







更多文章参考微信公众号:小满锅
select s_id from score where c_id in(
select c_id from score where s_id='01')
group by s_id;
select b.s_id
from score b join score c on b.c_id=c.c_id and c.s_id='01' group by b.s_id;
select s_id
from score b left semi join score c on b.c_id=c.c_id and c.s_id='01' group by s_id;
先看看三个SQL,在说这个SQL之前,我们有几个表:
学生表:s_id,s_name,s_birth,s_sex
分数表:s_id,c_id,s_core
其他表暂时不管
上面的SQL应该就是说要找到至少有一门课程和01同学所学课程相同的同学
先来看看第一条SQL
select s_id from score where c_id in(
select c_id from score where s_id='01')
group by s_id;
这里显示一个子查询,将01同学的c_id筛选出来了,然后形成一个子集吧,最后外查询将选修的课程给筛选出来,然后再根据s_id分组,选出学生id。实际上这个group by就是一个去重嘛对吧
使用explain看一下查询计划👌
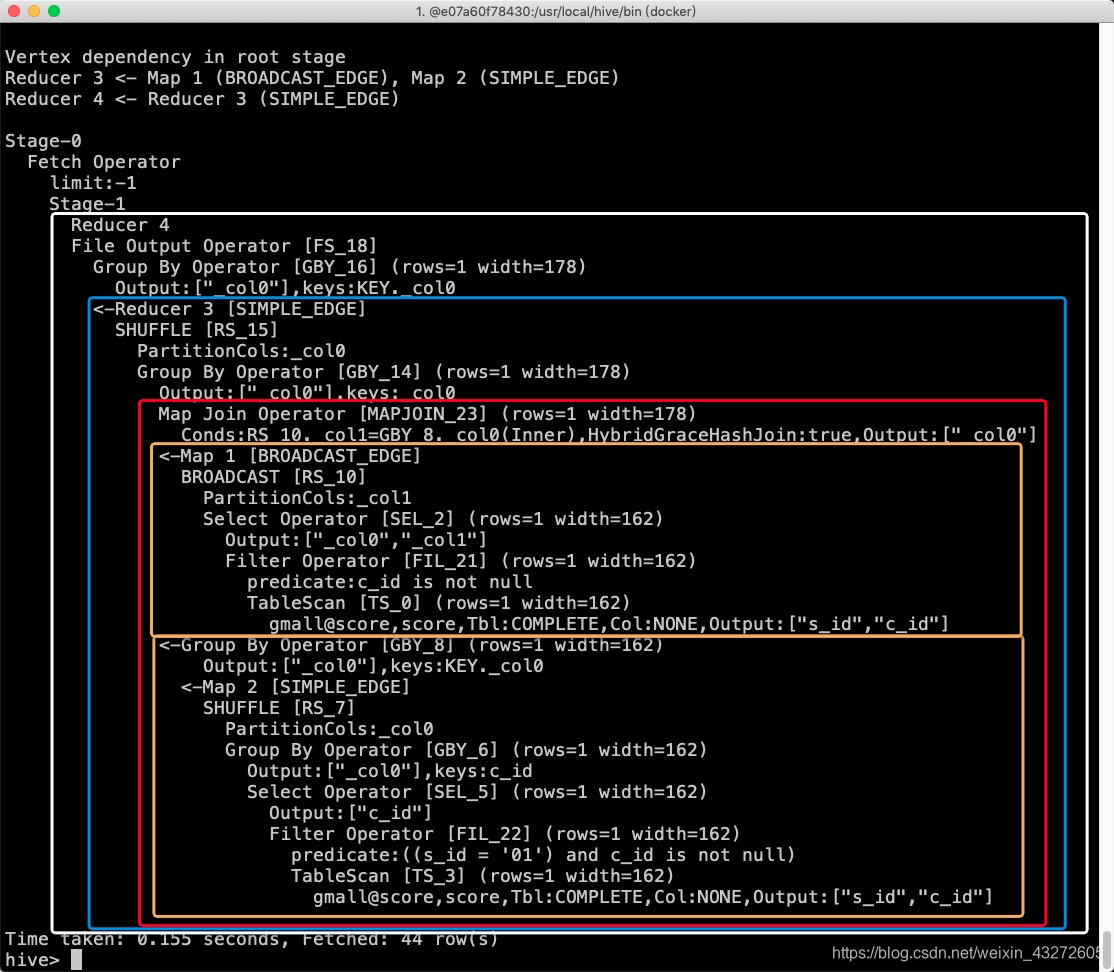
最里面黄色框框是两个map,即分别取扫描两个表,而红色框框就是两个表进行了一个mapjoin,而蓝色框框Reduce就是根据mapjoin的结果对key分组,可以看到这个过程发生了Shuffle,最后白色框框也是Reduce,应该是将结果汇总吧。
select b.s_id
from score b join score c on b.c_id=c.c_id and c.s_id='01' group by b.s_id;
查看一下执行计划
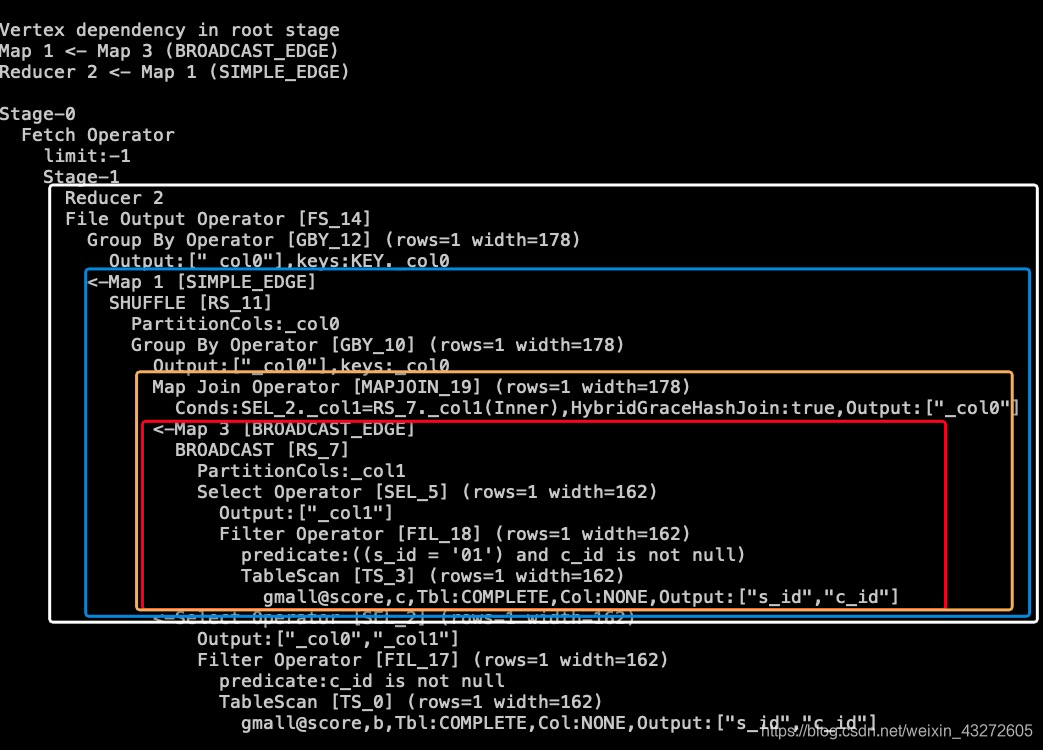
两者结果是一样,这是执行计划不同,但是为什么前面那个会多个Reduce呢。
select s_id
from score b left semi join score c on b.c_id=c.c_id and c.s_id='01' group by s_id;
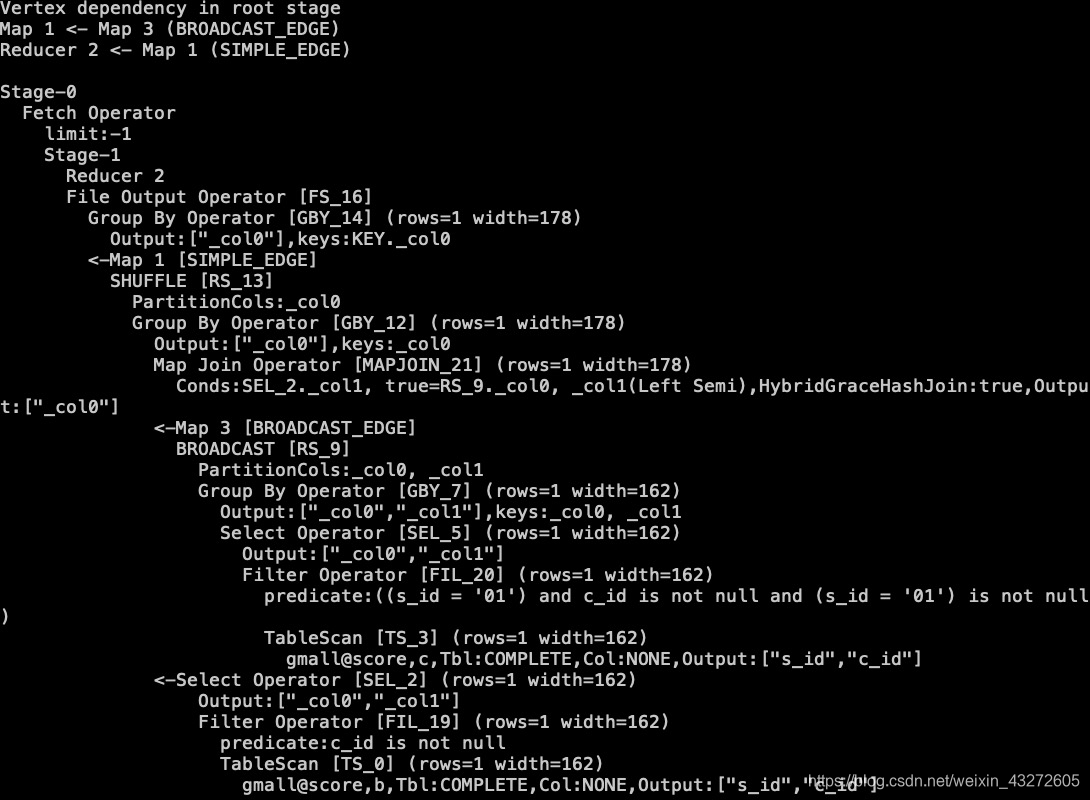
前面那个用的是left join,看起来和这个差不多,但是性能还是有细微的区别的,前面的优化只是做了一个map join,但是呢,那个map join只是将小表复制到多个maptask了。而这个就是只将右表中符号条件的数据key去出来而已,所以不用去除所有,而且对于那些parquet的存储格式的数据,可以跳过一大批。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











