







 旷视提出DRConv,一种动态区域感知卷积方法,通过在不同图像区域应用特定卷积核,显著提升分类、检测和分割任务性能。此方法在云端实验中展现出优秀潜力。
旷视提出DRConv,一种动态区域感知卷积方法,通过在不同图像区域应用特定卷积核,显著提升分类、检测和分割任务性能。此方法在云端实验中展现出优秀潜力。
旷视提出 DRConv:动态区域感知卷积,提升分类 / 检测 / 分割性能。
《Dynamic Region-Aware Convolution》是2020年旷视在arXiv上的新论文,该论文实际上是在动态卷积(local形式)上引入了空间上的分组,从而显著提升了计算机视觉任务(分类检测分割)等性能,在云端实验还是非常值得尝试的。
论文地址:
https://arxiv.org/abs/2003.12243
内容
将图像划分成不同的区域,在不同的区域上使用不同的卷积。区域内卷积是通用的,不同区域卷积不通用。G()是生成卷积的模块,有多少个区域,就生成多少个卷积核。
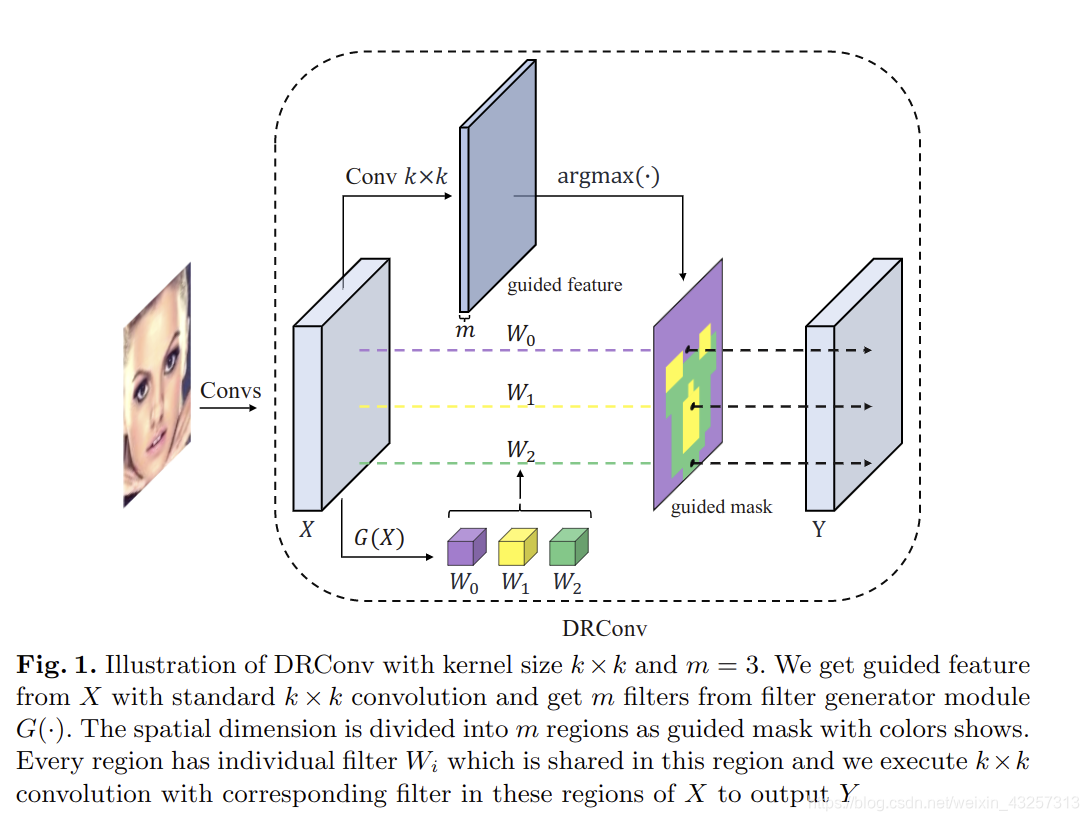
在区域上的卷积:
u,v,c,o:高、宽、通道、output
W:卷积核
S:卷积区域

区域的生成:
其实是M个卷积核,在这个guided mask上卷积后生成了M个特征,将这些特征称作区域。
W是M个卷积和,Wm(u,v),M(u,v)是索引,范围是0到m-1,M(u,v)的值是在(u,v)处,m个特征F里,像素最大的F所在的通道。

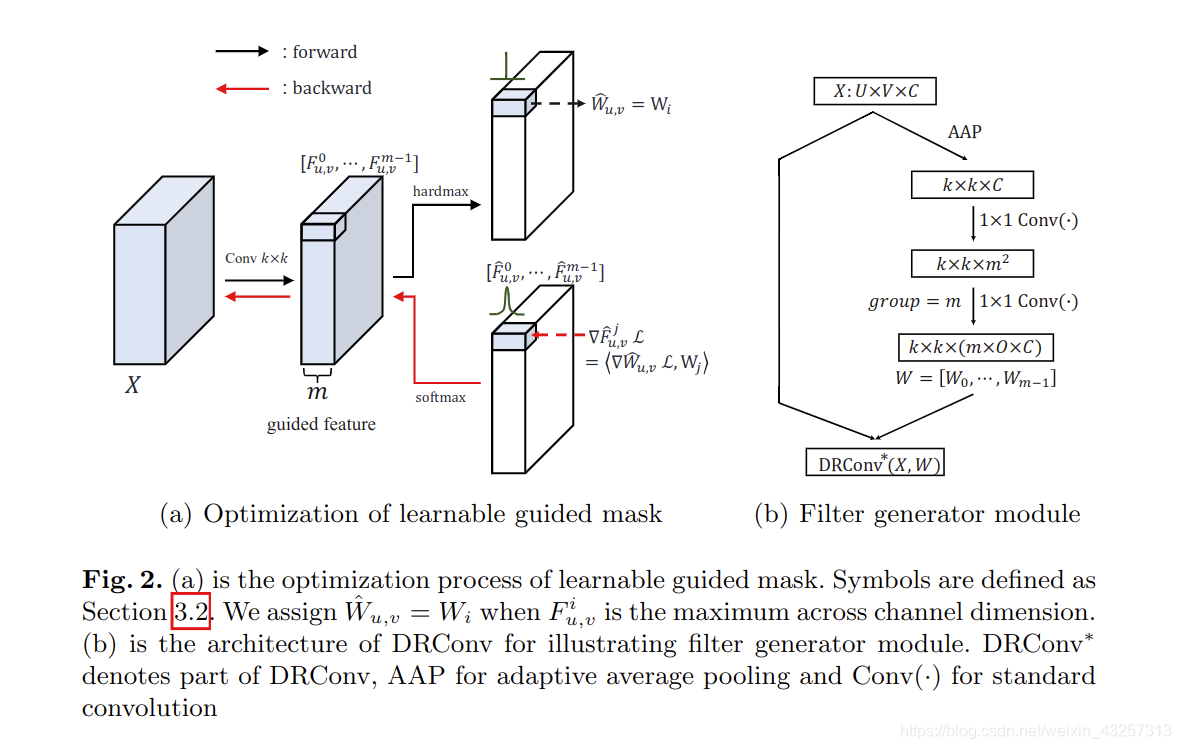
guided mask的生成-Eq4:
对原始图像卷积后,使用argmax或者softmax将各通道像素合并成一个通道。

M个卷积核的生成-Eq.(5):
1,使用AAP将X下采样到kk的大小,共m个,不使用激活层
2,使用softmax将x映射成kk的大小。
然后,使用1和2相加,或者其他方法(文中没说),合并12成为m个卷积核。


















 4017
4017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









