




 本文详细介绍了Spark的基本运行流程,包括DAG的构建、DAG切割、任务调度、Executor执行任务的过程,以及SparkContext初始化、DAGScheduler、TaskScheduler、SchedulerBackend和Executor的角色和功能。此外,还探讨了Spark运行架构的特点,如Application隔离、数据本地性和推测执行优化机制。
本文详细介绍了Spark的基本运行流程,包括DAG的构建、DAG切割、任务调度、Executor执行任务的过程,以及SparkContext初始化、DAGScheduler、TaskScheduler、SchedulerBackend和Executor的角色和功能。此外,还探讨了Spark运行架构的特点,如Application隔离、数据本地性和推测执行优化机制。
目录
1.1、Spark的基本运行流程
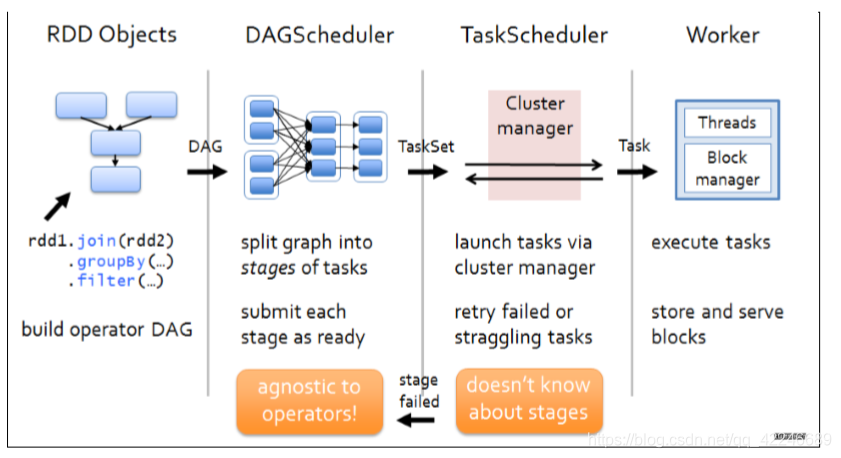
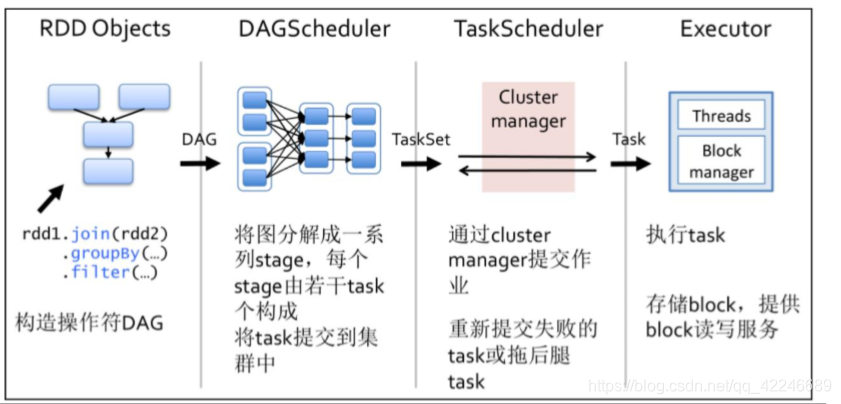
1、构建 DAG
使用算子操作 RDD 进行各种 transformation 操作,最后通过 action 操作触发 Spark 作业运行。 提交之后 Spark 会根据转换过程所产生的 RDD 之间的依赖关系构建有向无环图。
2、DAG 切割
DAG 切割主要根据 RDD 的依赖是否为宽依赖来决定切割节点,当遇到宽依赖就将任务划分 为一个新的调度阶段(Stage)。每个 Stage 中包含一个或多个 Task。这些 Task 将形成任务集 (TaskSet),提交给底层调度器进行调度运行。
3、任务调度
每一个 Spark 任务调度器只为一个 SparkContext 实例服务。当任务调度器收到任务集后负责 把任务集以 Task 任务的形式分发至 Worker 节点的 Executor 进程中执行,如果某个任务失败, 任务调度器负责重新分配该任务的计算。
4、执行任务
当 Executor 收到发送过来的任务后,将以多线程(会在启动 executor 的时候就初始化好了 一个线程池)的方式执行任务的计算,每个线程负责一个任务,任务结束后会根据任务的类 型选择相应的返回方式将结果返回给任务调度器。
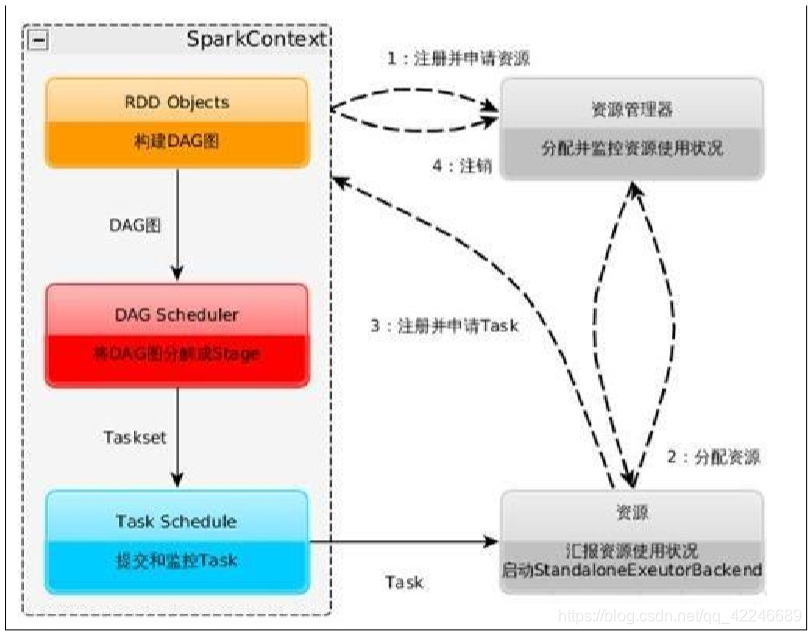
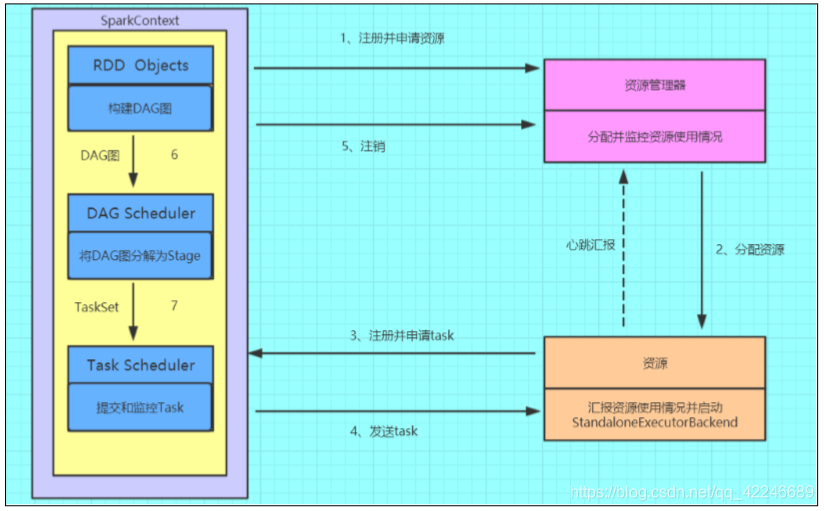
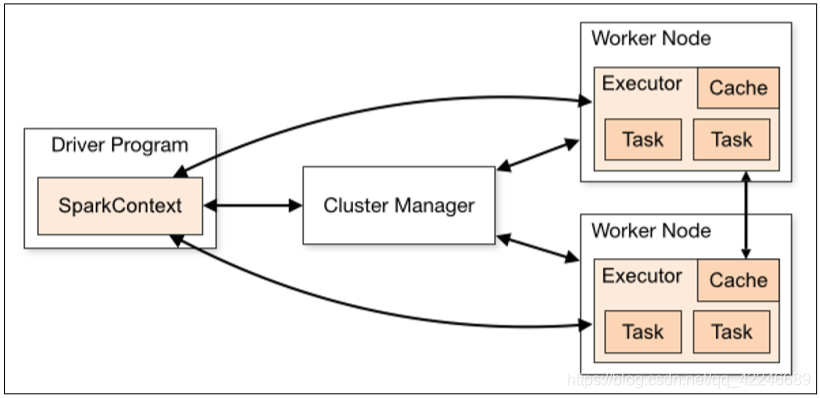
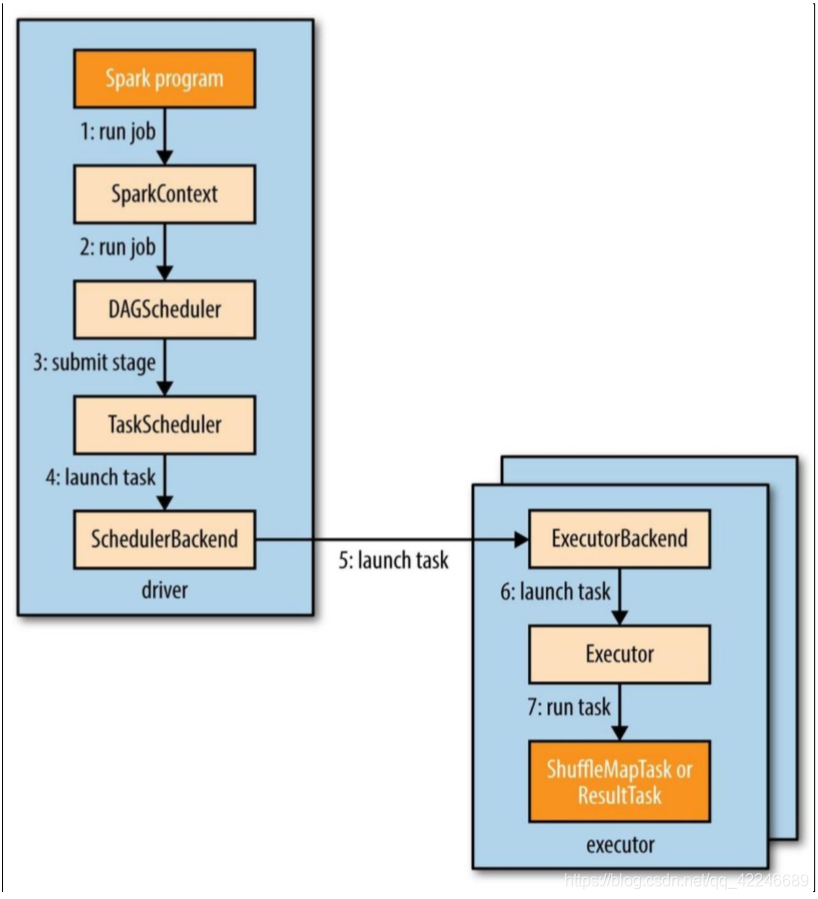
1.2、运行流程图解
1、构建 Spark Application 的运行环境(初始化 SparkContext),SparkContext 向资源管理器(可 以是 Standalone、Mesos 或 YARN)注册并申请运行 Executor 资源
2、资源管理器分配 Executor 资源并启动 StandaloneExecutorBackend,Executor 运行情况将 随着心跳发送到资源管理器上
3、SparkContext 构建成 DAG 图,将 DAG 图分解成 Stage,并把 Taskset 发送给 TaskScheduler。 Executor 向 SparkContext 申请 Task,TaskScheduler 将 Task 发放给 Executor 运行同时 SparkContext 将应用程序代码发放给 Executor
4、Task 在 Executor 上运行,运行完毕释放所有资源。
1.3、SparkContext初始化
关于 SparkContext:
1、SparkContext 是用户通往 Spark 集群的唯一入口,可以用来在 Spark 集群中创建 RDD、累 加器 Accumulator 和广播变量 Braodcast Variable
2、SparkContext 也是整个 Spark 应用程序中至关重要的一个对象,可以说是整个应用程序 运行调度的核心(不是指资源调度)
3、SparkContext在实例化的过程中会初始化DAGScheduler、TaskScheduler和SchedulerBackend
4、SparkContext 会调用 DAGScheduler 将整个 Job 划分成几个小的阶段(Stage),TaskScheduler 会调度每个 Stage 的任务(Task)应该如何处理。另外,SchedulerBackend 管理整个集群中为这 个当前的应用分配的计算资源(Executor)
初始化流程:
1、处理用户的 jar 或者资源文件,和日志处理相关
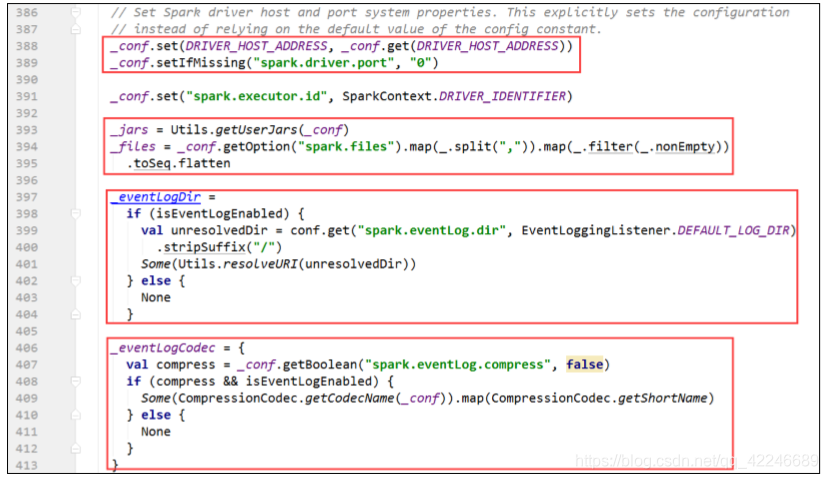
2、初始化异步监听
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









