




 本文整理了Python爬虫面试中常见的138至155题,涉及requests、lxml、scrapy的工作流程、去重原理、中间件、反爬策略、代理使用及验证码处理等核心知识点。
本文整理了Python爬虫面试中常见的138至155题,涉及requests、lxml、scrapy的工作流程、去重原理、中间件、反爬策略、代理使用及验证码处理等核心知识点。
参考自:https://cloud.tencent.com/developer/article/1490616(题目来源)
所有题目
爬虫相关
138.在 requests 模块中,requests.content 和 requests.text 什么区别
content:中间存的是字节码(字节)
text:这个是str的数据类型(unicode),是requests库将response.content进行解码后的字符串(文本内容)。
当出现中文乱码或其他乱码情况是可以使用:
response.encoding = 'utf-8' 、response.encoding = 'gbk'
或者直接使用:
response.encoding = response.apparent_encoding
response.encoding: 指的是requests库从http的响应头中猜测出来的响应内容编码方式
response.apparent_encoding: 指的是requests库从内容分析出的响应内容的编码方式(更为精确一点)
139.简要写一下 lxml 模块的使用方法框架
lxml是功能最丰富且易于使用的库,用于处理Python语言中的XML和HTML。
from lxml import etree
text = ''' <div> <ul>
<li class="item-1"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul> </div> '''
#将字符串转化为Element对象,Element对象具有xpath的方法,
#返回结果的列表,能够接受bytes类型的数据和str类型的数据
##etree会修复HTML文本节点
html = etree.HTML(text)
print(type(html))
handeled_html_str = etree.tostring(html).decode()
print(handeled_html_str)
更多详细使用参考:
https://www.cnblogs.com/zhangxinqi/p/9210211.html
140.说一说 scrapy 的工作流程
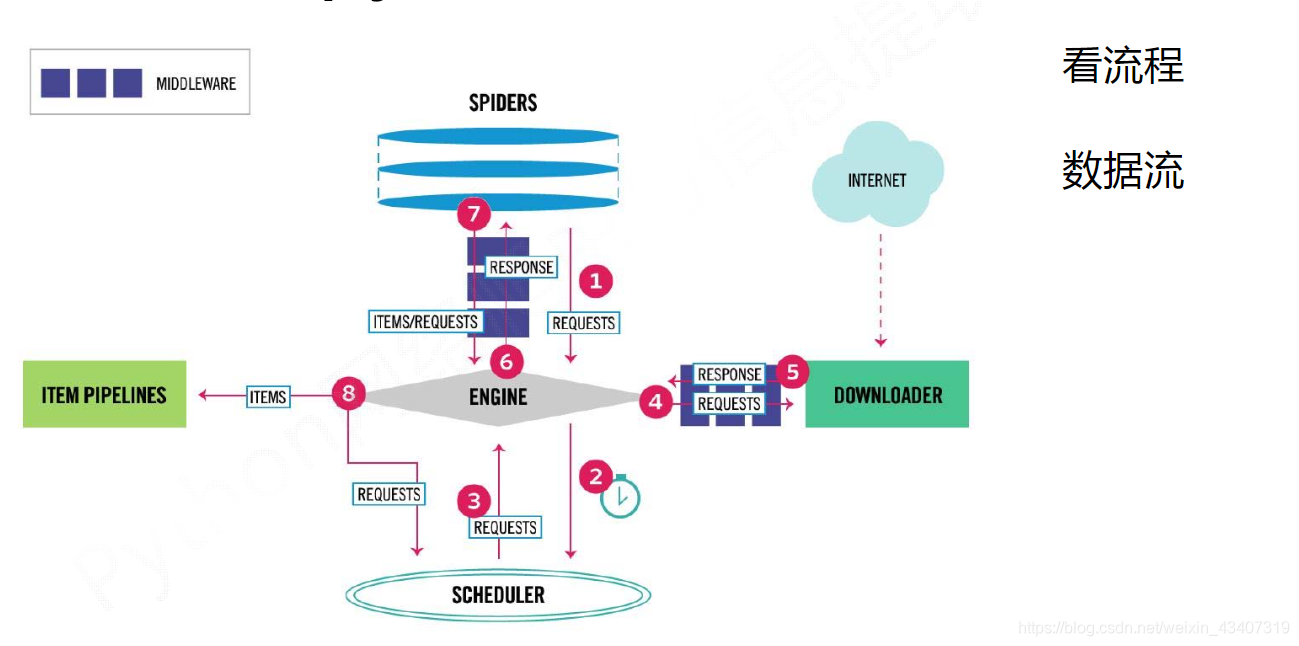
名词解释:
SPIDERS:爬虫代码(爬虫的代码逻辑)
ENGINE:爬虫引擎(相当于电脑CPU)
SCHEDULER:调度器(调度网址)
DOWNLOADER:下载器(下载HTML)
ITEM PIPELINES:存储管道(存储数据)
1. Engine从Spider处获得爬取请求(Request)
2. Engine将爬取请求转发给Scheduler,用于调度
3. Engine从Scheduler处获得下一个爬取的请求
4. Engine将爬取请求通过中间件发送给Downloader
5. 爬取网页后,Downloader形成响应(Response)通过中间件发给Engine
6. Engine将收到的响应通过中间件发送给Spider处理
7. Spider处理响应后产生爬取项(scraped Item)和新的爬取请求(Requests)给Engine
8. Engine将爬取项发送给Item Pipeline(框架出口)
9. Engine将爬取请求发送给Scheduler
Engine控制各模块数据流,不间断从Scheduler处获得爬取请求,直至请求为空。
框架入口:Spider的初始爬取请求
框架出口:Item Pipeline
141.scrapy 的去重原理
1.Scrapy本身自带有一个中间件;
2.scrapy源码中可以找到一个dupefilters.py去重器,里面有一个方法叫做request_seen,它在 scheduler(发起请求的第一时间)的时候被调用。
它代码里面调用了 request_fingerprint 方法(就是给 request 生成一个指纹)。;
3.需要将dont_filter设置为False开启去重,默认是True,没有开启去重;
4.对于每一个url的请求,调度器都会根据请求得相关信息加密(类似于MD5)得到一个指纹信息,并且将指纹信息和set()集合中的指纹信息进 行 比对,
如果set()集合中已经存在这个数据,就不在将这个Request放入队列中;
5.如果set()集合中没有存在这个加密后的数据,就将这个Request对象放入队列中,等待被调度。
142.scrapy 中间件有几种类,你用过哪些中间件
scrapy 的中间件理论上有三种(Schduler Middleware,Spider Middleware,Downloader Middleware)。在应用上一般有以下两种
爬虫中间件 Spider Middleware:主要功能是在爬虫运行过程中进行一些处理。
下载器中间件 Downloader Middleware:这个中间件可以实现修改 User-Agent 等 headers 信息,处理重定向,设置代理,失败重试,设置 cookies 等功能。
143.你写爬虫的时候都遇到过什么?反爬虫措施,你是怎么解决的?
1. 通过headers反爬虫:解决策略,伪造headers
2. 基于用户行为反爬虫:动态变化去爬取数据,模拟普通用户的行为,使用IP代理池爬取或者降低抓取频率,或通过动态更改代理ip来反爬虫
3. 基于动态页面的反爬虫:跟踪服务器发送的ajax请求,模拟ajax请求,selenium和phantomjs。
或 使用selenium + phantomjs 进行抓取抓取动态数据,或者找到动态数据加载的json页面。
4. 验证码 :使用打码平台识别验证码
5. 数据加密:对部分数据进行加密的,可以使用selenium进行截图,使用python自带的pytesseract库进行识别,但是比较慢最直接的方法是找到加密的方法进行逆向推理。
144.为什么会用到代理?
一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,
如果访问频率太快以至于看起来不像正常访客,它可能就会禁止这个IP的访问。
所以我们需要设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
145.代理失效了怎么处理?
设置一个代理池(一个列表放了多个代理服务器的ip),实现代理切换等操作,来实现实时使用新的代理 ip,来避免代理失效的问题。
146.列出你知道 header 的内容以及信息
Accept: text/html,image/* -- 浏览器接受的数据类型
Accept-Charset: ISO-8859-1 -- 浏览器接受的编码格式
Accept-Encoding: gzip,compress --浏览器接受的数据压缩格式
Accept-Language: en-us,zh- --浏览器接受的语言
Host: www.it315.org:80 --(必须的)当前请求访问的目标地址(主机:端口)
If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT --浏览器最后的缓存时间
Referer: http://www.it315.org/index.jsp -- 当前请求来自于哪里
User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0) --浏览器类型
Cookie:name=eric -- 浏览器保存的cookie信息
Connection: close/Keep-Alive -- 浏览器跟服务器连接状态。close: 连接关闭 keep-alive:保存连接。
Date: Tue, 11 Jul 2000 18:23:51 GMT -- 请求发出的时间
147.说一说打开浏览器访问 www.baidu.com 获取到结果,整个流程。
1.浏览器向 DNS 服务器发送 baidu.com 域名解析请求。
2.DNS 服务器返回解析后的 ip 给客户端浏览器,浏览器想该 ip 发送⻚⾯请求。
3. DNS 服务器接收到请求 后,查询该⻚⾯,并将⻚⾯发送给客户端浏览器。
4. 客户端浏览器接收到⻚⾯后,解析⻚⾯中的引⽤,并再 次向服务器发送引⽤资源请求。
5. 服务器接收到资源请求后,查找并返回资源给客户端。
6.客户端浏览器接收 到资源后,渲染,输出⻚⾯展现给⽤户。
148.爬取速度过快出现了验证码怎么处理
1.控制抓取速度,定时或随机sleep
2.定时或定量切换ip地址
3.绕过验证码
在爬虫的时候遇到各种需要登录网址,也有验证码。就会手工的吧cookie信息复制下来,加到请求头上就可以了。
4.将许多验证码解算器集成到他的爬虫系统中。
例如,验证码识别服务供应商 Death by CAPTCHA 和 Bypass CAPTCHA 都允许用户通过调用API服务来进行自动打码,从而在抓取数据过程中自动解决验证码。
5.直面验证码:
将验证码返回打码,可采用人工或者打码平台
149.scrapy 和 scrapy-redis 有什么区别?为什么选择 redis 数据库?
主要区别
1. scrapy是一个Python爬虫框架,爬取效率极高,具有高度定制性,但是不支持分布式。
2. scrapy-redis一套基于redis数据库、运行在scrapy框架之上的组件,可以让scrapy支持分布式策略,
Slaver端共享Master端redis数据库里的item队列、请求队列和请求指纹集合。
选择 redis 数据库
因为redis支持主从同步,而且数据都是缓存在内存中的,所以基于redis的分布式爬虫,对请求和数据的高频读取效率非常高。
150.分布式爬虫主要解决什么问题
给爬虫加速。
1. 解决了单个 ip 的限制,
2. 宽带的影响,
3. 以及 CPU 的使用情况
4. 和 io 等一系列操作
151.写爬虫是用多进程好?还是多线程好?为什么?
IO密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率
(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。
在实际的数据采集过程中,既考虑网速和响应的问题,也需要考虑自身机器的硬件情况,来设置多进程或多线程
更多情况下爬虫适合多线程,爬虫是对网络操作属于 io 密集型操作适合使用多线程或者协程。
152.解析网页的解析器使用最多的是哪几个
常见的python网页解析工具有:
1. re正则匹配
2. python自带的html.parser模块
3. 第三方库BeautifulSoup(重点学习)
4. 以及lxml库。
153.需要登录的网页,如何解决同时限制 ip,cookie,session(其中有一些是动态生成的)在不使用动态爬取的情况下?
解决限制IP可以使用代理IP地址池、服务器;
不适用动态爬取的情况下可以使用反编译JS文件获取相应的文件,
或者换用其它平台(比如手机端)看看是否可以获取相应的json文件。
154.验证码的解决(简单的:对图像做处理后可以得到的,困难的:验证码是点击,拖动等动态进行的?)
- 图形验证码:干扰、杂色不是特别多的图片可以使用开源库 Tesseract 进行识别,太过复杂的需要借助第三方打码平台。
对于有嘈杂背景的验证码
- 转化成灰度图
- 去背景噪声
- 图片分割
2. 点击和拖动滑块验证码可以借助 selenium、无图形界面浏览器(chromedirver 或者 phantomjs)和 pillow 包来模拟人的点击和滑动操作,pillow 可以根据色差识别需要滑动的位置。
155.使用最多的数据库(mysql,mongodb,redis 等),对他的理解?
MySQL数据库:开源免费的关系型数据库,需要实现创建数据库、数据表和表的字段,表与表之间可以进行关联(一对多、多对多),是持久化存储。
mongodb数据库:是非关系型数据库,数据库的三元素是,数据库、集合、文档,可以进行持久化存储,也可作为内存数据库,存储数据不需要事先设定格式,数据以键值对的形式存储。
redis数据库:非关系型数据库,使用前可以不用设置格式,以键值对的方式保存,文件格式相对自由,主要用与缓存数据库,也可以进行持久化存储。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









