




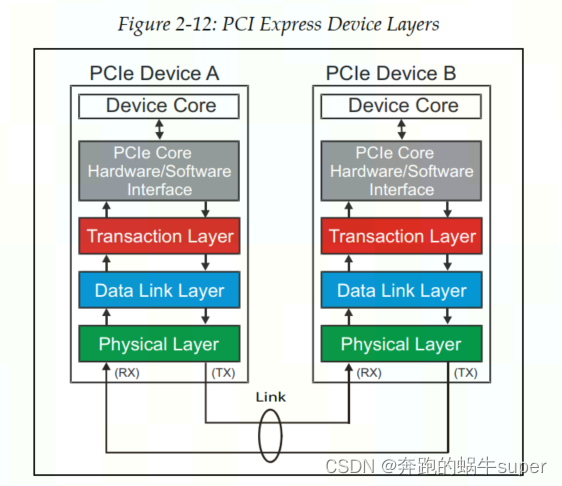
PCIe分层
PCIe定义了以下三层结构:
事务层(Transaction Layer)
数据链路层(Data Link Layer)
和物理层(Physical Layer)
事务层(Transaction Layer):主要职责是创建(发送)或者解析(接收)TLP (Transaction Layer packet),流量控制,QoS,事务排序等
数据链路层(Data Link Layer):主要职责是创建(发送)或者解析(接收)DLLP(Data Link Layer packet),Ack/Nak协议(链路层检错和纠错),流控,电源管理等。
物理层(Physical Layer):主要职责是处理所有的Packet数据物理传输,发送端数据分发到各个Lane传输,接收端把各个Lane上的数据汇总起来,每个Lane上加扰(Scramble,目的是让0和1分布均匀,去除信道的电磁干扰EMI)去扰(De-scramble),以及8/10或者128/130编码解码,等等。此外,物理层还实现了链路训练(Link Training)和链路初始化(Link Initialization)的功能,这一般是通过链路训练状态机(Link Training and Status State Machine,LTSSM)来完成的。
事务层
事务层处理的事务使用TLP(事务层数据包),可以分为四类请求:
- Memory
- IO
- Configuration
- Messages
其中,前三种都是从PCI/PCI-X总线中继承过来的,第四种Messages是PCIe新增加的类型。详细的信息如下表所示:
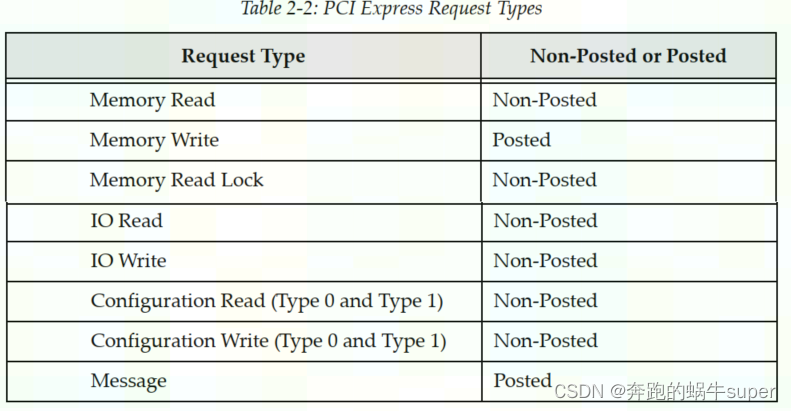
只有Memory Write和Message是Posted类型的,其他的都是Non-Posted类型的。
Non-posted,就是Requester发送了一个包含Request的包之后,必须要得到一个包含Completion的包的应答,这次传输才算结束,否则会进行等待。
Posted,就是Requester的请求并不需要Completer通过发送包含Completion的包进行应答,当然也就不需要进行等待了。很显然,Posted类型的操作对总线的利用率(效率)要远高于Non-Posted型。
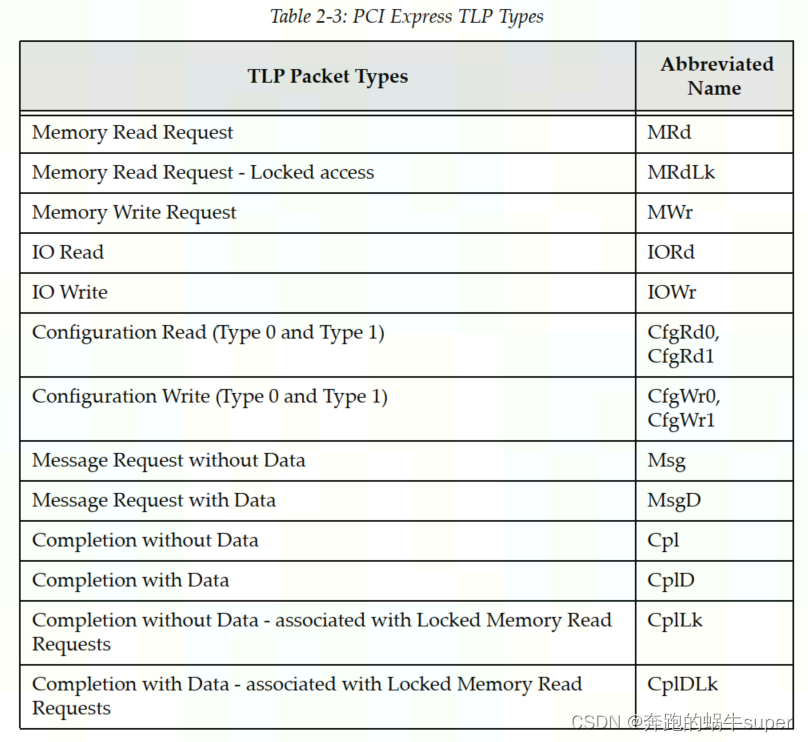
TLP类型:
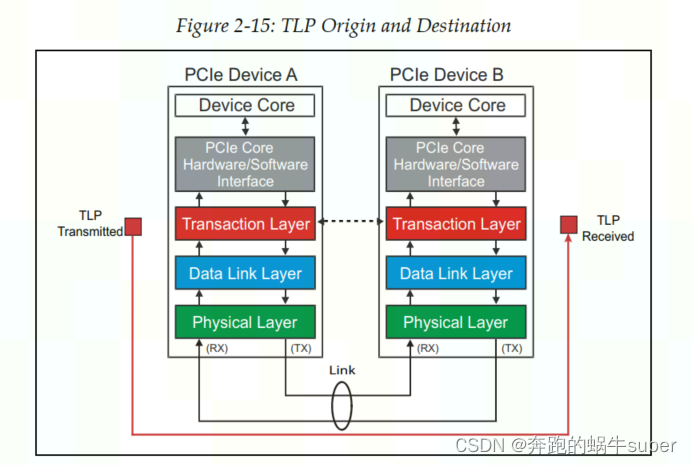
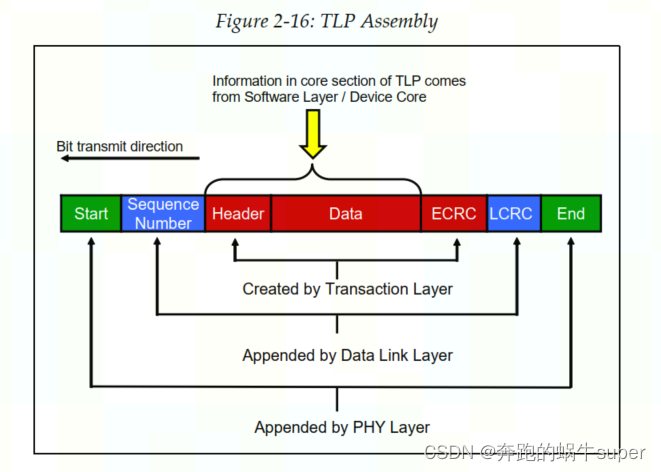
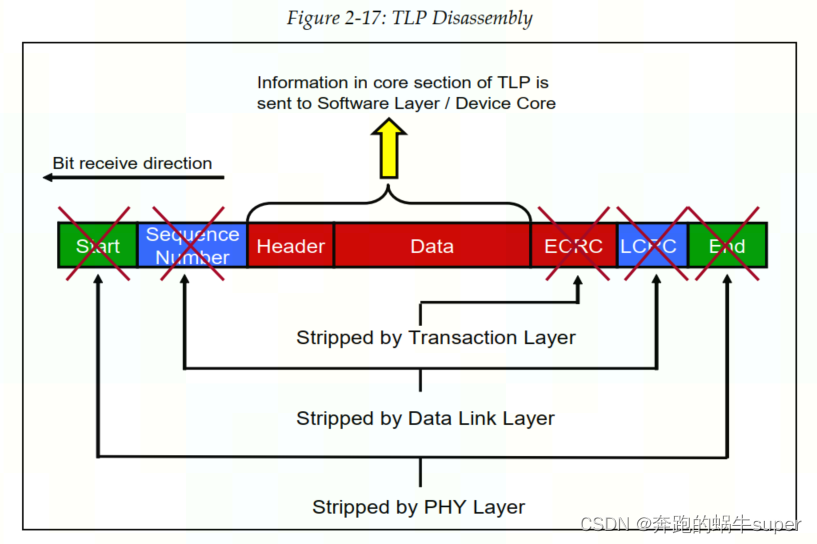
如下图,数据链路层和物理层在数据包通过发送器各层时为其添加部分内容,然后在接收端验证这些部分是否在链路上正确传输。
TLP Packet Assembly
TLP Packet Disassembly
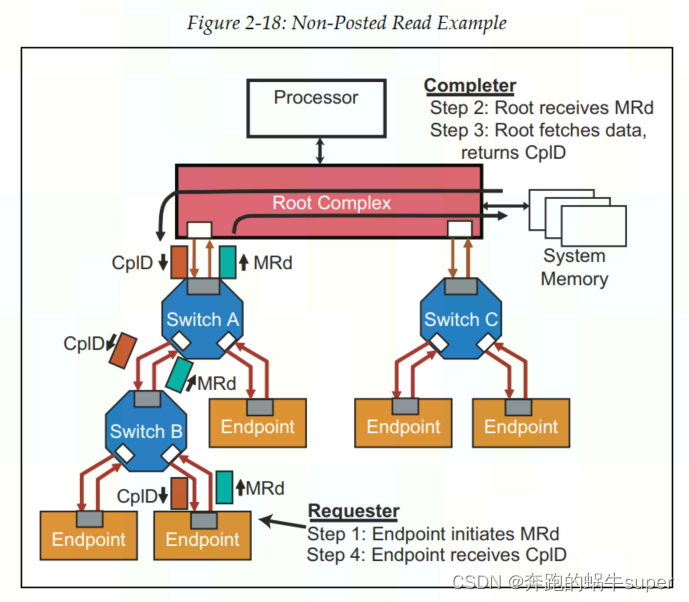
Non-Posted Transactions
Ordinary Reads (普通读)
下图显示的是一个Endpoint向System Memory发送读请求(Read Request)的例子。
Endpoint的读请求通过了两个Switch,然后到达其目标,即Root。Root对读请求的包进行解码后,并从中识别出操作的地址,然后锁存数据,并将数据发送至Endpoint,即包含数据的Completion包,ClpD
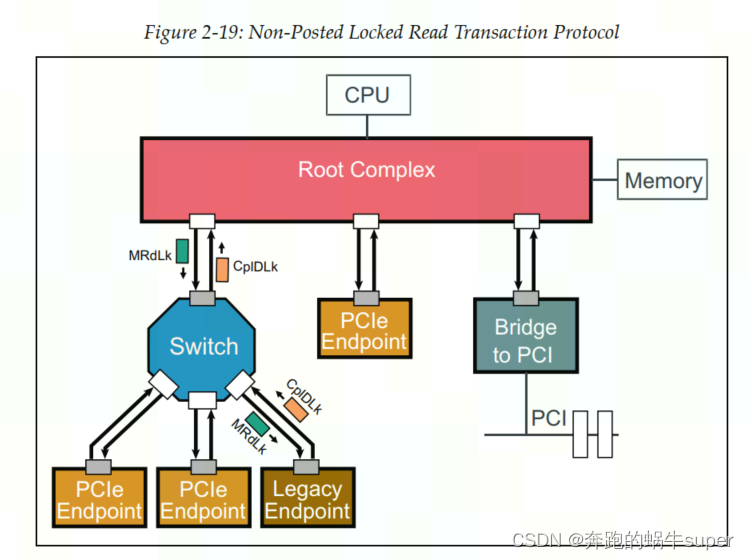
Locked Reads
Locked请求实际上是PCIe为了兼容早期的PCI总线而设置的一种方式,对于非PCI兼容的设计中,是不允许使用Locked操作的。并且也只有Root可以发起Locked请求操作,Endpoint是不可以发起Locked请求操作的。下图显示的是一个简单的Locked Read请求操作:
IO and Configuration Writes
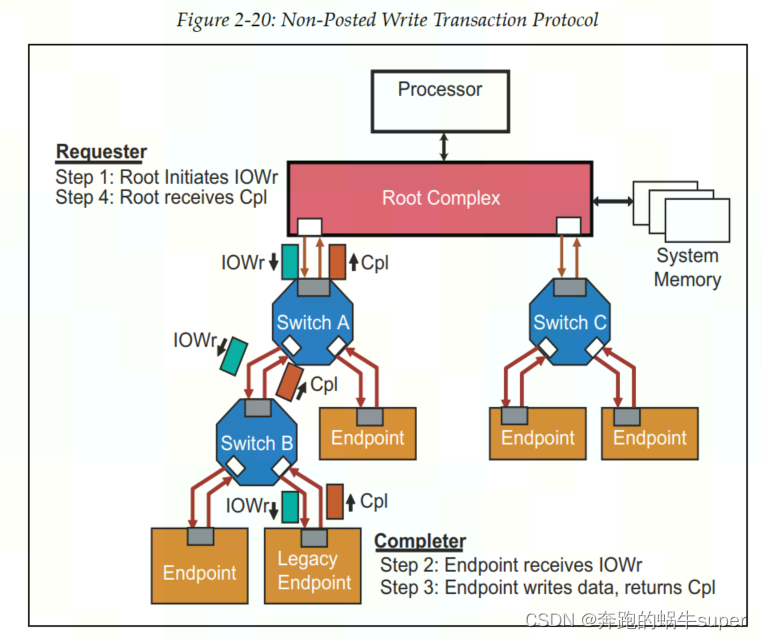
下图是一个Non-Posted IO写操作的例子。和Locked操作一样,IO操作也是为了兼容早期的PCI设备,在PCIe设备中也是不建议使用。
Posted Writes
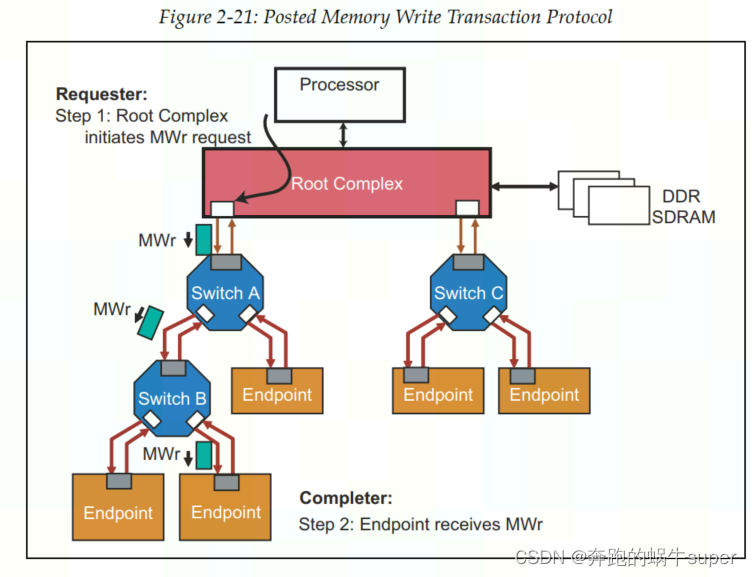
Memory Writes
PCIe中的Memory写操作都是Posted的,因此Requester并不需要来自Completer的Completion。
因此没有返回Completion,所以当发生错误时,Requester也不会知道。但是,此时Completer会将错误记录到日志(Log),然后向Root发送包含错误信息的Message。
Message Writes
和其他的几种类型不太一样,Message支持多种Routing方式。比如Requester可以将Message发送至一个指定的Completer,但是不管指定的Completer是不是Root,Root都会自动的收到来自任何一个Endpoint发送的Message。此外,当Requester是Root的时候,Requester还可以向所有的Endpoint进行广播发送Message。
Message机制的提出帮助PCIe总线省去了很多PCI总线中的边带信号。PCI中很多用于中断、功耗管理、错误报告的边带信号,在PCIe中都通过了Message来进行实现了。
Quality of Service (QoS)
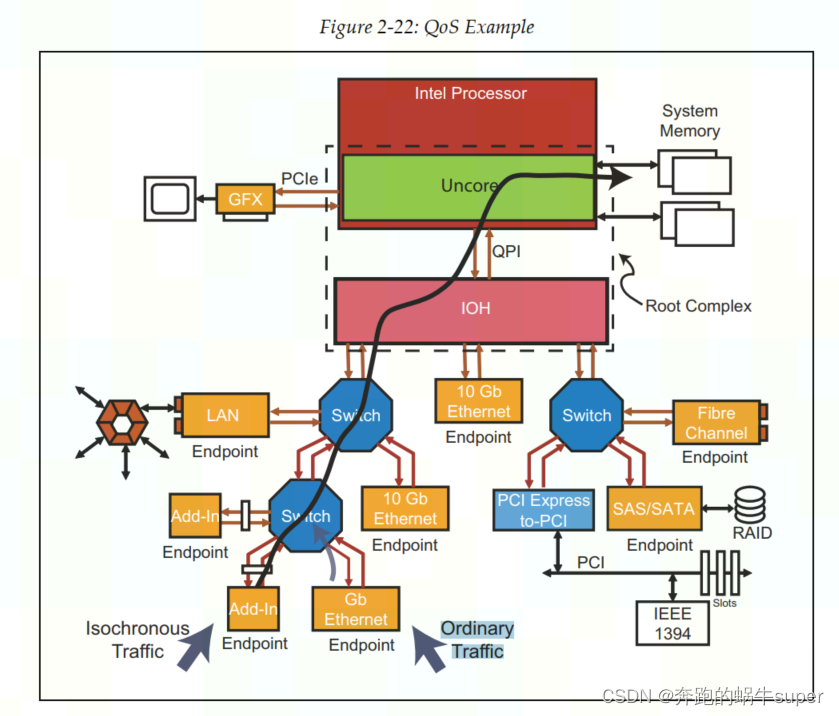
PCIe总线设计之初,充分考虑到了音频和视频传输等这些对时间要求特别敏感的应用。为了保证这些特殊应用的数据包能够得到优先发送,PCIe Spec中为每一个包都分配了一个优先级,通过TLP的Header中的3位(即TC,Traffic Class)

TC值越大,表示优先级越高,对应的包也就会得到优先发送。一般来说,支持QoS(Quality of Service)的PCIe总线系统,对于每一个TC值都会有一个独立Virtual Channel(VC)与之对应。这个Virtual Channel实际上就是一个Buffer,用于缓存数据包。
数据链路层
数据链路层不仅可以转发来自事务层的包(TLP),还可以直接向另一个相邻设备的数据链路层直接发送DLLP,比如应用于Flow Control和Ack/Nak的DLLP。如下图所示:
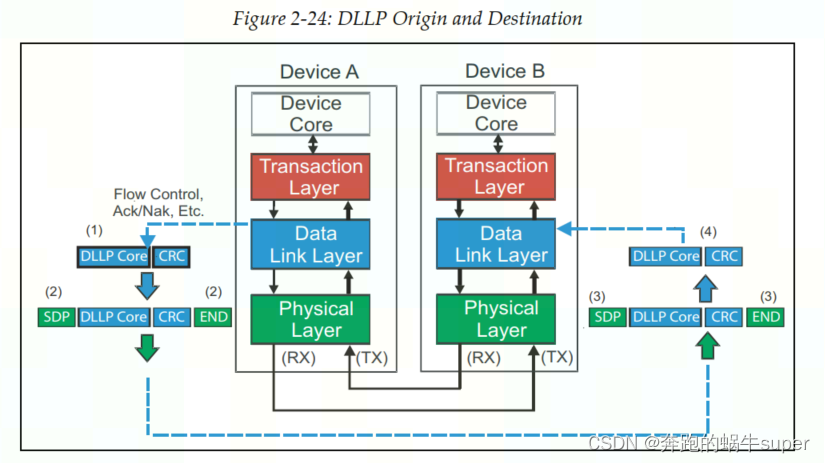
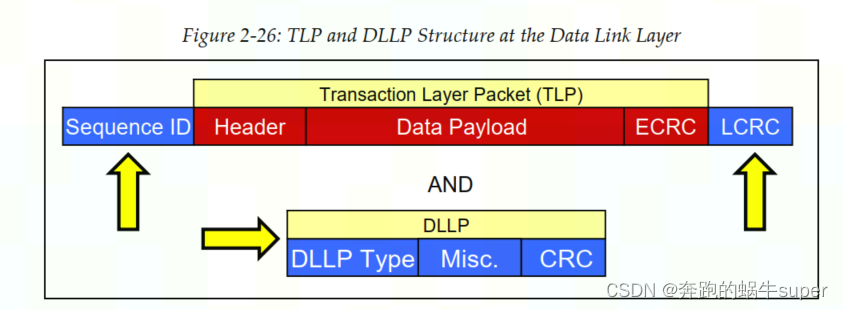
DLLP组装。
如上图,DLLP起源于数据链路层,并被接收器的数据链路层消耗。一个16位的CRC被添加到DLLP核心,以检查接收器的错误。DLLP内容被转发到物理层,物理层在数据包上附加一个Start和End字符,然后编码并使用所有可用的通道在链路上传输它。
DLLP拆卸。
当物理层接收到DLLP时,对比特流进行解码,并删除开始帧和结束帧字符。数据包的其余部分被转发到数据链路层,该层检查CRC错误,然后根据数据包采取适当的操作。数据链路层是DLLP的目的地,因此它不会被转发到事务层。
Ack/Nak
数据链路层还实现了一种自动的错误校正功能,即Ack/Nak机制。如下图所示,发送方会对每一个TLP在Replay Buffer中做备份,直到其接收到来自接收方的Ack DLLP,确认该DLP已经成功的被接受,才会删除这个备份。如果接收方发现TLP存在错误,则会向发送发发送Nak DLLP,然后发送方会从Replay Buffer中取出数据,重新发送该TLP。
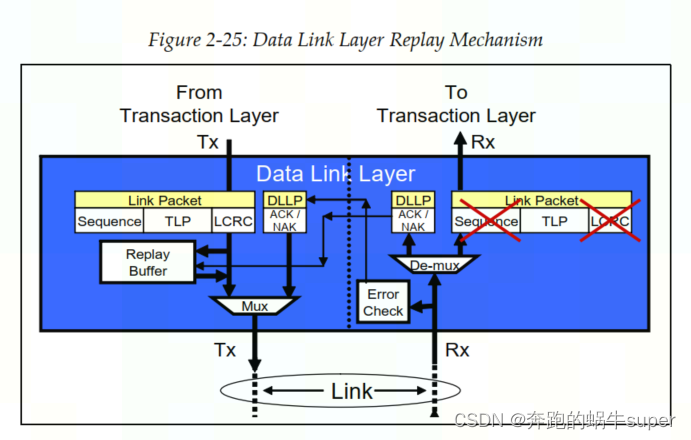
数据链路层的2种包
一种是只在数据链路层传输的DLLP
一种是转发来自事务层的TLP
链路层的第二个主要功能是流量控制。在上电或复位之后,该机制由数据链路层在硬件中自动初始化,然后在运行时更新。
最后,链路层也参与电源管理,因为DLLP用于与链路和系统电源状态相关的请求和握手进行通信。
物理层
物理层处于PCIe体系结构中的最底层,所以无论是TLP还是DLLP都必须通过物理层完成收发操作。来自数据链路层的TLP和DLLP都会被临时放入物理层的Buffer中,并被加上起始字符(Start & End Characters),这些起始字符有的时候也被称为帧字符(Frame Characters)。具体如下图所示:
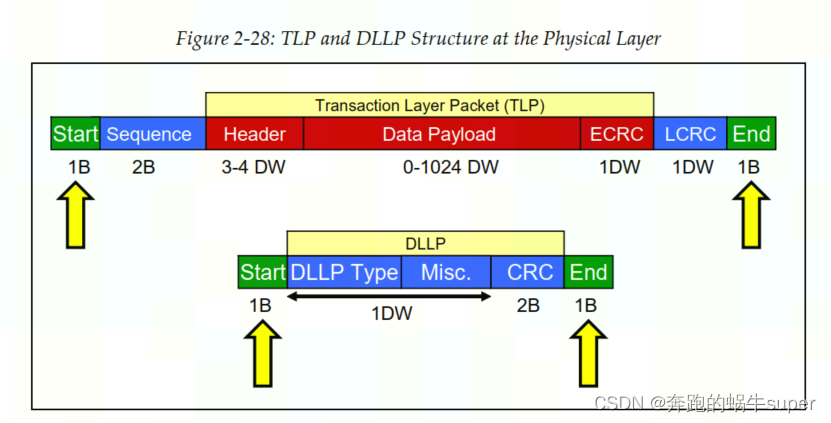
物理层完成的一个重要的功能就是8b/10b编码和解码(Gen1 & Gen2),Gen3及之后的PCIe则采用了128b/130b的编码和解码机制。
物理层的另一个重要的功能时进行链路(Link)的初始化和训练(Initialization & Training),且是完全自动的操作,并不需要人为的干预。完成链路的初始化和训练之后,便可以确定当前PCIe设备的一些基本属性:
• Link width
• Link data rate
• Lane reversal ‐ Lanes connected in reverse order
• Polarity inversion ‐ Lane polarity connected backward
• Bit lock per Lane ‐ Recovering the transmitter clock
• Symbol lock per Lane ‐ Finding a recognizable position in the bit‐stream
• Lane‐to‐Lane de‐skew within a multi‐Lane Link
PCIe物理层处理可以转发TLP和DLLP之外,还可以直接发送命令集(Ordered Sets)。之所以称其为命令集,是因为它并不是真正意义上的包(Packet),因为物理层不会为其添加起始字符(Start & End Characters)。并且命令集始于发送端的物理层,结束语接收端的物理层。虽然命令集没有起始字符,但是对于Gen1&Gen2版本的PCIe物理层来说,会为其添加一个叫做COM的字符作为开始字符,随后跟着三个或者更多的信息字符。
命令集(Ordered Sets)的收发示意图,如下图所示:
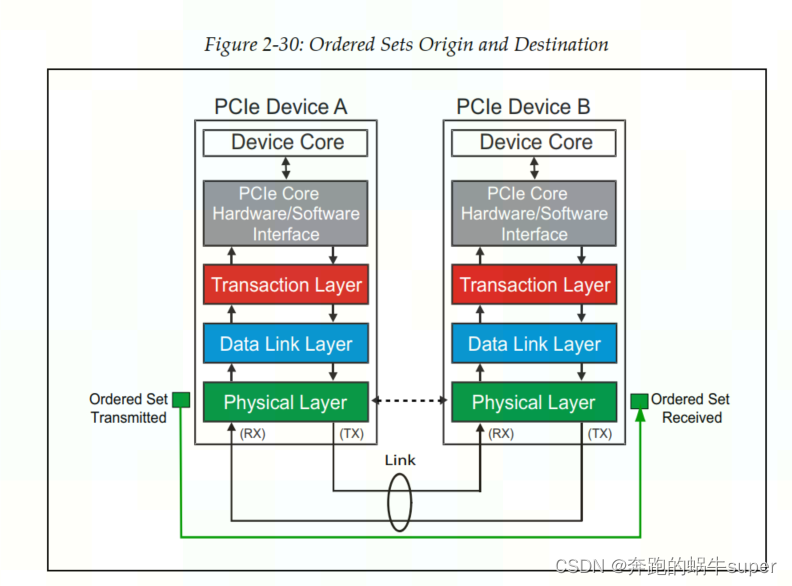
命令集(Ordered Sets)的结构图如下图所示:
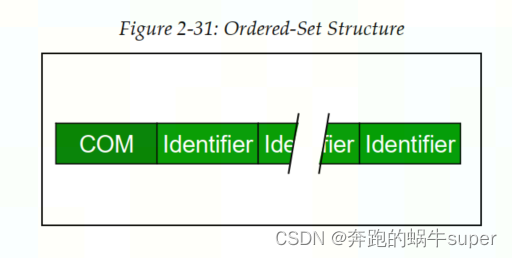
命令集主要用于链路的训练操作(Link Training Process)。此外,命令集还用于链路进入或者退出低功耗模式的操作。
示例
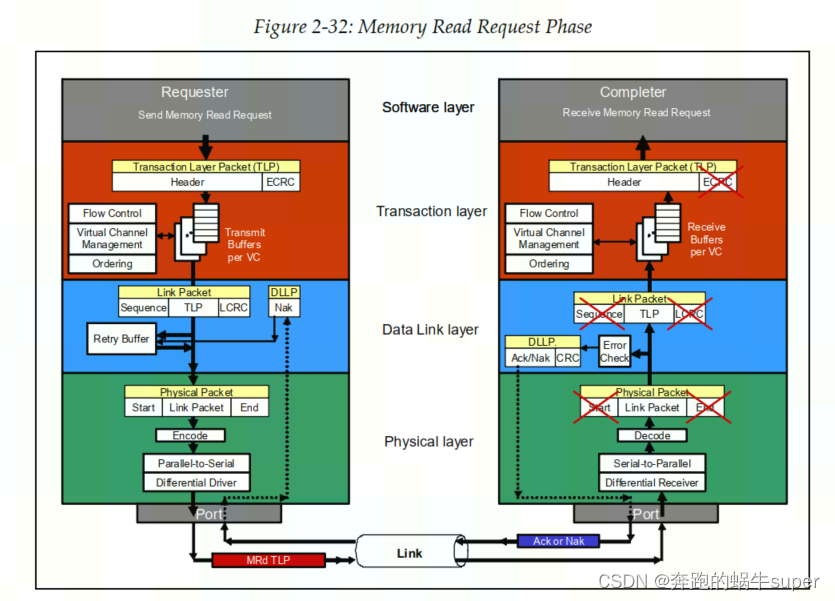
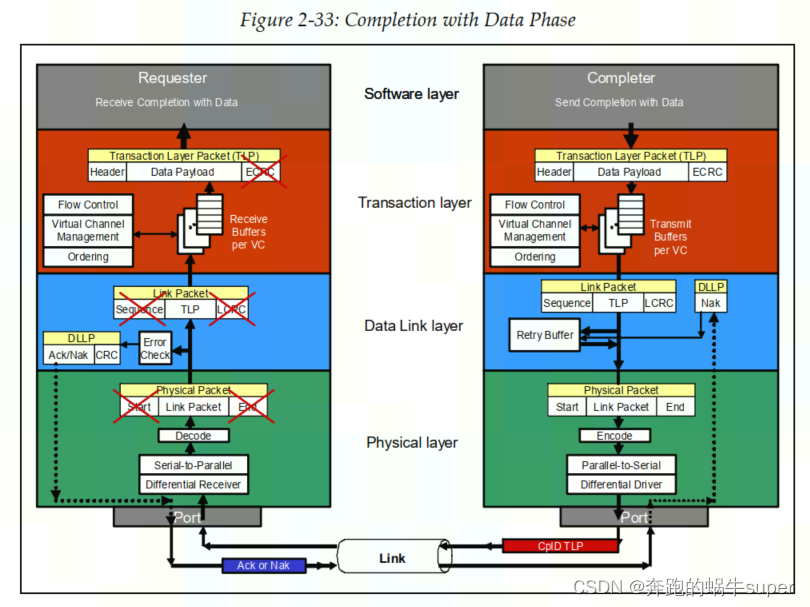
现在,让我们通过一个示例来回顾整个Link协议,以说明从Requester发起内存读取请求到从Completer获得所请求的数据所发生的步骤。
Memory Read Request
Completion with Data
参考链接:
https://blog.youkuaiyun.com/zsmcdut/article/details/120037283
https://blog.youkuaiyun.com/zsmcdut/article/details/120037261
https://blog.youkuaiyun.com/zsmcdut/article/details/120037299

















 1324
1324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









