







 超级会员免费看
超级会员免费看
 本文详细介绍了Spark On Yarn的Client模式和Cluster模式的运行流程。在Client模式中,Driver在本地运行,向Yarn申请资源,启动Executor执行任务;在Cluster模式下,Driver作为ApplicationMaster在集群内运行,负责任务的调度和执行。两种模式的主要区别在于Driver的运行位置。
本文详细介绍了Spark On Yarn的Client模式和Cluster模式的运行流程。在Client模式中,Driver在本地运行,向Yarn申请资源,启动Executor执行任务;在Cluster模式下,Driver作为ApplicationMaster在集群内运行,负责任务的调度和执行。两种模式的主要区别在于Driver的运行位置。
前言
上篇文章有讨论到Spark On Yarn的两种部署模式,如果有不清楚的地方,可以再看看,附上对应文章的链接:Spark的部署模式,本篇文章主要讨论Spark On Yarn两种部署模式的运行流程。
(一)Spark On Yarn集群的Client模式运行流程
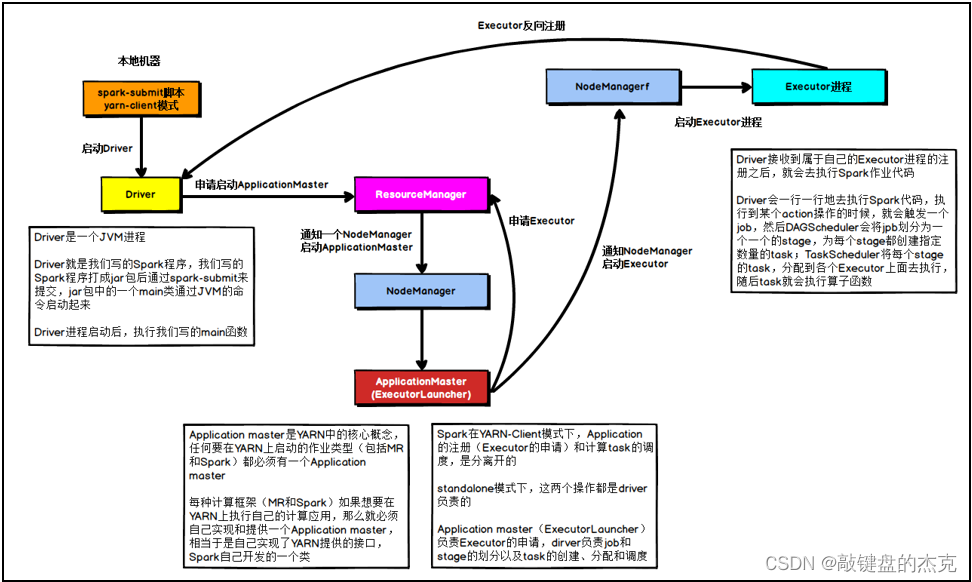
该模式的Driver程序在本地Client端运行;
- 大致流程:先在提交任务的节点上启动Driver程序,然后向Yarn集群申请运行资源,申请到运行资源后开始执行任务;
- 详细流程如下:
(1)在提交任务的节点上启动Driver程序,执行Main函数,创建SparkContext对象
(2)Driver程序启动成功后,向ResourceManager申请启动ApplicationMast

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1300
1300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











