






残差网络
残差、误差概念
统计学里残差的概念是:模型预测值与实验观测值之差(只针对于回归模型)。
这里明确一点就是,模型预测值就是通过数学方法构建的模型本身。可以想象一下,线性回归模型,就是通过数学方法拟合出来的一条直线,这条直线就是模型预测值!那么实验观测值是什么呢?观测值就是数据!仍然以线性回归模型为例,观测值就是分布在直线周围的那些数据点。
计算残差时,模型已经确定,是不发生变化的,而数据是根据实验次数的不同要发生变化的,即每次实验取不同的数据。
误差的概念比较绕,我总结如下(不一定准确,只是我个人通过学习和理解得出的主观想法):
仍然以线性回归模型为例,我们知道模型训练过程中,会不断调整参数w和b,每训练一轮,模型都会计算一个“误差”,这个“误差”是所有数据点的残差的加和,我们可以将训练的轮数看作是实验的次数,那么误差就是,在同一批数据下训练模型(做实验)时,实验观测值(此时模型会根据训练轮数的不同而发生变化,模型预测值可以看作是实验观测值)与数据真值(由于训练时数据保持不变,所以此时数据观测值可以看作是真值)之差。
综上所述,可以将误差和残差的计算看作是两个过程:误差的计算是在模型训练过程中,而残差的计算是在模型测试过程中(个人理解)。
残差网络概述
残差体现在了哪里?
模型最终预测值:
H
(
x
)
H(x)
H(x)
输入数据:
x
x
x
模型预测值:
F
(
x
)
F(x)
F(x)
三者之间的关系:
H
(
x
)
=
x
+
F
(
x
)
H(x) = x + F(x)
H(x)=x+F(x)
其中,
F
(
x
)
F(x)
F(x)在论文中被命名为残差,原因是,输入数据
x
x
x可以看作是观测值,而
H
(
x
)
H(x)
H(x)是最终的预测值。
残差网络是如何解决梯度消失的?
首先,残差网络可以近似的表示为如下形式(没有激活函数的情况):
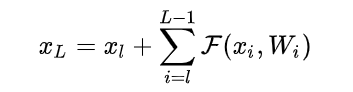
其中,L表示网络共有L层,l表示第l层
那么梯度反向传播公式可以近似表示如下:
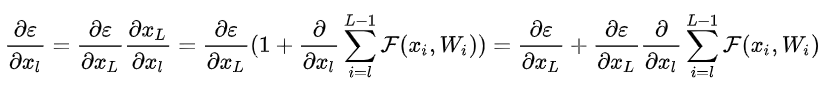
根据上式可以知道,模型对于第l层的梯度中,包含了对第L层的梯度(上式中的第一项),如果中间层的梯度非常小的话(上式中的第二项),那么只要第L层梯度存在,就可以缓解梯度消失的情况(个人理解)。

















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









