










 本文深入探讨了DeepFM模型的发展背景,它是为了解决传统模型如EmbeddingMLP、Wide&Deep、NerualCF在特征交叉上的不足而提出的。DeepFM结合了FM的特征交叉能力和深度学习的拟合能力,通过元素积操作实现特征的高效交叉。文章还介绍了优化FM计算效率的方法,并展示了DeepFM的模型结构和代码实现,证明了特征交叉对提升模型预测精度的重要性。
本文深入探讨了DeepFM模型的发展背景,它是为了解决传统模型如EmbeddingMLP、Wide&Deep、NerualCF在特征交叉上的不足而提出的。DeepFM结合了FM的特征交叉能力和深度学习的拟合能力,通过元素积操作实现特征的高效交叉。文章还介绍了优化FM计算效率的方法,并展示了DeepFM的模型结构和代码实现,证明了特征交叉对提升模型预测精度的重要性。
目标:
掌握DeepFM原理,以及发展历程。和具体的代码实现。
华为在 IJCAI’2017 提出的模型DeepFM
产生背景:
产生DeepFM模型的原因:前面学习的Embedding MLP、Wide&Deep、NerualCF 等几种不同的模型结构,都没有用到交叉特征。特征都是一个一个独立的送进模型训练,对于挖掘特征交叉或者特征组合的信息,比较低效。
1、 Embedding MLP是把各个特征,进行了embeding后送进MLP无交叉。直接把独立的特征扔进神经网络,让它们在网络里面进行自由组合。
2、 NerualCF也是仅仅把物品和用户分别进行特征的embeding后,送进MLP。NeuralCF 也只在最后才把物品侧和用户侧的特征交叉起来。
3、 Wide&Deep中Wide部分,有开始意识到需要进行特征交叉,但是仅仅用到了特征组合的multi-hot编码,理论上也不算是特征交叉,叫特征组合吧。
4、 所以,可不可以对Wide&Deep再进行一次改进,让Wide部分学习到更多的特征交叉特性?于是就诞生了DeepFM。模型对于特征组合和特征交叉的学习能力,决定了模型对于未知特征组合样本的预测能力,而这对于复杂的推荐问题来说,是决定其推荐效果的关键点之一。
模型介绍:
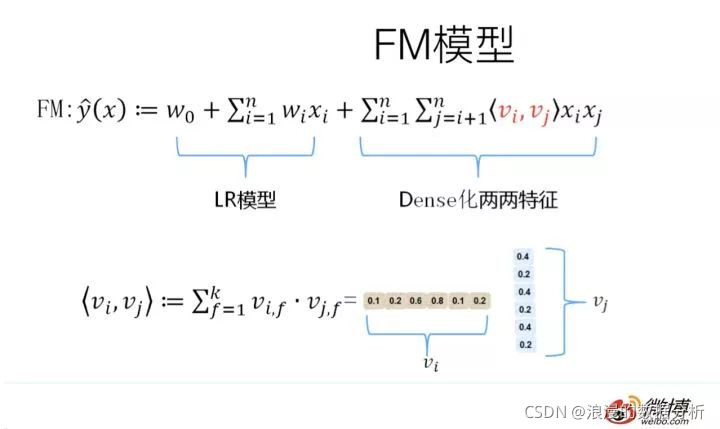
善于处理特征交叉的机器学习模型 FM
解决特征交叉问题的传统机器学习模型,曾经红极一时的机器学习模型因子分解机模型(Factorization Machine)了,简称 FM。
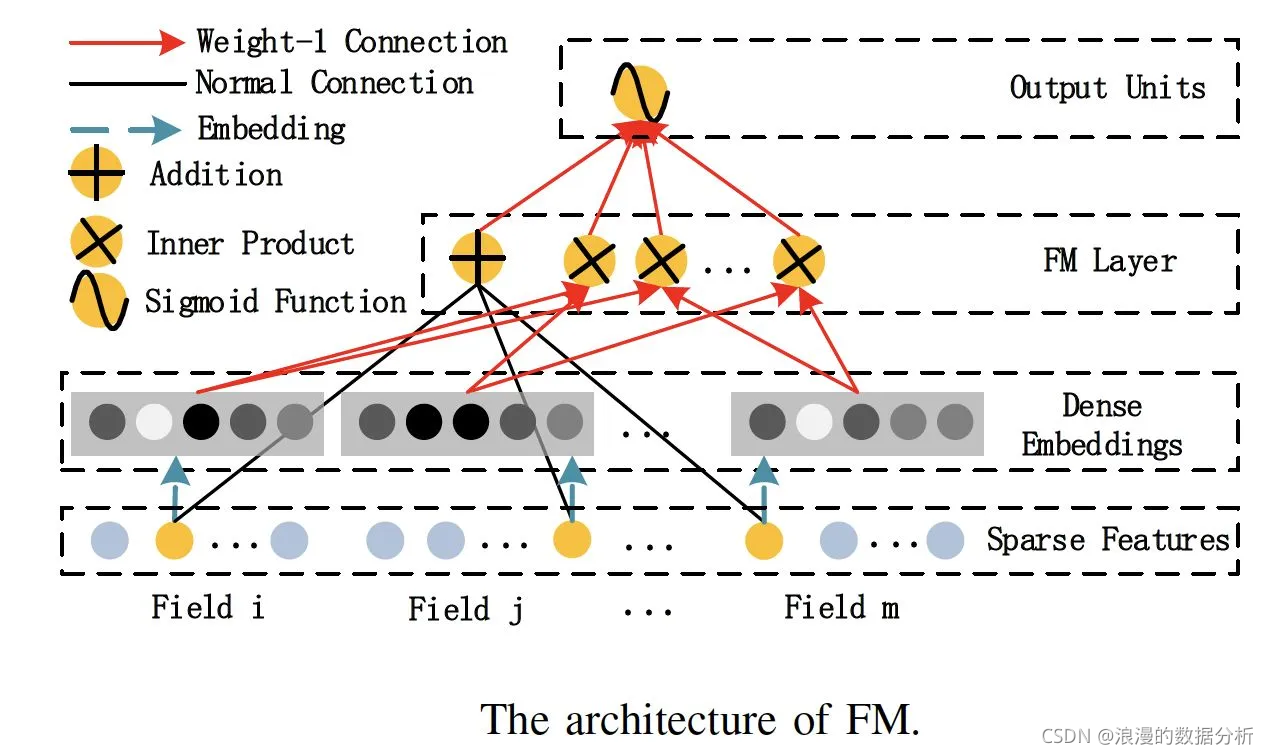
- 它的输入是由类别型特征转换成的 One-hot 向量,往上就是深度学习的常规操作,也就是把 One-hot 特征通过 Embedding 层转换成稠密 Embedding 向量。
- 再往上。FM 会使用一个独特的层 FM Layer 来专门处理特征之间的交叉问题。
- FM 层中有多个内积操作单元对不同特征向量进行两两组合,这些操作单元会把不同特征的内积操作的结果输入最后的输出神经元,以此来完成最后的预测。这样一来,如果我们有两个特征是用户喜爱的风格和电影本身的风格,通过 FM 层的两两特征的内积操作,这两个特征就可以完成充分的组合,不至于像 Embedding MLP 模型一样,还要 MLP 内部像黑盒子一样进行低效的交叉。
可以看到FM部分对一维的特征和二维的特征进行了建模。一维特征是线性加权,二维特征通过隐向量来求出交叉特征的权重。公式如下所示
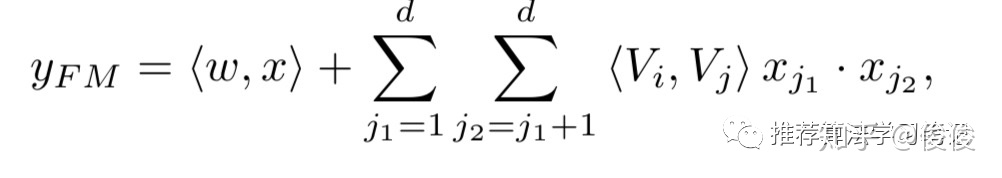
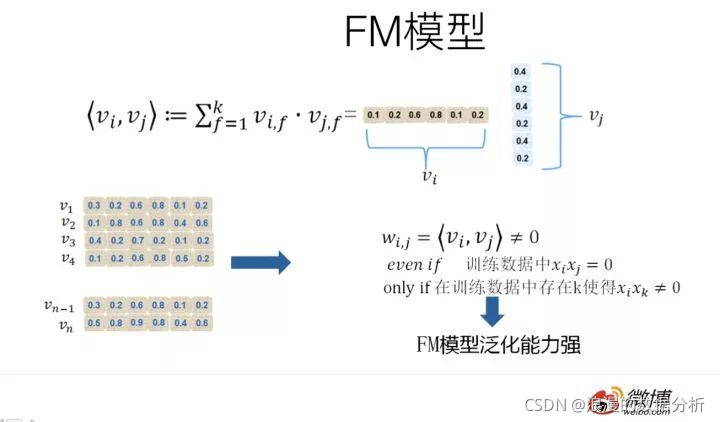
FM的泛化能力强,可以理解为
如何优化FM的计算效率
FM如今被广泛采用并成功替代LR模型的一个关键所在是:它可以通过数学公式改写,把表面貌似是
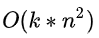
的复杂度降低到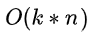
,其中n是特征数量,k是特征的embedding size,这样就将FM模型改成了和LR类似和特征数量n成线性规模的时间复杂度了,这点非常好。

详细的变化过程见链接:https://zhuanlan.zhihu.com/p/58160982?utm_source=ZHShareTargetIDMore&utm_medium=social&utm_oi=40535670652928
我们在真正计算的时候,会采用改造后的公式计算。
深度学习模型和 FM 模型的结合 DeepFM
FM 是一个善于进行特征交叉的模型,深度学习模型的拟合能力强,那二者之间能结合吗?
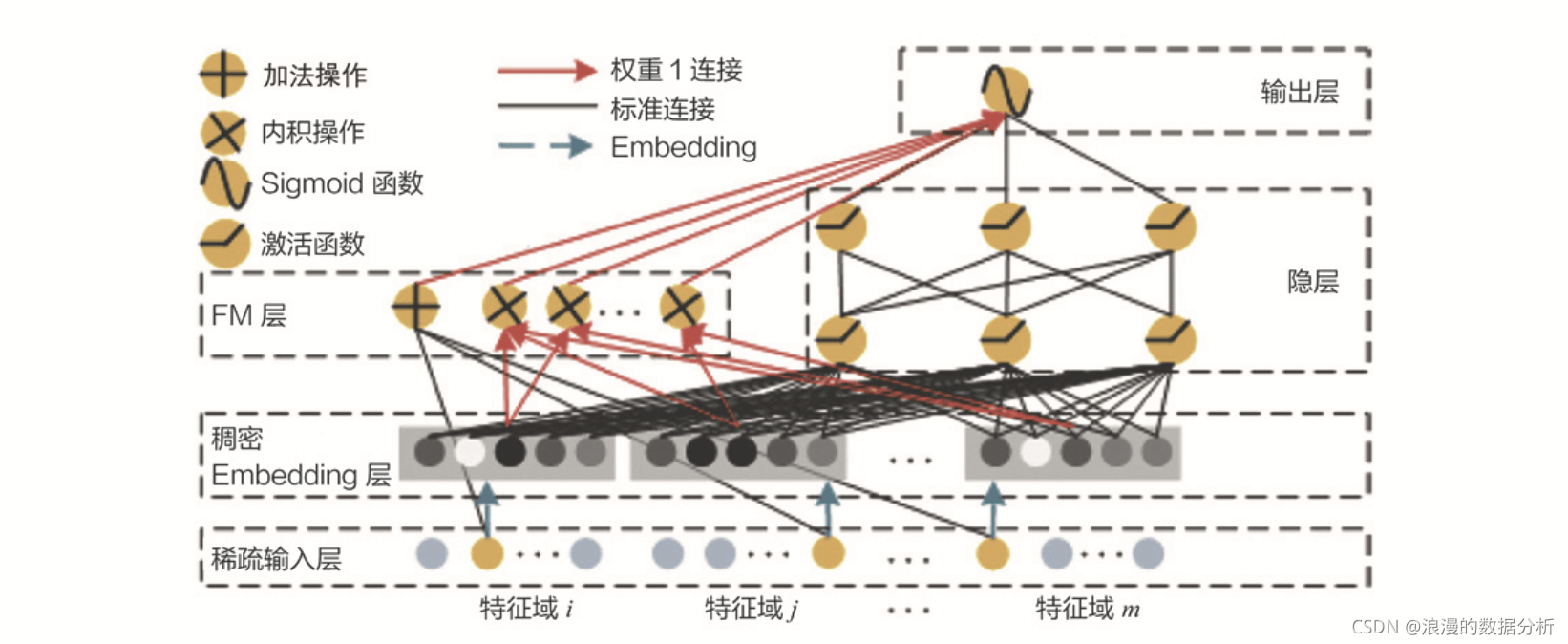
学习过 Wide&Deep 结构之后,可以快速给出答案,可以把 FM 跟其他深度学习模型组合起来,生成一个全新的既有强特征组合能力,又有强拟合能力的模型。基于这样的思想,DeepFM 模型就诞生了。DeepFM 是由哈工大和华为公司联合提出的深度学习模型,架构示意图如下:
类别WideDeep,模型,可以这样理解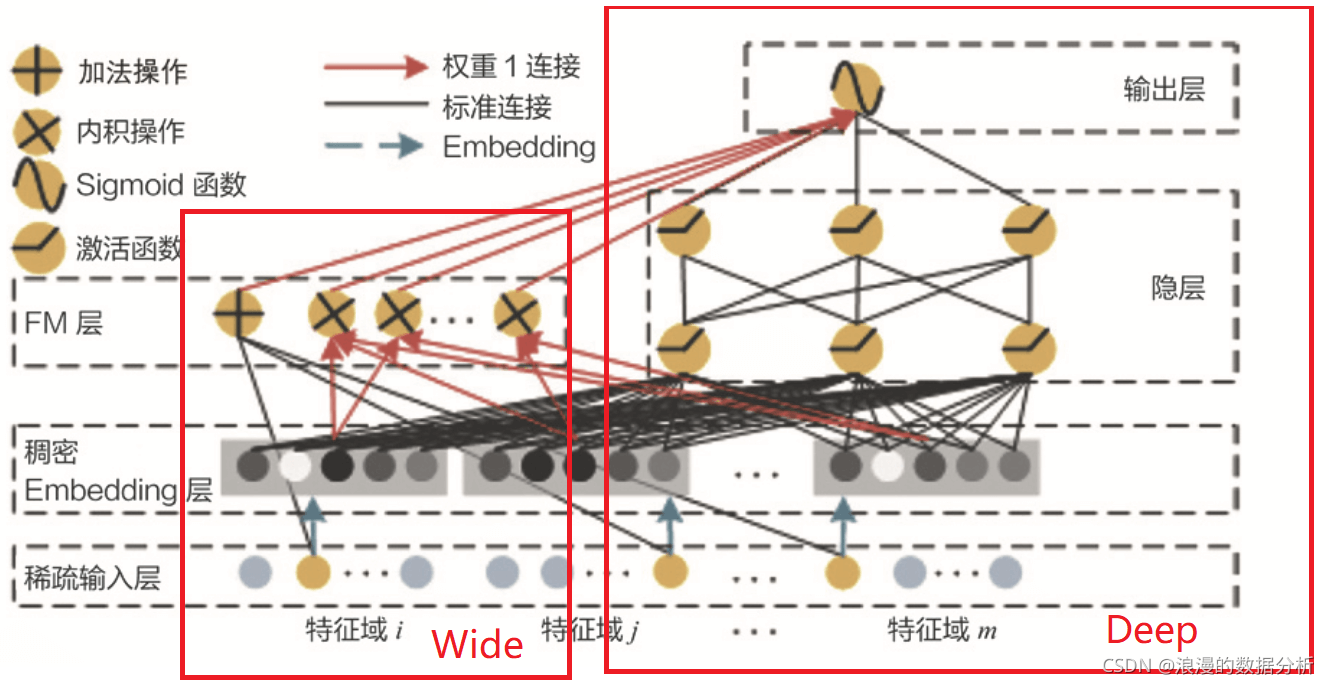
DeepFM 利用了 Wide&Deep 组合模型的思想,用 FM 替换了 Wide&Deep 左边的 Wide 部分,加强了浅层网络部分特征组合的能力,而右边的部分跟 Wide&Deep 的 Deep 部分一样,主要利用多层神经网络进行所有特征的深层处理,最后的输出层是把 FM 部分的输出和 Deep 部分的输出综合起来,产生最后的预估结果。这就是 DeepFM 的结构。
- DNN部分则是一个简单的多层的全连接神经网络。每一层的输出公式如下所示:
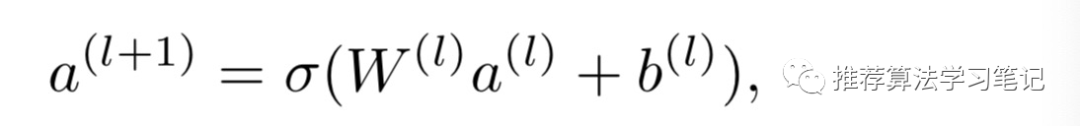
特征交叉新方法:元素积操作
FM 和 DeepFM 中进行特征交叉的方式,都是进行 Embedding 向量的点积操作,那是不是说特征交叉就只能用点积操作了?答案当然是否定的。事实上还有很多向量间的运算方式可以进行特征的交叉,比如模型 NFM(Neural Factorization Machines,神经网络因子分解机),它就使用了新的特征交叉方法。下面,我们一起来看一下。图 4 就是 NFM 的模型架构图,相信已经看了这么多模型架构图的你,一眼就能看出它跟其他模型的区别,也就是 Bi-Interaction Pooling 层。那这个夹在 Embedding 层和 MLP 之间的层到底做了什么呢?
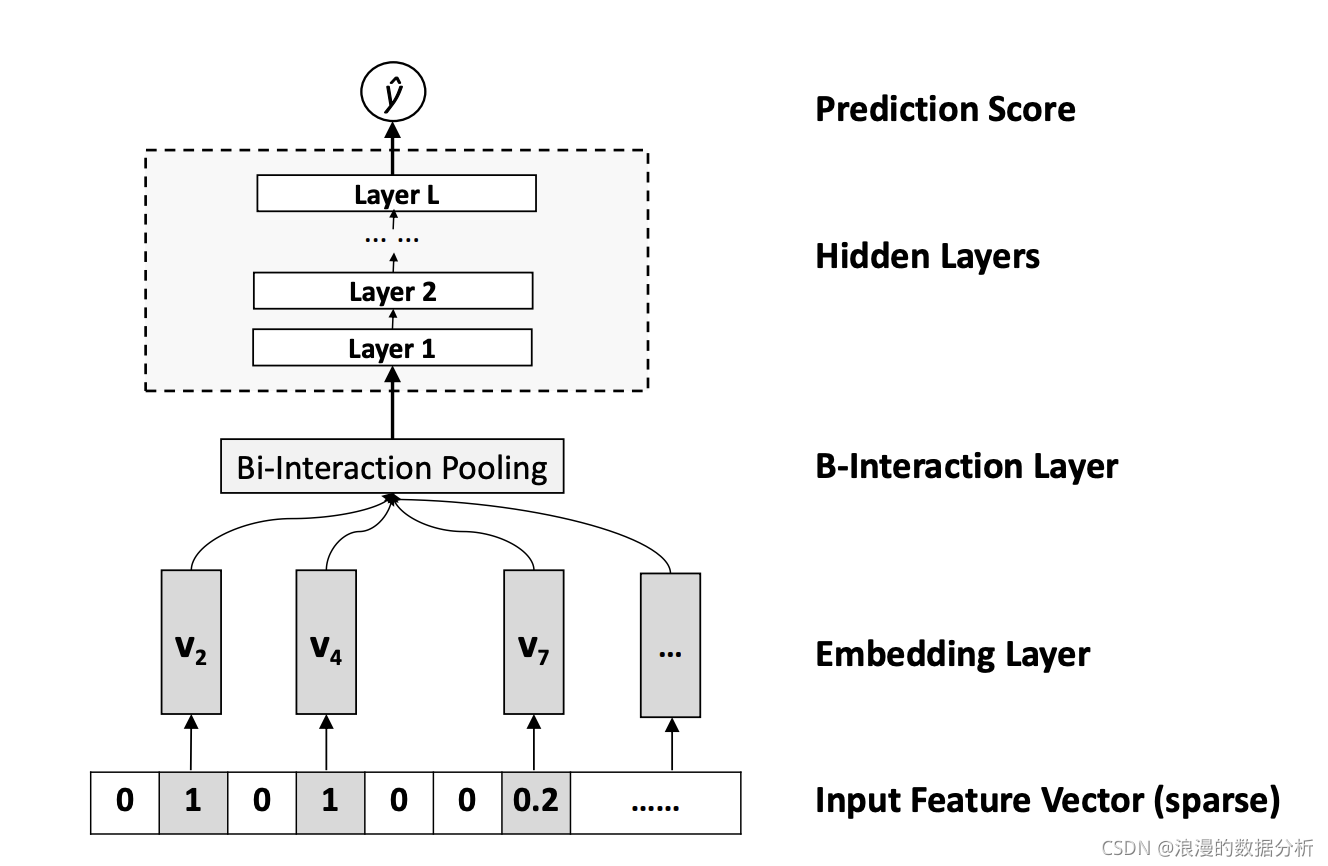
Bi-Interaction Pooling Layer 翻译成中文就是“两两特征交叉池化层”。假设 Vx 是所有特征域的 Embedding 集合,那么特征交叉池化层的具体操作如下所示。
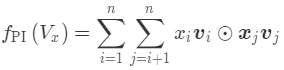
其中 ⊙ 运算代表两个向量的元素积(Element-wise Product)操作,即两个长度相同的向量对应维相乘得到元素积向量。其中,第 k 维的操作如下所示。
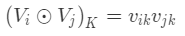
其中的xi 和 xj,可以理解为特征Vi和Vj的权重,也是模型需要学习的参数,表示特征在进行交叉的时候,重要程度并不是都一样,需要进行权重分配。
在进行两两特征 Embedding 向量的元素积操作后,再求取所有交叉特征向量之和(SUM),我们就得到了池化层的输出向量。接着,我们再把该向量输入上层的多层全连接神经网络,就能得出最后的预测得分。
总的来说,NFM 并没有使用内积操作来进行特征 Embedding 向量的交叉,而是使用元素积的操作。在得到交叉特征向量之后,也没有使用 concatenate 操作把它们连接起来,而是采用了求和的池化操作,把它们叠加起来。
元素积操作和点积操作到底哪个更好呢?真实的效果怎么样,要去在具体的业务场景的实践中验证。
技巧:
刚开始学习的时候,遇到一个问题,就是特征的权重,如何让模型自己去训练,这因为是个线性问题y=wx+b,如何确定这个w。看了代码后才明白:
1、 单个神经元,如果我们不指定激活函数,他就是个线性模型,如图:
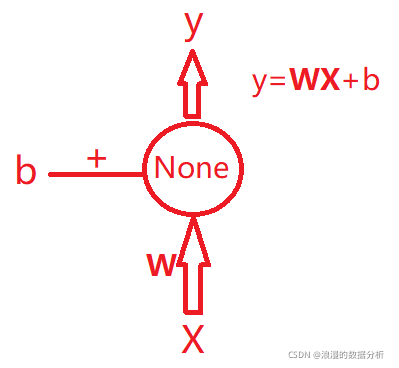
所以,我们把特征输入一个没有激活函数的神经元,然后再把神经元输出的y再和其他特征进行交叉,进行模型训练,神经网络便可以自己训练W的权重值,这点有点超乎想象。
2、如果能进行embeding,尽量让embeding维度统一,这样两两就可以计算点积或者元素积,但是当要和数值特征,没有embeding向量,而是一个一维数值,怎么办呢?
后来学到一招。就是让embeding后的特征,还有数值特征等等,输入给多个神经元,比如50个,并不指定激活函数,这样每个特征都会得到一个50维度的线性权重向量,然后再和其他特征的50维向量进行点积或者元素积,这样,就不论特征embeding维度是多少,有没有embeding,都可以进行特征交叉。如下图
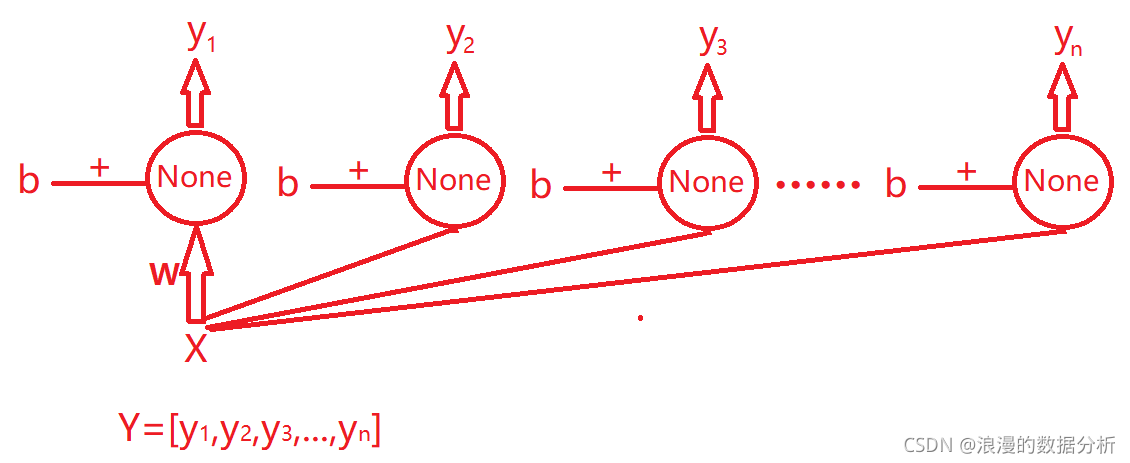
最终的Y就可以和其他特征进行交叉。
代码部分:
完整代码GitHub地址:https://github.com/jiluojiluo/recommenderSystemForFlowerShop
一阶线性部分:
first_order_cat_feature = tf.keras.layers.DenseFeatures(cat_columns)(inputs)
first_order_cat_feature = tf.keras.layers.Dense(1, activation=None)(first_order_cat_feature)
first_order_deep_feature = tf.keras.layers.DenseFeatures(deep_columns)(inputs)
first_order_deep_feature = tf.keras.layers.Dense(1, activation=None)(first_order_deep_feature)
## first order feature
first_order_feature = tf.keras.layers.Add()([first_order_cat_feature, first_order_deep_feature])
二阶交叉特征代码:
second_order_sum_feature = ReduceLayer(1)(second_order_fm_feature)
second_order_sum_square_feature = tf.keras.layers.multiply([second_order_sum_feature, second_order_sum_feature])
second_order_square_feature = tf.keras.layers.multiply([second_order_fm_feature, second_order_fm_feature])
second_order_square_sum_feature = ReduceLayer(1)(second_order_square_feature)
## second_order_fm_feature
second_order_fm_feature = tf.keras.layers.subtract([second_order_sum_square_feature, second_order_square_sum_feature])
Deep部分代码:
deep_feature = tf.keras.layers.Flatten()(second_order_fm_feature)
deep_feature = tf.keras.layers.Dense(32, activation='relu')(deep_feature)
deep_feature = tf.keras.layers.Dense(16, activation='relu')(deep_feature)
最终拼接3个模块,组成一个大向量,送入到最后的sigmoid函数,进行预测
concatenated_outputs = tf.keras.layers.Concatenate(axis=1)([first_order_feature, second_order_fm_feature, deep_feature])
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(concatenated_outputs)
运行结果:
1064/1064 [==============================] - 31s 24ms/step - loss: 0.7667 - accuracy: 0.7406 - auc: 0.8041 - auc_1: 0.7558
Epoch 2/5
1064/1064 [==============================] - 25s 23ms/step - loss: 0.4634 - accuracy: 0.8022 - auc: 0.8765 - auc_1: 0.8534
Epoch 3/5
1064/1064 [==============================] - 25s 23ms/step - loss: 0.4243 - accuracy: 0.8220 - auc: 0.8953 - auc_1: 0.8754
Epoch 4/5
1064/1064 [==============================] - 25s 23ms/step - loss: 0.3970 - accuracy: 0.8341 - auc: 0.9070 - auc_1: 0.8905
Epoch 5/5
1064/1064 [==============================] - 25s 23ms/step - loss: 0.3832 - accuracy: 0.8391 - auc: 0.9126 - auc_1: 0.8984
264/264 [==============================] - 6s 16ms/step - loss: 0.3950 - accuracy: 0.8380 - auc: 0.9114 - auc_1: 0.8904
Test Loss 0.39503785967826843, Test Accuracy 0.8380219340324402, Test ROC AUC 0.9113883376121521, Test PR AUC 0.8903669118881226
可以看到运行结果,同一份数据,相比之前的的Wide@Deep,NutralCF等,模型的准确度提升太多了。也说明顺着模型的升级,效果越来越显著,挖掘到的交叉特征确实能提升模型的准确度。

















 3253
3253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









