






一、我们为什么要用BN?
在神经网络的反向传播过程中,每层权重的更新都是在假定其他层权重不变的情况下,向损失函数降低的方向调整自己。但是问题在于,一次反向传播过程,所有的权重都在同时更新,都在向着自己觉得降低损失函数的方向上更新,这样做难免会导致各层之间没有默契,并且层数越多,配合越不默契。这种现象在BN论文中称作Internal Covariate Shift(内部协变量偏移)。为了防止震荡,不得不将学习率调的很低,但是却意味着学习很慢。
我们在输入图像的时候,预处理会将图像变成一个具有某些分布特征的矩阵,但是经过一个conv操作后生成的特征图就不一定满足这个分布特征了。(比如均值为0,方差为1的分布规律)
网络学习的过程的本质就是学习数据分布,一旦训练数据和测试数据的分布不同,那么网络的泛化能力就会大大降低,另外一方面,每一批次的数据分布如果不相同的话,那么网络就要在每次迭代的时候都去适应不同的分布,这样会大大降低网络的训练速度,另外对图片进行归一化处理还可以处理光照,对比度等影响。
三、BN带来的好处?
BN的作用是可以加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失。并且起到一定的正则化作用,几乎代替了Dropout。
Batch Normalization的目的就是使我们的feature map满足均值为0,方差为1的分布规律
二、BN公式详解
建议在每个ReLU后面(论文中建议放在激活函数前面)
一个神经网络有m个batch,每个节点就有m个输出,BN就是对这m个输出进行归一化再操作。
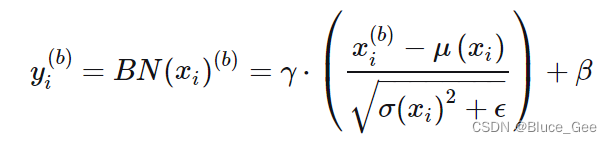
1.先对一组数据求均值μ
2.再对这组数据求方差std
3.再对每一组数据进行标准化(上述公式括号里,分母加一个极小的数值,防止分母为0的作用)
4.乘以一个可学习的参数γ,加上一个可学习的参数β,默认为1和0
Batch Normalization还包含两个可学习的参数,用于在标准化处理后进行缩放和平移,以恢复数据的原始分布特性。这两个参数是在反向传播过程中学习得到的,默认值分别为1和0。
四、我们怎么用?
只讲解BN2d
神经网络模块存在两种模式: train模式( **net.train() ** ) 和eval模式( net.eval() ),一般的神经网络中,这两种模式是一样的,只有当模型中存在dropout和batchnorm的时候才有区别。
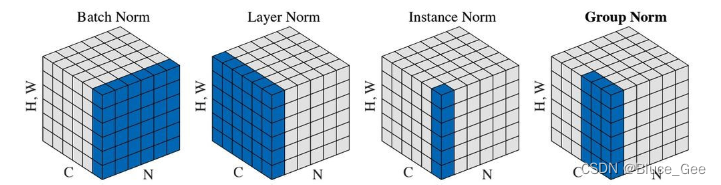
首先,我们输入的图像数据大多数都是B,C,H,W四维的,我们看上图最左侧立方体,我们先把H和W维度给view成一个维度,这样就变成了一个B,C,H*W的三维数组。
import torch
import torch.nn as nn
class BatchNorm2d(nn.Module):
def __init__(self, num_features, eps=1e-5, momentum=0.1):
super(CustomBatchNorm2d, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
# 初始化可学习的scale和shift参数
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
# 初始化运行均值和方差
self.running_mean = torch.zeros(num_features)
self.running_var = torch.ones(num_features)
# 如果在训练模式下,使用这些变量来跟踪当前小批量的统计量
self.register_buffer('num_batches_tracked', torch.tensor(0, dtype=torch.long))
def forward(self, x):
if self.training:
# 计算当前小批量的均值和方差
batch_mean = x.mean(dim=[0, 2, 3], keepdim=True)
batch_var = x.var(dim=[0, 2, 3], keepdim=True)
# 更新运行均值和方差
self.running_mean = self.momentum * self.running_mean + (1 - self.momentum) * batch_mean.detach()
self.running_var = self.momentum * self.running_var + (1 - self.momentum) * batch_var.detach()
# 归一化数据
x_norm = (x - batch_mean) / torch.sqrt(batch_var + self.eps)
else:
# 使用运行均值和方差进行归一化
x_norm = (x - self.running_mean.unsqueeze(0).unsqueeze(2).unsqueeze(3)) / torch.sqrt(self.running_var.unsqueeze(0).unsqueeze(2).unsqueeze(3) + self.eps)
# 应用可学习的scale和shift参数
x_transformed = self.weight.unsqueeze(0).unsqueeze(2).unsqueeze(3) * x_norm + self.bias.unsqueeze(0).unsqueeze(2).unsqueeze(3)
# 更新跟踪的小批量数量
if self.training:
self.num_batches_tracked += 1
return x_transformed若是我们直接使用pytorch框架里面的nn.BatchNorm2d,当你定义模型时,你可以在卷积层之后添加 nn.BatchNorm2d 层。它接受几个参数,但最重要的是 num_features,它应该与上一层的输出通道数(即特征映射的数量)相匹配。
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(64) # 注意这里的64要与conv1的输出通道数匹配
self.relu = nn.ReLU(inplace=True)
# ... 其他层 ...
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
# ... 通过其他层传递x ...
return xnn.BatchNorm2d 的主要参数包括:
- num_features (int) - 输入数据的特征数量,即输入的通道数。这通常与上一个卷积层的输出通道数相匹配。
- eps (float, optional) - 添加到分母的一个小的正值,以确保数值稳定性。当分母(即方差)非常接近零时,它可以防止除以零的错误。默认值通常为
1e-5。 - momentum (float, optional) - 用于计算运行平均值(running mean)和运行方差(running variance)的动量参数。它决定了之前批次统计信息的权重。默认值通常为
0.1。注意,这个动量参数与优化器中的动量参数是不同的。 - affine (bool, optional) - 一个布尔值,如果设置为
True,则此模块具有可学习的仿射参数(gamma和beta)。这些参数允许批量归一化层在归一化之后对数据进行缩放和偏移。默认值通常为True。 - track_running_stats (bool, optional) - 一个布尔值,如果设置为
True,则在训练期间计算并存储运行平均值和运行方差,并在评估时使用它们。如果设置为False,则不会跟踪这些统计信息,而是在评估时使用每个批次的统计信息。默认值通常为True。
此外,nn.BatchNorm2d 还有两个可学习的参数:
- weight (gamma) (Tensor) - 可学习的缩放参数,其大小与输入数据的特征数量相同。
- bias (beta) (Tensor) - 可学习的偏移参数,其大小与输入数据的特征数量相同。
这两个参数仅在 affine=True 时有效。在训练过程中,它们通过反向传播进行更新。
五、拓展
除BN外,如上图所示 还有Layer Norm、Instance Norm、Group Norm,由图像能够进行类比学习。
注:Layer Norm和Instance Norm分别是Group Norm的两种极端形式。


















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









