






一、DEIM
DEIM(DETR with Improved Matching for Fast Convergence)提高了实时检测及小目标检测的能力,目前项目中使用了Yolov11,Yolov12对目标进行检测,发现整体对小目标,模糊目标的检测能力不足,尝试DEIM模型,比较结果
二、环境准备
Github 链接:【https://github.com/ShihuaHuang95/DEIM】
参考官方给出的环境安装指令对环境进行安装
git clone https://github.com/ShihuaHuang95/DEIM.git
cd DEIM
conda create -n deim python=3.11.9
conda activate deim
pip install -r requirements.txt
三、准备数据
参照官方数据的格式
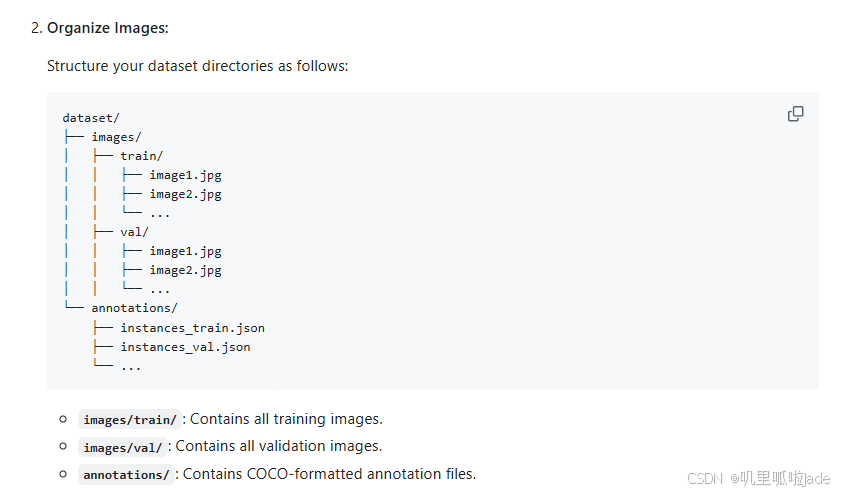 数据按照上图准备放在文件夹里。
数据按照上图准备放在文件夹里。
因为我的数据是yolo格式,已经分好train/val/test文件了,因此将Yolo(txt)格式的标签转化为coco(json)格式
import os
import json
import cv2
from tqdm import tqdm
def yolo_to_coco(yolo_dir, output_json_dir):
# 定义图像和标签文件夹路径
images_dir = os.path.join(yolo_dir, 'images')
labels_dir = os.path.join(yolo_dir, 'labels')
classes_file = os.path.join(yolo_dir, 'classes.txt')
# 检查文件夹是否存在
if not os.path.exists(images_dir) or not os.path.exists(labels_dir):
raise FileNotFoundError("images 或 labels 文件夹不存在!")
if not os.path.exists(classes_file):
raise FileNotFoundError("classes.txt 文件不存在!")
# 读取类别信息
with open(classes_file, 'r', encoding='utf-8') as f:
categories = [line.strip() for line in f.readlines()]
categories = [{"id": i + 1, "name": name} for i, name in enumerate(categories)]
# 初始化COCO数据结构
coco_data = {
"images": [],
"annotations": [],
"categories": categories
}
# 遍历图像
image_id = 1
annotation_id = 1
for image_name in tqdm(os.listdir(images_dir)):
if not image_name.endswith(('.jpg', '.png', '.jpeg')):
continue
# 读取图像尺寸
image_path = os.path.join(images_dir, image_name)
image = cv2.imread(image_path)
height, width, _ = image.shape
# 添加图像信息
coco_data["images"].append({
"id": image_id,
"file_name": image_name,
"width": width,
"height": height
})
# 读取对应的标注文件
label_name = os.path.splitext(image_name)[0] + '.txt'
label_path = os.path.join(labels_dir, label_name)
if not os.path.exists(label_path):
continue
with open(label_path, 'r') as f:
lines = f.readlines()
# 解析标注
for line in lines:
parts = line.strip().split()
if len(parts) != 5:
continue
class_id, x_center, y_center, bbox_width, bbox_height = map(float, parts)
# 将归一化坐标转换为绝对坐标
x_center *= width
y_center *= height
bbox_width *= width
bbox_height *= height
# 计算边界框的左上角坐标
x_min = x_center - (bbox_width / 2)
y_min = y_center - (bbox_height / 2)
# 计算面积
area = bbox_width * bbox_height
# 添加标注信息
coco_data["annotations"].append({
"id": annotation_id,
"image_id": image_id,
"category_id": int(class_id) + 1, # YOLO类别从0开始,COCO从1开始
"bbox": [x_min, y_min, bbox_width, bbox_height],
"area": area,
"iscrowd": 0
})
annotation_id += 1
image_id += 1
# 输出 COCO 格式的 JSON 文件
if not os.path.exists(output_json_dir):
os.makedirs(output_json_dir)
output_json_path = os.path.join(output_json_dir, f"instances_{os.path.basename(yolo_dir)}.json")
with open(output_json_path, 'w') as f:
json.dump(coco_data, f, indent=4)
print(f"转换完成!COCO格式文件已保存到: {output_json_path}")
def process_all_splits(data_dir, output_json_dir):
splits = ['train', 'val', 'test'] # 对应的三个文件夹
for split in splits:
yolo_dir = os.path.join(data_dir, split)
output_json_path = os.path.join(output_json_dir, f'instances_{split}.json')
yolo_to_coco(yolo_dir, output_json_dir)
# 主程序
data_dir = r"E:\YOLO_DATA\data" # 数据集根目录
output_json_dir = r"E:\YOLO_DATA\data_\coco_jsons" # 输出文件夹路径
process_all_splits(data_dir, output_json_dir)
将数据放到服务器路径下,准备进行下一步
四、修改训练文件
- 修改DEIM/configs/dataset/custom_detection.yml文件
修改了num_classes、remap_mscoco_category: False及img_folder、ann_file
task: detection
evaluator:
type: CocoEvaluator
iou_types: ['bbox', ]
num_classes: 31 # your dataset classes
remap_mscoco_category: False
train_dataloader:
type: DataLoader
dataset:
type: CocoDetection
img_folder: /DEIM/data/data_three/images/train
ann_file: /DEIM/data/data_three/annotations/instances_train.json
return_masks: False
transforms:
type: Compose
ops: ~
shuffle: True
num_workers: 4
drop_last: True
collate_fn:
type: BatchImageCollateFunction
val_dataloader:
type: DataLoader
dataset:
type: CocoDetection
img_folder: /DEIM/data/data_three/images/val
ann_file: /DEIM/data/data_three/annotations/instances_val.json
return_masks: False
transforms:
type: Compose
ops: ~
shuffle: False
num_workers: 4
drop_last: False
collate_fn:
type: BatchImageCollateFunction
-
修改/DEIM/configs/deim_dfine/deim_hgnetv2_s_coco.yml
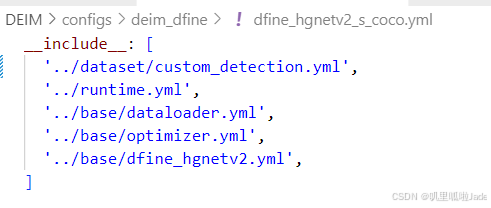
-
修改DEIM/configs/deim_dfine/dfine_hgnetv2_s_coco.yml
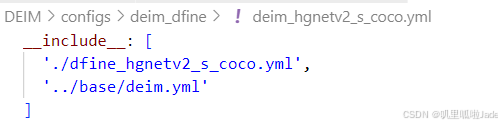
-
修改epochs等参数,这里我没有修改参数,把配置放在这。
在configs/base/dataloader.yml修改total_batch_size; -
运行训练命令
python train.py -c configs/deim_dfine/deim_hgnetv2_s_coco.yml --use-amp --seed=0
五、错误记录
- 在最开始训练过程中一直报错
File "DEIM\engine\data\transforms\container.py", line 100, in stop_epoch_forward
sample = transform(sample)
^^^^^^^^^^^^^^^^^
File ".venv\Lib\site-packages\torch\nn\modules\module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File ".venv\Lib\site-packages\torch\nn\modules\module.py", line 1750, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File ".venv\Lib\site-packages\torchvision\transforms\v2\_transform.py", line 68, in forward
flat_outputs = [
^
File ".venv\Lib\site-packages\torchvision\transforms\v2\_transform.py", line 69, in <listcomp>
self.transform(inpt, params) if needs_transform else inpt
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File ".venv\Lib\site-packages\torchvision\transforms\v2\_transform.py", line 55, in transform
raise NotImplementedError
NotImplementedError
改了无数版本,最终发现是torchvision版本太高了,最后安装了0.15.2,顺利训练;
- 报错
tensor([[[nan, nan, nan, nan],
[nan, nan, nan, nan],
[nan, nan, nan, nan],
...,
[nan, nan, nan, nan],
[nan, nan, nan, nan],
[nan, nan, nan, nan]],
,,,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/raid/home/zjq/Sea/DEIM/engine/deim/box_ops.py", line 53, in generalized_box_iou
assert (boxes1[:, 2:] >= boxes1[:, :2]).all()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AssertionError
检查可能是由txt转化生成的json中存在 x与y为0的情况,也可能是混合训练的影响,于是都改掉,重新修改了生成文件的代码,继续跑起来看看
import os
import glob
import json
import argparse
from PIL import Image
def load_classes(class_file):
""" 从文件中读取类别列表,每行一个类别 """
with open(class_file, "r", encoding="utf-8") as f:
class_names = [line.strip() for line in f.readlines()]
return class_names
def yolo_to_coco(yolo_dir, images_dir, output_json_path, class_file):
""" 将 YOLO 格式的 txt 标签转换为 COCO 格式 JSON """
# 读取类别
class_names = load_classes(class_file)
# 初始化 COCO 数据格式
coco = {
"images": [],
"annotations": [],
"categories": []
}
# 添加类别信息,确保 ID 从 0 开始
for idx, name in enumerate(class_names):
coco["categories"].append({
"id": idx,
"name": name
})
ann_id = 0 # 标注 ID 计数
image_files = glob.glob(os.path.join(images_dir, "*.jpg"))
for img_id, img_path in enumerate(image_files):
file_name = os.path.basename(img_path)
# 获取图片尺寸
with Image.open(img_path) as img:
width, height = img.size
coco["images"].append({
"id": img_id,
"file_name": file_name,
"width": width,
"height": height
})
# 读取 YOLO 标注
txt_file = os.path.join(yolo_dir, os.path.splitext(file_name)[0] + ".txt")
if os.path.exists(txt_file):
with open(txt_file, 'r') as f:
lines = f.readlines()
for line in lines:
parts = line.strip().split()
if len(parts) != 5:
continue
class_id, x_center_norm, y_center_norm, w_norm, h_norm = parts
class_id = int(class_id)
x_center = float(x_center_norm) * width
y_center = float(y_center_norm) * height
w = float(w_norm) * width
h = float(h_norm) * height
# 确保 x 和 y 至少为 1
x = max(1, x_center - w / 2)
y = max(1, y_center - h / 2)
# 确保宽高不会超出图像范围
w = min(w, width - x)
h = min(h, height - y)
area = w * h
# 添加标注信息到 COCO 数据中
coco["annotations"].append({
"id": ann_id,
"image_id": img_id,
"category_id": class_id,
"bbox": [x, y, w, h],
"area": area,
"iscrowd": 0
})
ann_id += 1
# 保存 COCO 格式的 JSON 文件
with open(output_json_path, 'w', encoding="utf-8") as json_file:
json.dump(coco, json_file, indent=4)
print(f"转换完成,COCO JSON 文件保存在:{output_json_path}")
def main():
parser = argparse.ArgumentParser(
description="将 YOLO 格式的 txt 标签转换为 COCO 格式的 JSON 文件"
)
parser.add_argument("--yolo_dir", type=str, required=True, help="YOLO txt 文件所在的文件夹路径")
parser.add_argument("--images_dir", type=str, required=True, help="图像文件所在的文件夹路径")
parser.add_argument("--output_json", type=str, required=True, help="输出 JSON 文件的路径")
parser.add_argument("--class_file", type=str, required=True, help="包含类别名称的文件,每行一个类别")
args = parser.parse_args()
yolo_to_coco(args.yolo_dir, args.images_dir, args.output_json, args.class_file)
if __name__ == "__main__":
main()
重新运行命令
python train.py -c configs/deim_dfine/deim_hgnetv2_s_coco.yml --resume "DEIM/outputs/deim_hgnetv2_s_coco/last.pth"
继续训练,等待结果
更新训练结果
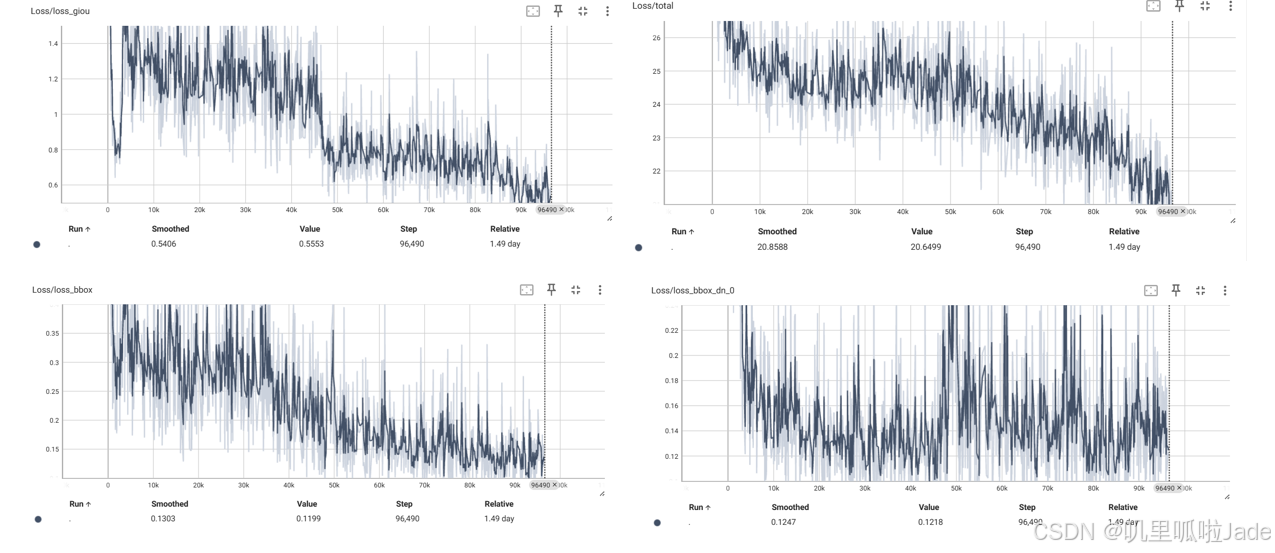
- 这回顺利跑完了132个epochs,输出结果,但是通过实时观看结果,发现还没有完全收敛。
使用tensorboard实时查看结果
tensorboard --logdir=../outputs/deim_hgnetv2_s_coco/summary
在本地电脑打开得到的网址
ssh -L 端口:localhost:端口 username@your_server_ip
2. 结果推理
python tools/inference/torch_inf.py -c configs/deim_dfine/deim_hgnetv2_${model}_coco.yml -r model.pth --input image.jpg --device cuda:0
使用上述命令进行推理,只可以一张一张推理,后续又写了一个代码进行批量推理及保存。

















 1396
1396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









