







 本文探讨了Hadoop集群中节点信息在Web页面上显示异常的问题,深入分析了datanode和nodemanager向ResourceManager注册时出现localhost而非预期主机名的情况,及由此导致的ResourceManager仅能识别单一节点的困扰。
本文探讨了Hadoop集群中节点信息在Web页面上显示异常的问题,深入分析了datanode和nodemanager向ResourceManager注册时出现localhost而非预期主机名的情况,及由此导致的ResourceManager仅能识别单一节点的困扰。
在服务器上搭建了许久的Hadoop集群,以前也没有注意过到底Web页面有什么问题,最近在使用Flink的时候,突然发现datanode和nodes of the cluster没有节点的信息
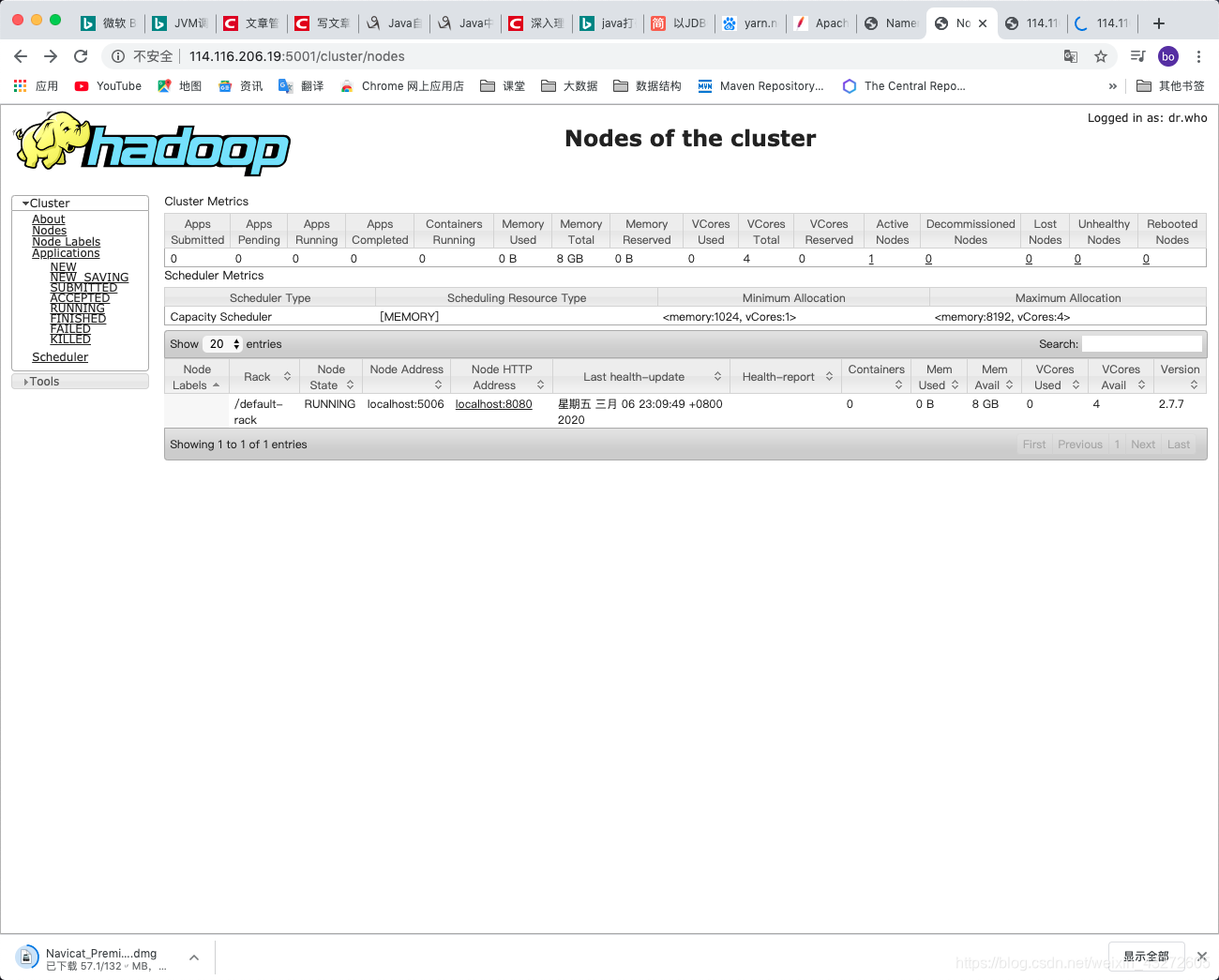
查看日志,啥都没有显示
去每个节点的nodemanager的web页面查看log信息

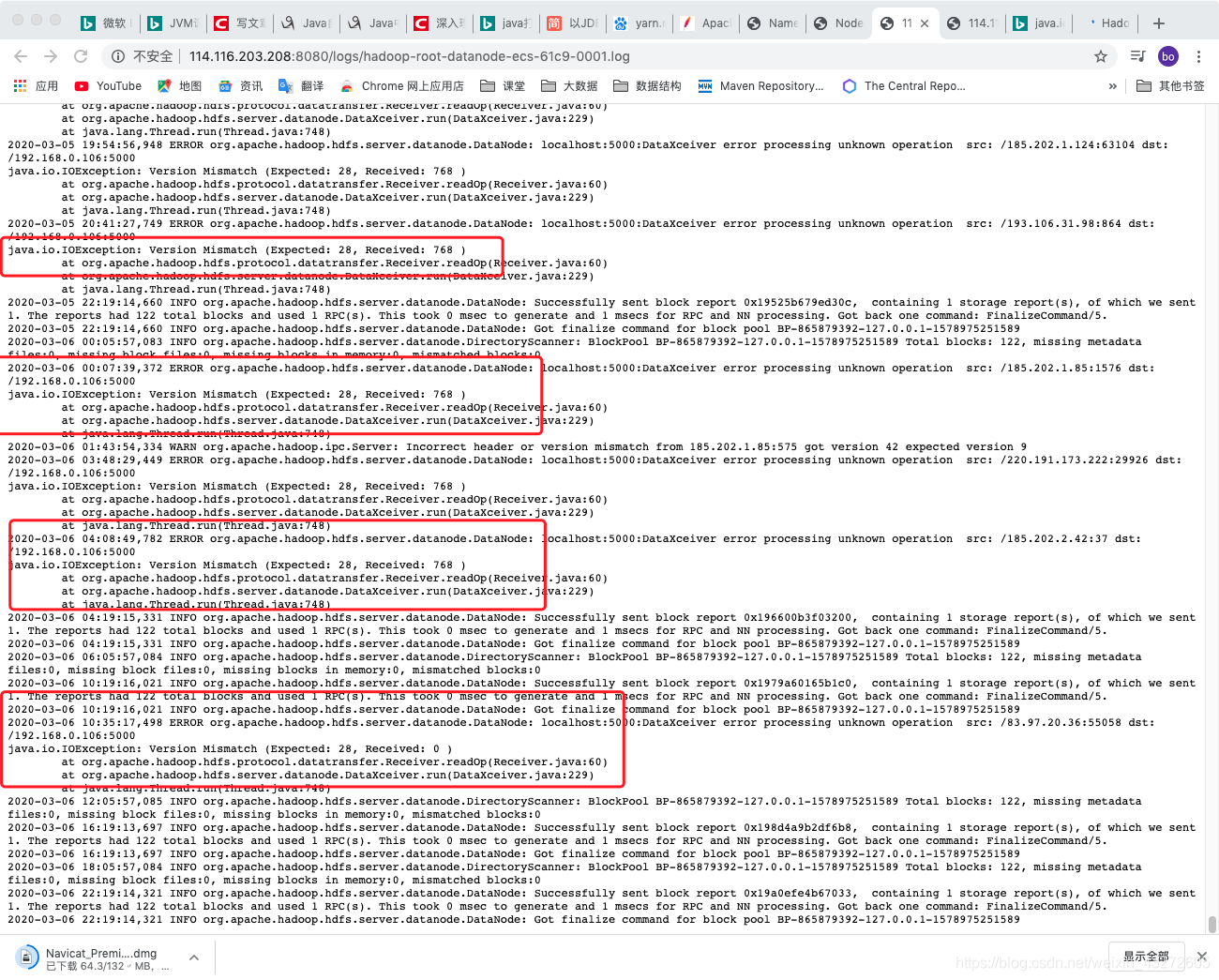
Version Mismatch (Expected: 28, Received: 768 ) at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.readOp
版本不匹配,但是ClusterID是一致的
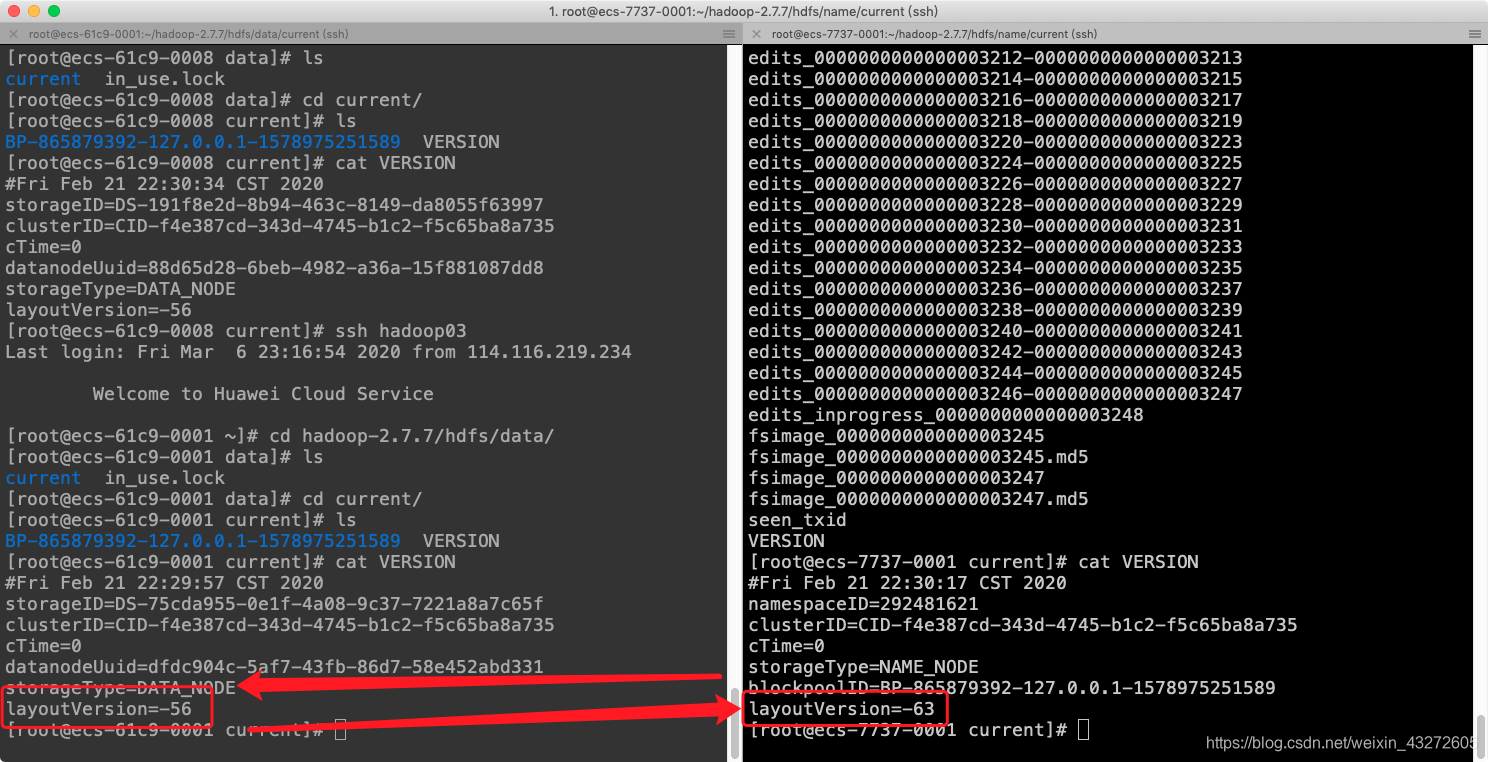
再往上看日志
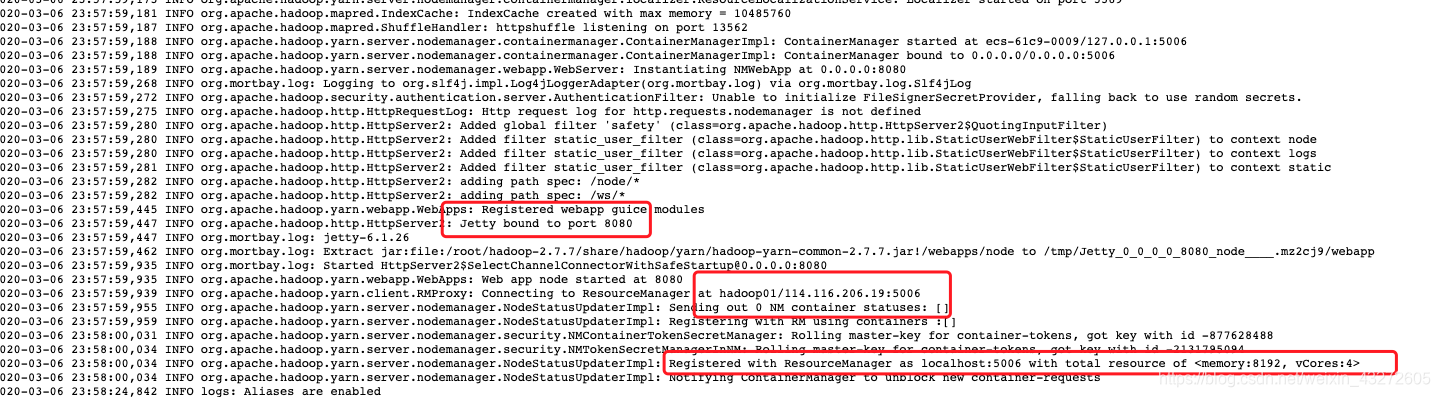
Registered with ResourceManager as localhost:5006 with total resource of <memory:8192, vCores:4>
发现nodemanager向ResourceManager注册的竟然是localhost:5006,不应该是hadoop02:5006吗,这里的5006是我修改过的IPC端口。因为服务器被限制住了。
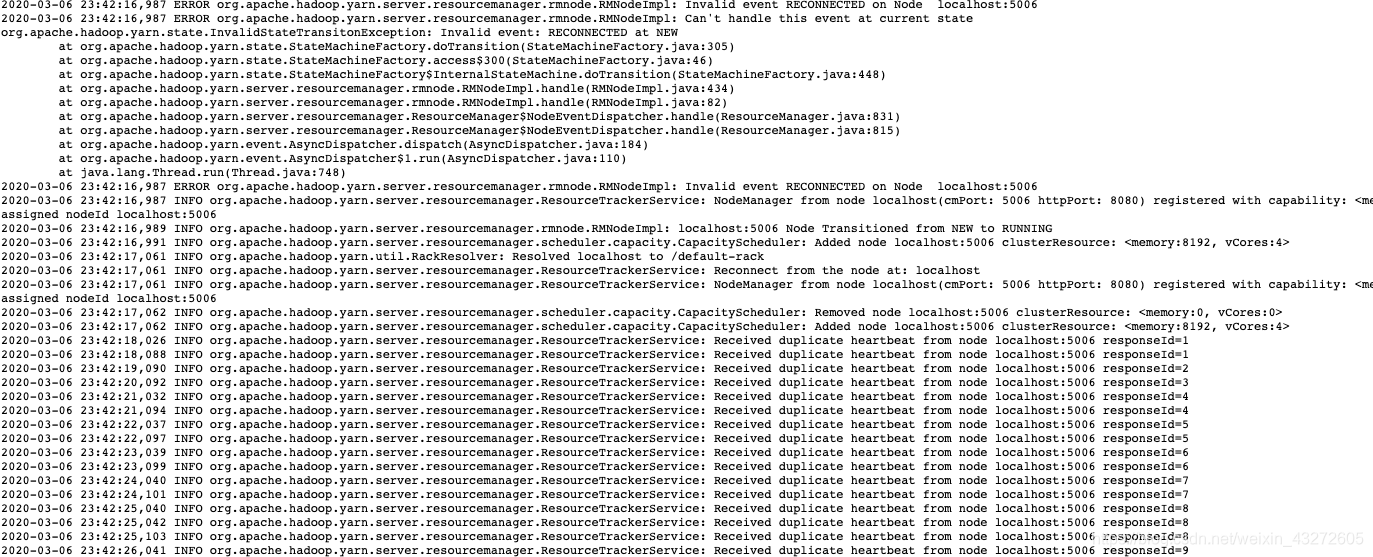
查看映射
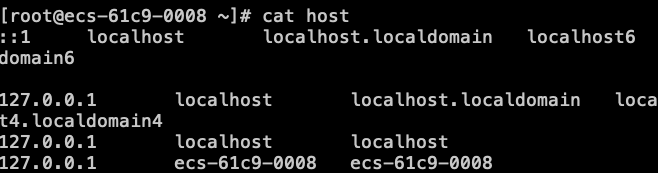
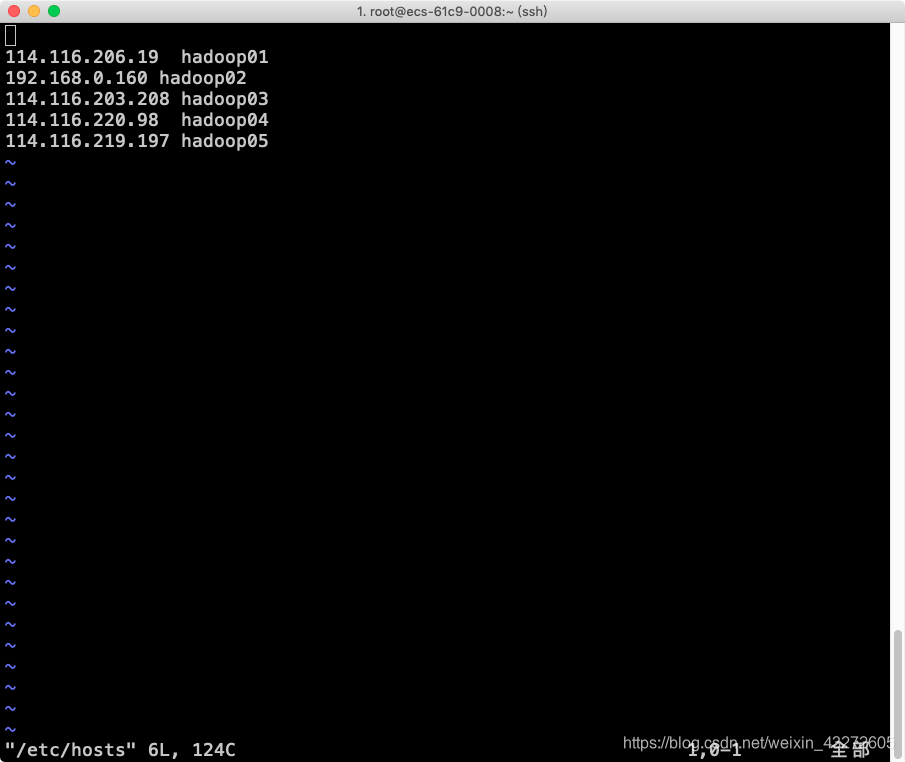
我刚开始的映射是上面两个图片映射的,注意,因为是在阿里云服务器上,所以我们的网络配置,本地的要配置成内网IP。虽然这样还有问题。
就是服务器默认带有第一张图片127.0.0.1到localhost的映射,就是这个原因,当datanode或者nodemanager返回心跳给namenode和ResourceManager的时候,导致先是找到hdfs或者yarn里面配置的机器名,比如配置的是hadoop02,而这个hadoop02又会去找到对应的IP,即本机器内网IP,然后在根据内网IP映射到了localhhost,最终返回的主机名也是localhost,按理说应该是hadoop02的,结果所有的datanode和nodemanager都返回localhost,导致ResourceManager只能看到一个节点。而且是祝节点。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











