2012、PASCAL VOC2007和Caltech101数据集上的出色分类和检测性能,同时提高了训练和测试阶段的效率。SPP-net不仅增强了对目标尺度和变形的鲁棒性,还允许使用多尺寸训练,从而提升了模型的准确性。
文章目录
- (SPPNet)Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition论文阅读笔记2014
(SPPNet)Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition论文阅读笔记2014
Abstract
目前的深层CNN都需要固定尺寸的输入图像。这种需要是“人工的”,可能会对任意尺度的图像识别的准确率有所降低。本文中,我们提出了一种新的网络,使用了另一种池化策略,“空间金字塔池化”,来消除上面的这种固定尺寸要求。**我们的新网络,SPP-net,无论输入图像的尺寸,都生成一个固定维度的表示representation。**金字塔池化同样对目标变形是鲁棒的,有着这些优点,SPP-net应该可以整体上提升所有基于CNN的图像分类方法的表现。在ImageNet2012数据集上,我们实验得出SPP-net可以提升了多种不同结构的CNN的表现效果。在PASCAL VOC2007以及Caltech101数据集上,SPP-net使用了单个整张图像表示,没经过微调,达到了目前最好的分类表现。
SPP-net的表现在目标检测领域也很重要。**使用SPP-net,我们只对整张图片计算一次,得到特征图,然后在任意区域(sub-images)进行池化,得到固定长度的representation,用来训练检测器。**这种方法避免了重复计算卷积特征。在处理测试图像时,我们的方法比R-CNN快24-102倍,而在PASCAL VOC2007上取得了和它相当的准确率。
在ILSVRC2014上,我们的方法在目标检测排名第二,在图像分类上排名第三。文章中同样介绍了针对比赛对网络进行的修改。
1. Introduction
我们见证着一个视觉领域高速发展、变革的时代,主要是由CNN以及大尺度训练数据的出现带来的。基于深度网络的方法目前极大地提升了在图像分类、目标检测以及其他识别和非识别任务的表现能力。
然而,在CNN的训练和测试中有一个技术问题:目前流行的CNN,需要的输入是固定尺寸的(比如224 * 224),这就限制了输入图像的长宽比和尺度。当应用到任意尺寸的图像上时,目前的方法大部分是将通过裁剪,或者变形输入图像转换为固定尺寸,如图1(top)所示。但是,**裁剪的区域可能不包含整个目标,而变形的区域可能会导致不需要的几何变形。**因为这种loss或变形会导致识别准确率下降,除此之外,提前确定好的尺度在目标尺度变化时,可能不适用了。
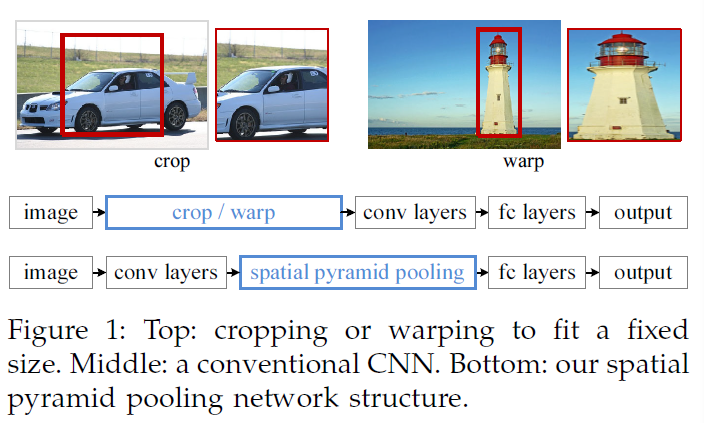
那么,CNN为什么需要固定尺寸的输入呢?CNN主要由两部分组成,卷积层和之后的FC层。卷积层使用滑窗的方式进行计算,输出特征图(代表激活值的空间分布)。实际上,卷积层不需要固定的输入尺寸,可以对任意尺寸的图像生成特征图。FC层需要固定的输入尺寸,因此,固定尺寸这个要求主要来自于FC层,FC层一般存在于网络的深层。
本文中,我们介绍一种空间金字塔池化(SPP)层,来移除固定尺寸的限制。==我们在最后一层卷积层后加入SPP层,SPP层对特征图进行池化,然后生成固定长度输出,再送入到FC层(或其他分类器)。==也就是说,我们在卷积层和FC层之间进行某种信息聚合,来取消一开始的裁剪或者变形操作。图1(bottom)展示出加入SPP层之后的网络结构变化,我们将这个新网络叫做SPP-net。
空间金字塔池化(更多叫做空间金字塔匹配SPM),作为词袋模型的一种扩展,是计算机视觉中最成功的方法之一。**它将图片分区成不同等级,从细致到粗糙,然后在每个等级中聚合本地特征。**在CNN流行之前,SPP一直都是分类和检测的优秀模型的关键成分之一。不过,SPP一直没有被考虑应用到CNN中。我们注意到SPP对CNN有几个显著的特点:
- SPP可以生成固定长度的输出,无论输入尺寸是多大,然而通常CNN使用的滑窗的池化层不可以。
- SPP使用了多尺度的空间bins,然而滑窗的池化只是用了单个尺度。多等级的池化对目标变形具有更好的鲁棒性。
- 由于输入尺度的灵活性,SPP可以对在多种尺度生成的特征进行池化。
通过实验证明,上面几种特点都提升了深度网络的准确性。
SPP-net不仅可以在测试时对任意尺寸图像或窗口生成表示,而且可以让我们在训练时使用多种尺寸尺度的图像来进行训练。**使用多种尺寸图像训练可以提升尺度不变性,减少过拟合。**我们采取一个简单的多尺寸训练方法。**为了使单个网络接受可变的输入大小,我们可以通过共享所有参数的多个网络对它进行近似,而每个网络都使用固定的输入大小进行训练。**在每个epoch,我们使用一个固定尺寸训练网络,然后在下一个epoch使用另一个尺寸进行训练。实验证明这种训练方式收敛地跟单尺寸训练一样快,还有着更好的测试准确率。
SPP的优点与特定的CNN设计正交。在一系列的在ImageNet2012数据集上的控制实验中,我们发现SPP提升了四种不同的CNN结构的表现,相对于没有SPP的对应模型。这些结构有着不同的卷积核数量、尺寸、步长、深度以及其他参数。**因此我们可以认为SPP对更复杂的CNN结构同样有所提升。**SPP在Caltech101以及PASCAL VOC2007数据集上,在使用单一整张图像表示以及没有微调的情况下,取得了当今领先的分类表现。
SPP-net在目标检测上同样展现出强劲实力。目前领先的R-CNN方法中,候选区域的特征是通过深度卷积网络来提取到的。这种方法在VOC和ImageNet上都取得了好的结果。**但是R-CNN中的特征计算十分耗时,因为它重复将CNN应用在每张图的上千个raw pixels的变形区域。**本文中,我==们的方法只需要在整张照片上计算卷积一次(无论候选框的个数),然后再特征图上提取特征。==这种方法使得比R-CNN提升了近百倍速度。注意到在特征图上进行训练或测试(而不是在原始图像区域)是更流行的方法。SPP-net不止继承了深层CNN的特征图的能力,而且有着SPP在任意尺寸上的灵活性,这就使得网络取得了杰出的准确率和效率。随着最近的快速proposal方法EdgeBoxes的出现,我们的系统可以在0.5s处理一张图像,这使得我们的方法在真实世界应用成为可能。
2.Deep Networks With Spatial Pyramid Pooling
2.1 Convolutional Layers and Feature Maps
对经典的七层结构,前五层是卷积层,有的后边接了池化,这些池化也应该被当做“卷积的”,因为它们使用滑窗来进行。最后两层是FC层,输出N维的softmax。
上面介绍的深度网络需要固定尺寸的图像。**然而我们发现,这个需求只是由于FC层需要固定尺寸的输入,卷积层可以接受任意尺寸的输入。**卷积层使用滑窗计算,输出的特征图与输入有着同样的长宽比,包含着响应值信息以及空间位置信息。
在图2中,我们可视化一些特征图,他们有conv5的一些卷积核生成,(c)展示出在ImageNet数据集上最强响应的图像,一些filter可以被一些语义成分所激活。比如,第55个filter最易被圆形激活,第66个filter最易被^形激活…输入图像中的这些形状(图2a)在相应的位置激活了特征图。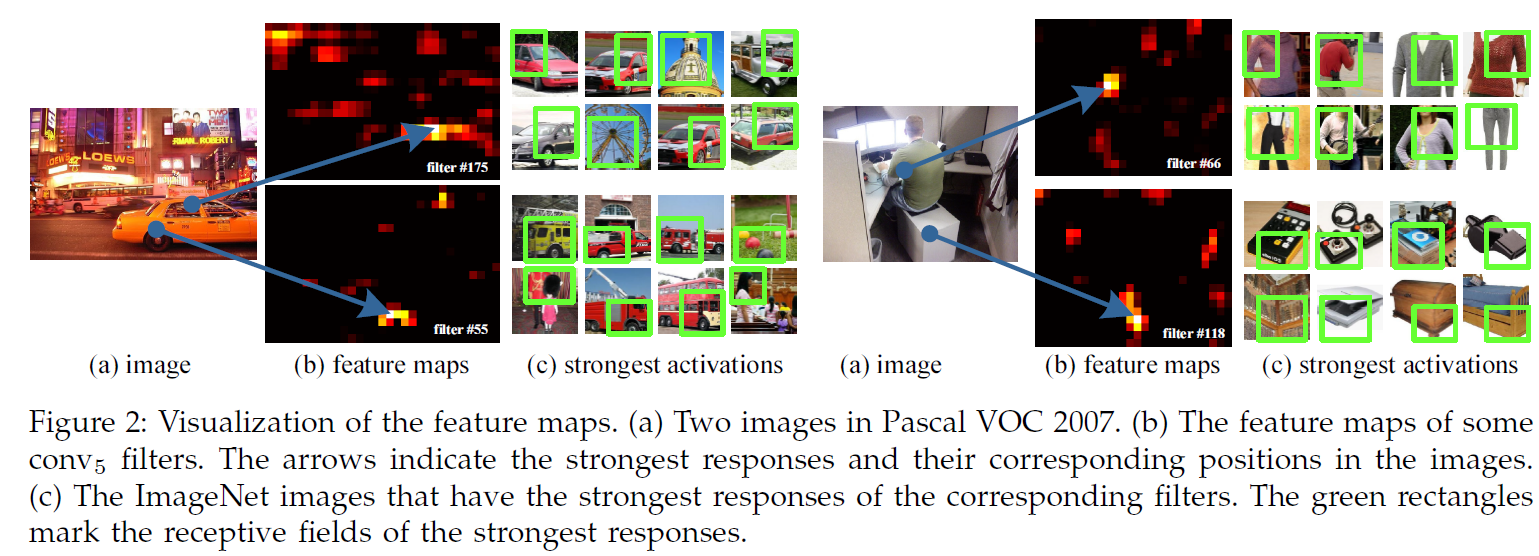
值得注意的是,我们在没有固定输入尺寸的情况下,生成了图2中的特征图。这些通过深度CNN生成的特征图与传统方法生成的特征图类似。在那些方法中,SIFT或image patches密集提取,然后被编码成向量、稀疏coding或Fisher kernels。这些编码特征组成了特征图然后使用词袋或空间金字塔进行池化。相似地,CNN以相似方法进行池化。
2.2 The Spatial Pyramid Pooling Layer
卷积层接收任意输入尺寸,但是生成的也是不同尺寸的输出。分类器(SVM/softmax)以及FC层需要固定长度的向量。一般可以通过词袋BoW来将特征池化,生成向量。**空间金字塔池化对词袋有所提升,它可以保留空间信息,在局部空间bins进行池化。**这些空间bins的尺寸与图像尺寸成比例,所以无论图像尺寸如何,生成的bins数量是固定的。这与输出尺寸依赖于输入的CNN相反。
**我们使用一个空间金字塔池化层取代了原网络的最后一个池化层,如图3所示。在每个空间bin,我们对每个filter的响应进行最大池化。**最后的输出为kM维度的向量,k为最后一层卷积层的卷积核数,M为bin的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









