




 本文介绍了单精度FP32、半精度FP16和INT8在计算性能、精度和存储上的特点,以及混合精度策略的应用,重点讨论了这些在AI计算特别是深度学习任务中的优势与局限性,以及可能存在的溢出风险。
本文介绍了单精度FP32、半精度FP16和INT8在计算性能、精度和存储上的特点,以及混合精度策略的应用,重点讨论了这些在AI计算特别是深度学习任务中的优势与局限性,以及可能存在的溢出风险。
FP32
FP32 是单精度浮点数,用8bit 表示指数,23bit 表示小数,占用4字节;
提供了较高的精度和动态范围,适用于大多数科学计算和通用计算任务。
位数说明(32 bits)
符号位(sign):1 bit
指数位(exponent):8 bits
尾数位(fraction):24 bits (23 explicitly stored)

FP16
FP16半精度浮点数,用5bit 表示指数,10bit 表示小数,占用2字节;
与FP32相比,FP16的访存消耗仅为1/2,也因此FP16是更适合在移动终端侧进行AI计算的数据格式。
相对于FP32提供了较低的精度,但可以减少存储空间和计算开销。主要应用于深度学习和机器学习等计算密集型任务。
位数说明(16 bits)
符号位(sign):1 bit
指数位(exponent):5 bits
尾数位(fraction):11 bits (10 explicitly stored)


INT8
INT8,八位整型占用1个字节,INT8是一种定点计算方式,代表整数运算,一般是由浮点运算量化而来。在二进制中一个“0”或者“1”为一bit,INT8则意味着用8bit来表示一个数字。因此,虽然INT8比FP16精度低,但是数据量小、能耗低,计算速度相对更快,更符合端侧运算的特点;
主要用于对图像、音频等进行量化处理,以减少计算量和存储需求。
位数说明(8 bits)
最高位代表符号位(0 - 正,1 - 负)
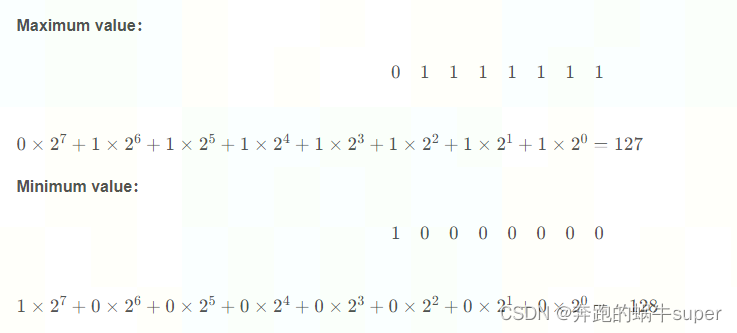

混合精度
简单的讲就是使用fp16进行乘法和存储,只使用fp32进行加法操作,避免累加误差;
在数据表示范围上,FP32和FP16 表示的整数范围是一样的,小数部分表示不一样,存在舍入误差;FP32和FP16 表示的数据范围不一样,在大数据计算中,FP16存在溢出风险。
参考:
https://blog.youkuaiyun.com/weixin_43795765/article/details/120590215
https://blog.youkuaiyun.com/m0_70885101/article/details/131555760

















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









