






分享自己在学习 PyTorch 源码时阅读过的资料。本文重点关注 PyTorch 的核心数据结构 Tensor 的设计与实现。因为 PyTorch 不同版本的源码实现有所不同,所以笔者在整理资料时尽可能按版本号升序,版本号见标题前[]。最新版本的源码实现还请查看 PyTorch 仓库。更多内容请参考:
- Ubuntu 22.04 LTS 源码编译安装 PyTorch
- 深度学习框架与静态/动态计算图【笔记】
- 【翻译】pytorch/CONTRIBUTING.md
- 【翻译】Pytorch机制,源代码分析与内存管理调研
- PyTorch 源码学习①:阅读经验 & 代码结构
- PyTorch 源码学习③:Dispatch & Autograd & Operators
- PyTorch 源码学习④:GPU 内存管理之它山之石——TensorFlow BFC 算法
- PyTorch 源码学习⑤:GPU 内存管理之深入分析 CUDACachingAllocator
- PyTorch 源码学习⑥:GPU 内存管理之初步探索 expandable_segments
文章目录
- 什么是 Tensor?
- 通过类图理解 Tensor 的设计
- 更多关于 c10::intrusive_ptr_target、TensorImpl 和 StorageImpl 的分析
- 自顶向下探索 Tensor 的实现及内存分配
- aten/src/ATen/CheckpointTensorImpl.cpp
- aten/src/ATen/CheckpointTensorImpl.h
- aten/src/ATen/templates/TensorBody.h
- c10/core/TensorImpl.h
- c10/core/TensorImpl.cpp
- c10/core/Storage.h
- c10/core/StorageImpl.h
- c10/core/Allocator.h
- c10/util/UniqueVoidPtr.h
- c10/util/intrusive_ptr.h
- c10/cuda/CUDACachingAllocator.h
- c10/cuda/CUDACachingAllocator.cpp
- 待更新……
什么是 Tensor?
Tensor 是 PyTorch 的核心数据结构。具体可以参考:
通过类图理解 Tensor 的设计
下图来源自:[1.0.1] PyTorch – Internal Architecture Tour | Terra Incognita,该博客写得较早,但也具有很高的参考价值。
主张量 THTensor 结构的组成:
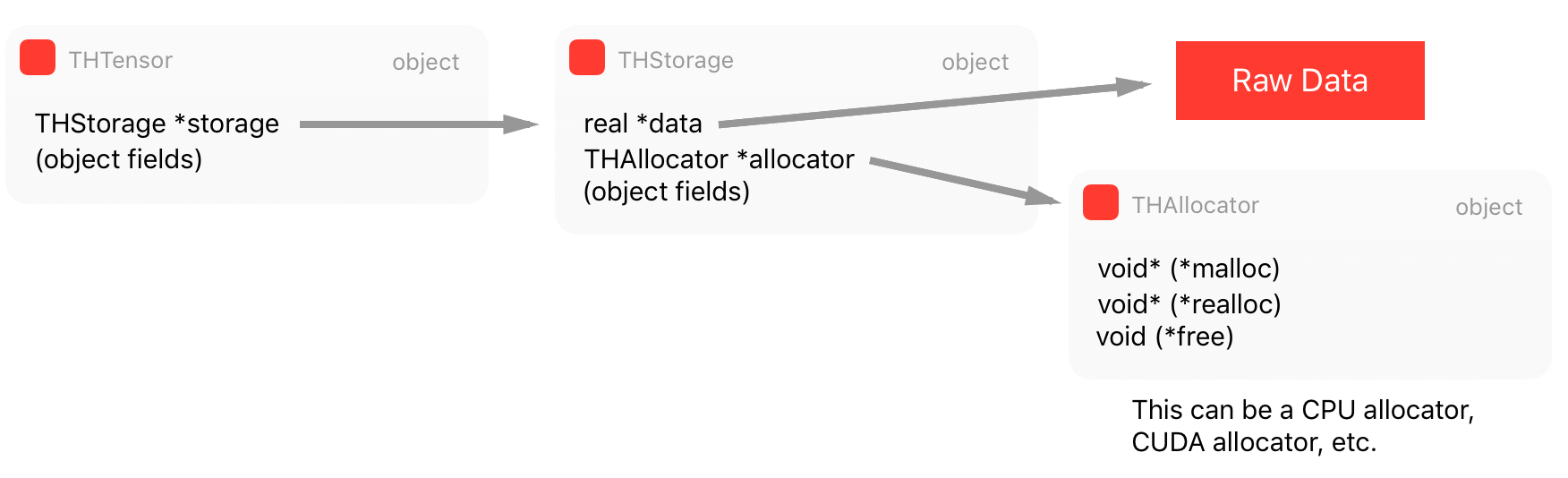
THTensor的主要结构为张量数据保留了 size/strides/dimensions/offsets/ 等,同时还有存储THStorage。
张量的实际原始数据并不是立即保存在张量结构中,而是保存在我们称之为「存储(Storage)」的地方,它是张量结构的一部分。
多个张量可以指向相同的存储,而仅仅对数据采用不同的解析。
THStorage 有一个指向原始数据、原始数据大小、flags 和 allocator 的指针。值得注意的是,THStorage 不包含如何解释内部数据的元数据,这是因为存储对保存的内容「无处理信息的能力」,只有张量才知道如何「查看」数据。
下图来源自:[1.0.1] PyTorch的Tensor(上),当作一个简版的类图。该博客写得较早,但也具有很高的参考价值,同系列的博客还有:
- 2019-01-19:PyTorch的编译系统
- 2019-02-14:PyTorch ATen代码的动态生成
- 2019-02-18:PyTorch Autograd代码的动态生成
- 2019-03-16:PyTorch的cpp代码生成
- 2019-02-27:PyTorch的初始化
- 2019-03-06:PyTorch的Tensor(上)
- 2019-05-11:PyTorch的Tensor(中)
- 2019-06-23:PyTorch的Tensor(下)
- 2019-03-16:PyTorch的cpp代码生成
- 2019-04-22:再谈PyTorch的初始化(上)
- 2019-04-23:再谈PyTorch的初始化(中)
- 2019-04-24:再谈PyTorch的初始化(下)
- 2019-04-30:PyTorch的动态图(上)
- 2019-05-16:PyTorch的动态图(下)
#垂直表示继承,水平表示被包含,()表示为一个类
DataPtr -> StorageImpl -> Storage -> (TensorImpl) -> (Tensor)
| |
v v
(Tensor) -> Variable::Impl Variable -> AutogradMeta -> (TensorImpl)
其中,Storage 和 StorageImpl 之间、TensorImpl 和 Tensor 之间都使用了 Bridge 设计模式。
桥接(Bridge)设计模式是一种结构型设计模式,它旨在将抽象部分与实现部分分离,以便两者可以独立地变化。这样可以使一个类的多个维度变化独立开来,从而减少类之间的耦合度。桥接模式通过使用组合而不是继承的方式来达到这个目的。
Storage和StorageImpl的桥接模式实现:
- 抽象部分(Abstraction):这里是
Storage类。它提供了一个高级别的接口来操作和管理数据存储,但不直接实现存储的细节。- 实现部分(Implementor):这里是
StorageImpl类。它定义了存储的具体实现细节,包括数据类型、数据指针、元素数量等。- 组合关系:
Storage中包含一个指向StorageImpl的智能指针c10::intrusive_ptr<StorageImpl>。这意味着Storage并不直接实现数据存储,而是依赖StorageImpl来实现。storage_impl_是桥接接口(即实现部分)的一个实例,Storage通过它来操作实际的数据存储。使用桥接模式有以下几个好处:
- 分离接口和实现:通过将存储的接口(
Storage)与存储的实现(StorageImpl)分离,允许两者独立变化。例如,可以改变存储实现的细节而不影响存储接口,反之亦然。- 提高灵活性和可扩展性:可以很容易地添加新的存储实现而不改变现有的存储接口。同样,可以扩展存储接口而不改变存储实现。
- 减少耦合度:接口和实现之间的低耦合度提高了代码的可维护性和可测试性。
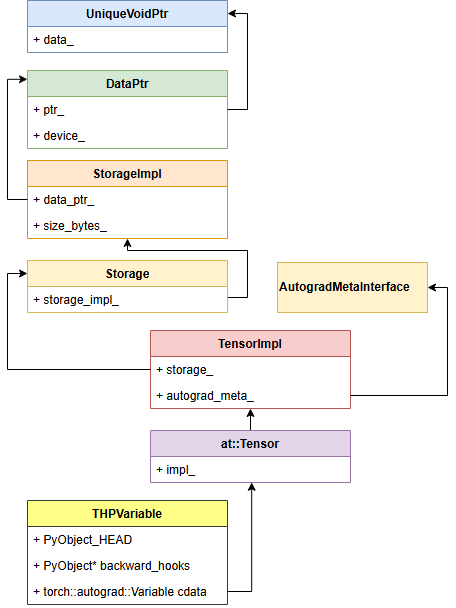
下图来源自:[1.7.0] 张量(Tensor) - Tensor的继承体系 - 《PyTorch源码剖析》 - 极客文档
Tensor在C++层面的继承体系:
下图来源自:[1.10.0] [Pytorch 源码阅读] —— Tensor C++相关实现
- 文中有更多关于
c10::intrusive_ptr_target类、TensorImpl类和StorageImpl类源码分析的内容。
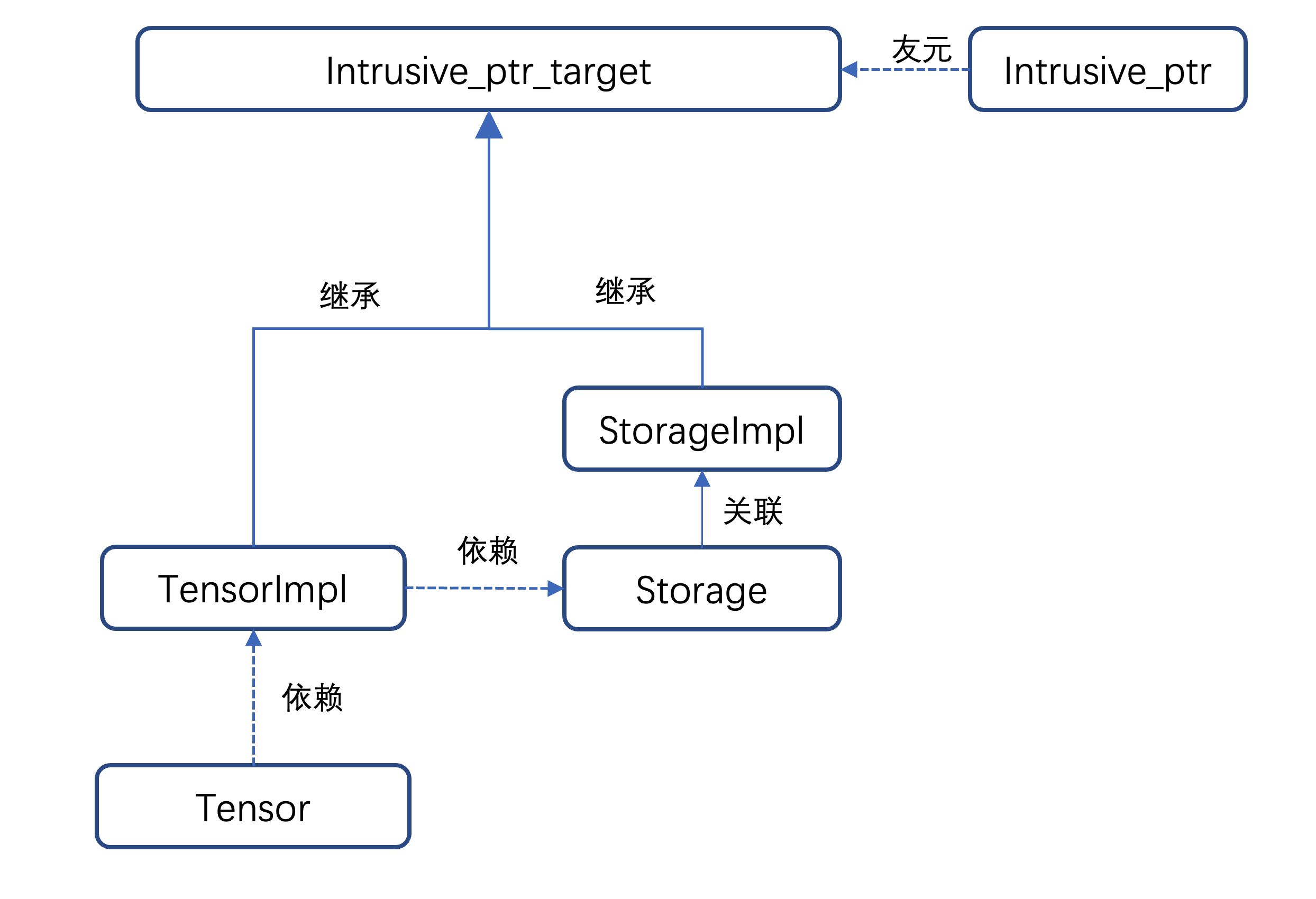
c10::intrusive_ptr的初始化需要intrusive_ptr_target或者其子类。TensorImpl和StorageImpl两个类分别为intrusive_ptr_target的子类,- 然后
StorageImpl主要负责 tensor 的实际物理内存相关的操作,设置空间配置器,获取数据指针,以及占用物理空间大小等; Storage仅仅是对StorageImpl直接包了一下,直接调用的是StorageImpl的相关成员函数。TensorImpl是Tensor类实现的主要依赖类,其初始化就需要依赖Storage类,- 所以上面说:
Tensor=TensorImpl+StorgaeImpl。
下图来源自:[2.0.0] Tensor的组织结构
下图来源自:[unknown] PyTorch源码学习系列 - 2. Tensor
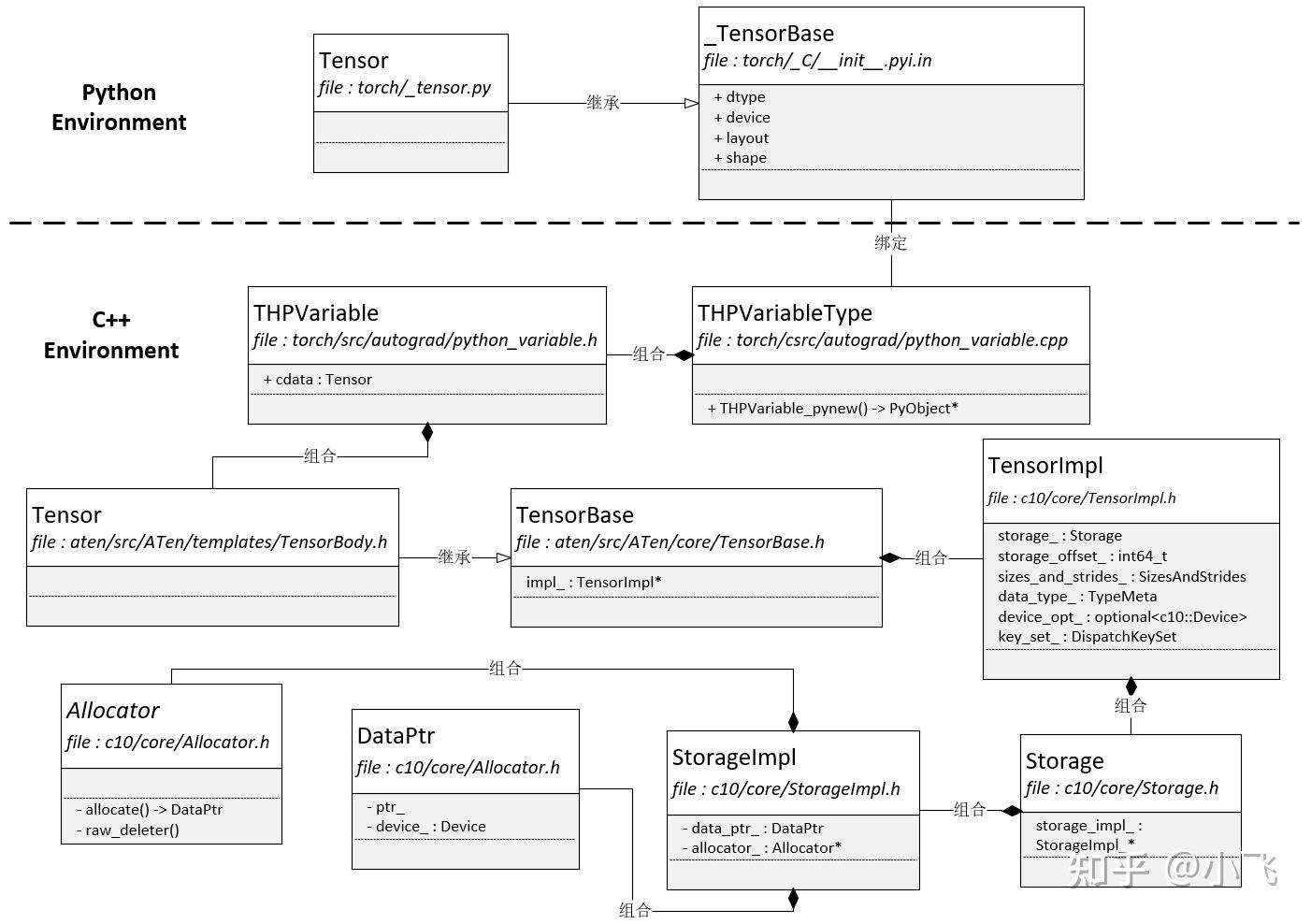
下图来源自:[unknown] pytorch源码学习-Tensor-01
PyTorch眼中的Tensor:
PyTorch将Tensor的物理存储抽象成一个Storage类,与逻辑表示类Tensor解耦,这样我们就可以建立Tensor视图和物理存储Storage之间多对一的联系。Storage是一个声明类,其具体实现在其实现类StorageImpl中。StorageImp中有两个核心的成员:
data_ptr。其指向数据实际存储的内存空间。在类DataPtr中包含了Device相关的成员变量allocator_。其是一个内存分配器。Allocator是一个抽象类,所有派生类必须实现allocate和raw_deleter两个抽象函数
PyTorch的Tensor除了用Storage类来管理物理存储外,还在Tensor中定义了很多相关的元信息。比如我们前面说到的size,stride以及dtype,这些信息都存在TensorImpl类中的sizes_and_strides_以及data_type_中。key_set_中保存的是PyTorch对Tensor的layout,device以及dtype相关的调度信息。
我们在前一篇文章中的架构图里还介绍过PyTorch在C++实现层中实现了算子(Operator),那Operator是如何和Tensor绑定的了?其实PyTorch创建了一个TensorBody.h的模板文件,在该文件中创建了一个继承基类TesnorBase的类Tensor。TensorBase基类中封装了所有和Tensor存储相关的细节,在类Tensor中,PyTorch使用代码自动生成工具将aten/src/ATen/native/native_functions.yaml中声明的函数替换此处的宏${tensor_method_declarations}
class TORCH_API Tensor: public TensorBase {
...
public:
${tensor_method_declarations}
...
}
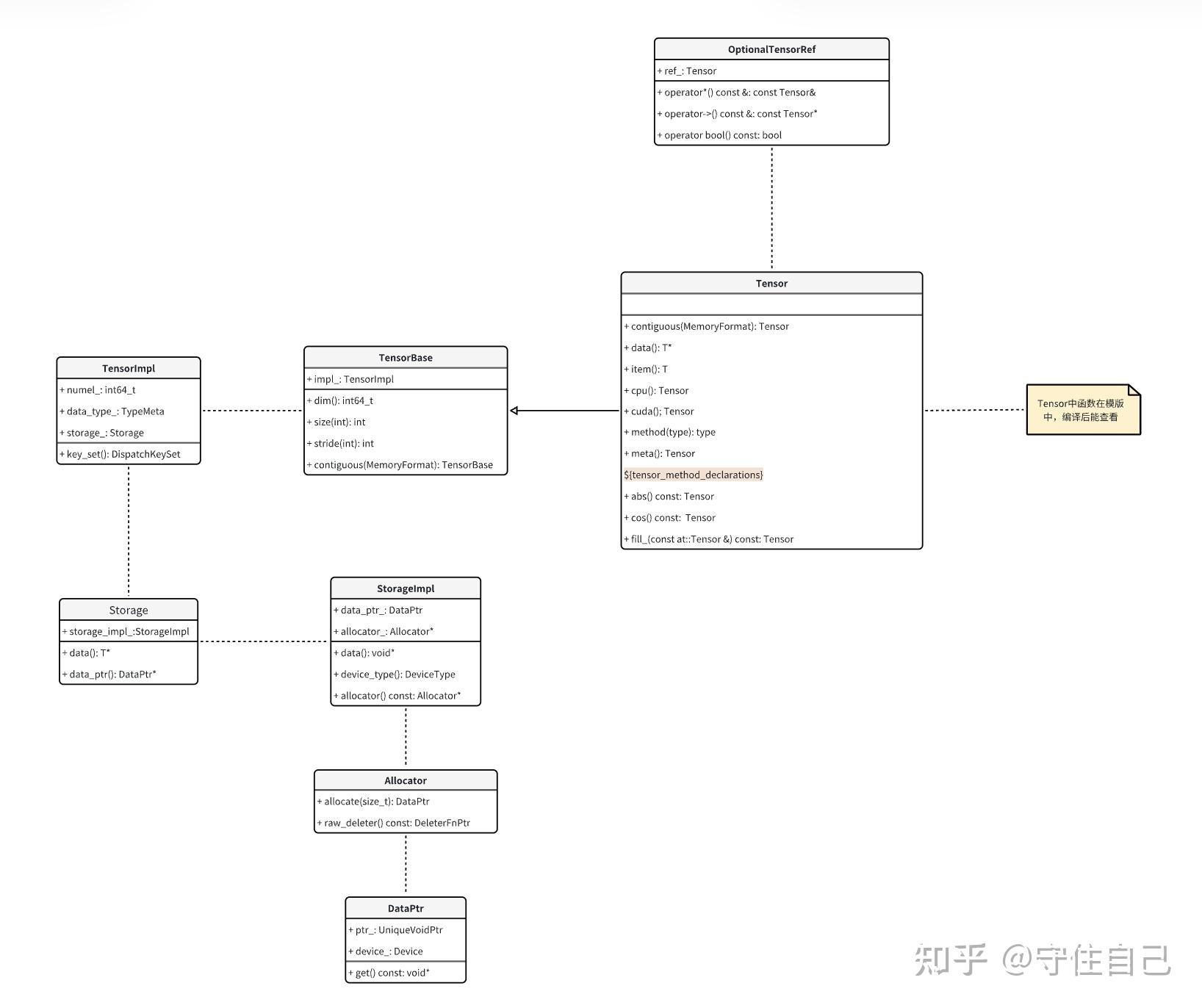
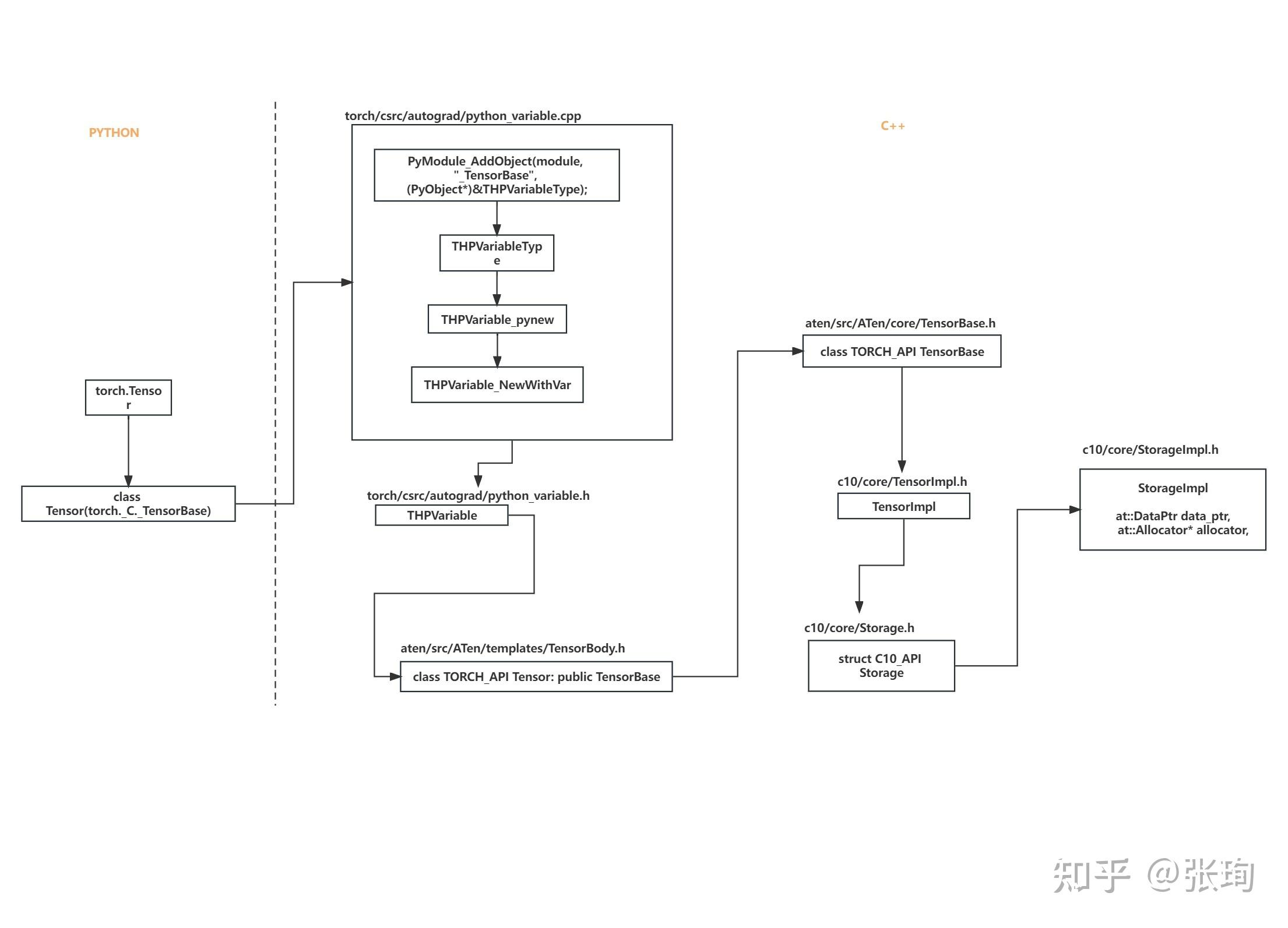
下图来源自:[unknown] Pytorch Tensor/TensorImpl/Storage/StorageImpl,及相关内容:

- Tensor, WeakTensor ->
aten/src/ATen/core/Tensor.h - TensorImpl ->
c10/core/TensorImpl.h - Storage ->
c10/core/Storage.h - StorageImpl ->
c10/core/StorageImpl.h - DataPtr, Allocator,AllocatorRegisterer ->
c10/core/Allocator.h - UniqueVoidPtr ->
c10/util/UniqueVoidPtr.h
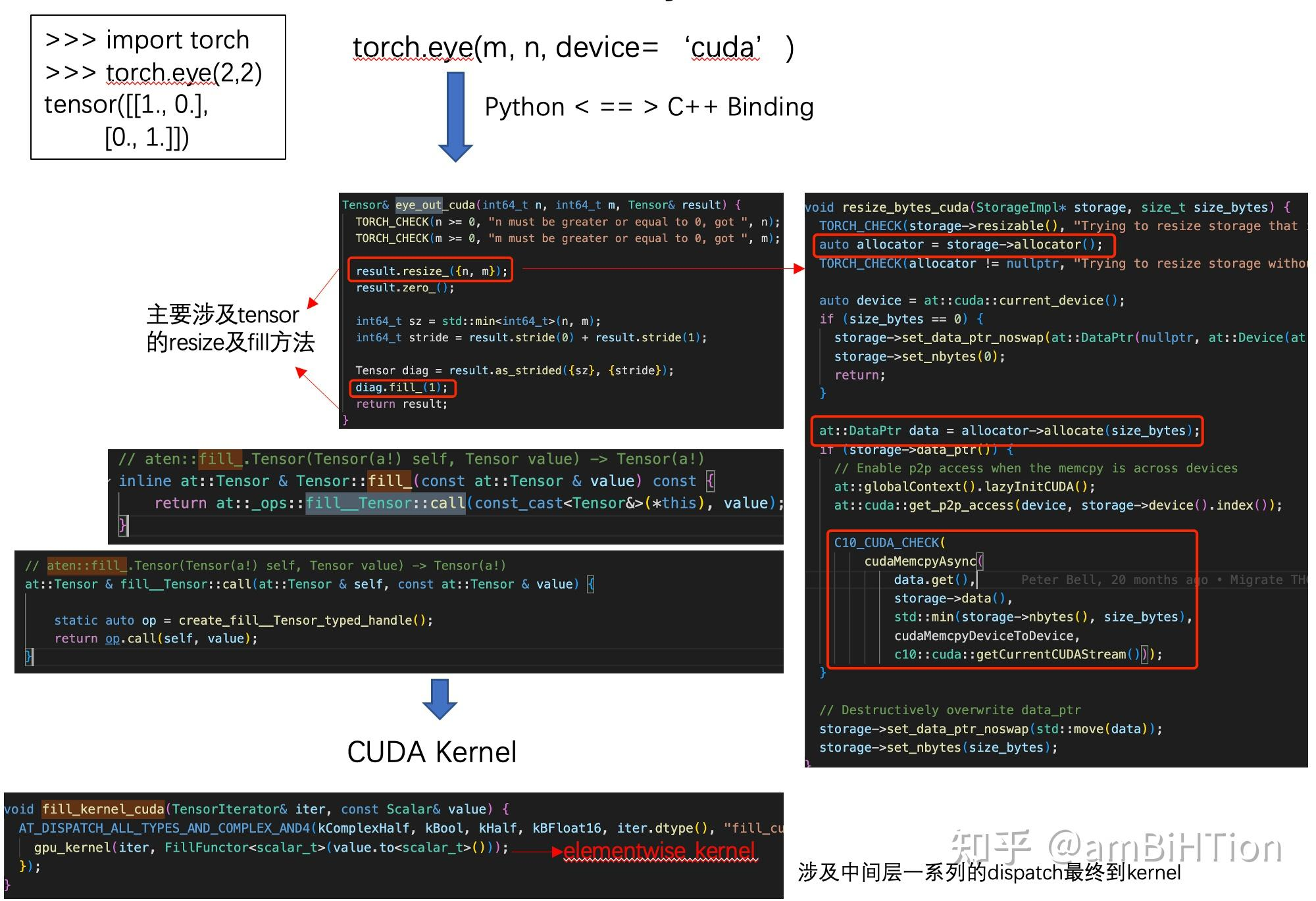
下图来源自:[unknown] PyTorch CUDA backend
PyTorch 中的数据按 Tensor 管理,这里 Tensor 并不是数学中张量的含义,简单地表示多维数据,Tensor 内部指向某个 Storage,Storage 是真正存放 backing memory 的数据结构,多个 Tensor 可以指向同一份 Storage。

下面给出端到端的例子:
更多关于 c10::intrusive_ptr_target、TensorImpl 和 StorageImpl 的分析
- Tensor源码分析与复现(1)& Tensor源码分析与复现(2)★★★
- 【翻译】PyTorch中的intrusive_ptr
- pytorch基于intrusive_ptr_target实现的核心数据结构介绍
- PyTorch 源码阅读笔记(4):自动微分张量库 | K’s blog
- 小白学习pytorch源码(三):理解torch.tensor模块
- [2.1.0] Pytorch底层源码解读(二)libtorch源码浅析(文中对宏名
TORCH_API进行了介绍) - Pytorch源代码分析 (Tensor在pytorch中的实现)
- PyTorch源码浅析(1):THTensor | NIUHE(内容稍微旧了一些,但一些核心思想仍可以参考)
- [1.4.0] 一个Tensor的生命历程(Pytorch版) - Oldpan的个人博客
- pytorch 核心数据结构 at::Tensor(c10:intrusive_ptr, impl_)
- pytorch 核心数据结构 at:Tensor(五)(TypeMeta)
- pytorch 核心数据结构 at:Tensor(六) [Storage](Storage)
- pytorch 核心数据结构 at:Tensor(七) [Storage](StorageImpl)
- pytorch 核心数据结构 at:Tensor(八) [TensorImpl](Tensor, TensorBase, TensorImpl)
自顶向下探索 Tensor 的实现及内存分配
下面的内容源于笔者读研期间的课题研究。代码可以参考 DTR 版本的 PyTorch 1.7.0。
从 CheckpointTensorImpl.cpp 里的 memory 函数开始探索
aten/src/ATen/CheckpointTensorImpl.cpp
#include <ATen/CheckpointTensorImpl.h> -> aten/src/ATen/CheckpointTensorImpl.h
#include <ATen/Logger.h>
#include <c10/cuda/CUDACachingAllocator.h> -> c10/cuda/CUDACachingAllocator.h
inline size_t memory(const Tensor& t) {
if (! t.has_storage()) {
return 0;
}
auto& storage = t.storage();
size_t res = storage.nbytes();
memory_sum += res;
memory_max = std::max(memory_max, res);
memory_count += 1;
return res;
}
long current_memory() {
auto device_stat = c10::cuda::CUDACachingAllocator::getDeviceStats(0);
return device_stat.allocated_bytes[0].current;
}
aten/src/ATen/CheckpointTensorImpl.h
#include <c10/core/Backend.h>
#include <c10/core/MemoryFormat.h>
#include <c10/core/Storage.h> -> c10/core/Storage.h
#include <c10/core/TensorOptions.h>
#include <c10/core/DispatchKeySet.h>
#include <c10/core/impl/LocalDispatchKeySet.h>
#include <c10/core/CopyBytes.h>
#include <c10/util/Exception.h>
#include <c10/util/Optional.h>
#include <c10/util/Flags.h>
#include <c10/util/Logging.h>
#include <c10/util/python_stub.h>
#include <c10/core/TensorImpl.h> -> c10/core/TensorImpl.h
#include <ATen/Tensor.h> -> aten/src/ATen/Tensor.h -> aten/src/ATen/templates/TensorBody.h
#include <ATen/ATen.h> -> aten/src/ATen/ATen.h
aten/src/ATen/templates/TensorBody.h
#include <c10/core/Device.h>
#include <c10/core/Layout.h>
#include <c10/core/MemoryFormat.h>
#include <c10/core/QScheme.h>
#include <c10/core/Scalar.h>
#include <c10/core/ScalarType.h>
#include <c10/core/Storage.h> -> c10/core/Storage.h
#include <ATen/core/TensorAccessor.h>
#include <c10/core/TensorImpl.h> -> c10/core/TensorImpl.h
#include <c10/core/UndefinedTensorImpl.h>
#include <c10/util/Exception.h>
#include <c10/util/Deprecated.h>
#include <c10/util/Optional.h>
#include <c10/util/intrusive_ptr.h>
#include <ATen/core/DeprecatedTypePropertiesRegistry.h>
#include <ATen/core/DeprecatedTypeProperties.h>
#include <ATen/core/NamedTensor.h>
#include <ATen/core/QuantizerBase.h>
#include <torch/csrc/WindowsTorchApiMacro.h>
class CAFFE2_API Tensor {
public:
bool defined() const {
return impl_;
}
bool has_storage() const {
return defined() && impl_->has_storage();
}
const Storage& storage() const {
return impl_->storage();
}
void* data_ptr() const {
return this->unsafeGetTensorImpl()->data();
}
template <typename T>
T * data_ptr() const;
protected:
c10::intrusive_ptr<TensorImpl, UndefinedTensorImpl> impl_;
};
c10/core/TensorImpl.h
#include <c10/core/Backend.h>
#include <c10/core/MemoryFormat.h>
#include <c10/core/Storage.h> -> c10/core/Storage.h
#include <c10/core/TensorOptions.h>
#include <c10/core/DispatchKeySet.h>
#include <c10/core/impl/LocalDispatchKeySet.h>
#include <c10/core/CopyBytes.h>
#include <c10/util/Exception.h>
#include <c10/util/Optional.h>
#include <c10/util/Flags.h>
#include <c10/util/Logging.h>
#include <c10/util/python_stub.h>
struct C10_API TensorImpl : public c10::intrusive_ptr_target {
public:
/**
* Return a reference to the sizes of this tensor. This reference remains
* valid as long as the tensor is live and not resized.
*/
virtual IntArrayRef sizes() const;
/**
* True if this tensor has storage. See storage() for details.
*/
virtual bool has_storage() const;
/**
* Return the underlying storage of a Tensor. Multiple tensors may share
* a single storage. A Storage is an impoverished, Tensor-like class
* which supports far less operations than Tensor.
*
* Avoid using this method if possible; try to use only Tensor APIs to perform
* operations.
*/
virtual const Storage& storage() const;
/**
* Return the size of a single element of this tensor in bytes.
*/
size_t itemsize() const {
TORCH_CHECK(dtype_initialized(),
"Cannot report itemsize of Tensor that doesn't have initialized dtype "
"(e.g., caffe2::Tensor x(CPU), prior to calling mutable_data<T>() on x)");
return data_type_.itemsize();
}
protected:
Storage storage_;
};
c10/core/TensorImpl.cpp
#include <c10/core/TensorImpl.h> -> c10/core/TensorImpl.h
IntArrayRef TensorImpl::sizes() const {
return sizes_;
}
bool TensorImpl::has_storage() const {
return storage_;
}
const Storage& TensorImpl::storage() const {
return storage_;
}
c10/core/Storage.h
#include <c10/core/StorageImpl.h> -> c10/core/StorageImpl.h
struct C10_API Storage {
public:
size_t nbytes() const {
return storage_impl_->nbytes();
}
// get() use here is to get const-correctness
void* data() const {
return storage_impl_.get()->data();
}
at::DataPtr& data_ptr() {
return storage_impl_->data_ptr();
}
const at::DataPtr& data_ptr() const {
return storage_impl_->data_ptr();
}
at::Allocator* allocator() const {
return storage_impl_.get()->allocator();
}
protected:
c10::intrusive_ptr<StorageImpl> storage_impl_;
};
c10/core/StorageImpl.h
#include <c10/core/Allocator.h> -> c10/core/Allocator.h
#include <c10/core/ScalarType.h>
#include <c10/util/intrusive_ptr.h>
struct C10_API StorageImpl final : public c10::intrusive_ptr_target {
public:
size_t nbytes() const {
return size_bytes_;
}
at::DataPtr& data_ptr() {
return data_ptr_;
};
const at::DataPtr& data_ptr() const {
return data_ptr_;
};
// TODO: Return const ptr eventually if possible
void* data() {
return data_ptr_.get();
}
void* data() const {
return data_ptr_.get();
}
at::Allocator* allocator() {
return allocator_;
}
const at::Allocator* allocator() const {
return allocator_;
};
private:
DataPtr data_ptr_;
size_t size_bytes_;
Allocator* allocator_;
};
c10/core/Allocator.h
#include <c10/core/Device.h>
#include <c10/util/Exception.h>
#include <c10/util/ThreadLocalDebugInfo.h>
#include <c10/util/UniqueVoidPtr.h> -> c10/util/UniqueVoidPtr.h
class C10_API DataPtr {
private:
c10::detail::UniqueVoidPtr ptr_;
Device device_;
public:
void* get() const {
return ptr_.get();
}
};
struct C10_API Allocator {
virtual ~Allocator() = default;
virtual DataPtr allocate(size_t n) const = 0;
};
c10/util/UniqueVoidPtr.h
class UniqueVoidPtr {
private:
// Lifetime tied to ctx_
void* data_;
std::unique_ptr<void, DeleterFnPtr> ctx_;
public:
void clear() {
ctx_ = nullptr;
data_ = nullptr;
}
void* get() const {
return data_;
}
};
c10/util/intrusive_ptr.h
/**
* intrusive_ptr<T> is an alternative to shared_ptr<T> that has better
* performance because it does the refcounting intrusively
* (i.e. in a member of the object itself).
* Your class T needs to inherit from intrusive_ptr_target to allow it to be
* used in an intrusive_ptr<T>. Your class's constructor should not allow
*`this` to escape to other threads or create an intrusive_ptr from `this`.
*/
// 这个注释说明了:
// - intrusive_ptr<T> 的设计目标是提供比 shared_ptr<T> 更高效的性能。
// - 它需要类 T 继承自 intrusive_ptr_target,才能让 intrusive_ptr 管理其生命周期。
// - 类 T 的构造函数中不应允许 this 指针在构造期间被暴露(用于防止构造期间引用泄漏)。
// Note [Stack allocated intrusive_ptr_target safety]
// ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
// A well known problem with std::enable_shared_from_this is that it
// allows you to create a std::shared_ptr from a stack allocated object,
// which is totally bogus because the object will die once you return
// from the stack. In intrusive_ptr, we can detect that this has occurred,
// because we set the refcount/weakcount of objects which inherit from
// intrusive_ptr_target to zero, *unless* we can prove that the object
// was dynamically allocated (e.g., via make_intrusive).
//
// Thus, whenever you transmute a T* into a intrusive_ptr<T>, we check
// and make sure that the refcount isn't zero (or, a more subtle
// test for weak_intrusive_ptr<T>, for which the refcount may validly
// be zero, but the weak refcount better not be zero), because that
// tells us if the object was allocated by us. If it wasn't, no
// intrusive_ptr for you!
// 这个注释解释了:
// - C++ 中 std::enable_shared_from_this 允许从栈上对象创建 shared_ptr,这在对象生命周期上是危险的(对象返回后就销毁了)。
// - intrusive_ptr 通过检查 refcount 是否为零,来防止非堆分配(stack allocation)对象被包装为 intrusive_ptr。
// - 安全措施:make_intrusive 之类的工厂函数会初始化 refcount,若用户直接用栈对象转为 intrusive_ptr,我们就能检测并拒绝。
// 这是一个基础类,供 intrusive_ptr 智能指针使用。
class C10_API intrusive_ptr_target {
// Note [Weak references for intrusive refcounting]
// ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
// Here's the scheme:
//
// - refcount == number of strong references to the object
// weakcount == number of weak references to the object,
// plus one more if refcount > 0
// An invariant: refcount > 0 => weakcount > 0
//
// - c10::StorageImpl stays live as long as there are any strong
// or weak pointers to it (weakcount > 0, since strong
// references count as a +1 to weakcount)
//
// - finalizers are called and data_ptr is deallocated when refcount == 0
//
// - Once refcount == 0, it can never again be > 0 (the transition
// from > 0 to == 0 is monotonic)
//
// - When you access c10::StorageImpl via a weak pointer, you must
// atomically increment the use count, if it is greater than 0.
// If it is not, you must report that the storage is dead.
//
// 这段注释解释了在 intrusive_ptr 和 weak_intrusive_ptr 的机制下,如何管理对象的生命周期与引用关系:
// - refcount 表示强引用计数(比如 intrusive_ptr<T> 拥有对象时);
// - weakcount 表示弱引用计数(比如 weak_intrusive_ptr<T>);
// - 只要 weakcount > 0,对象就不会被销毁;
// - 强引用也会自动增加 weakcount,所以只要还有强引用,对象就活着;
// - 当强引用计数归零时(refcount == 0),
// - 会执行“finalizers(终结器)”,比如释放数据指针、释放资源等;
// - 但对象本身还不一定会立即被析构(因为可能还有 weak 引用在追踪)。
// - 一旦强引用计数降为 0,就不能再升回大于 0;
// - 若你通过 weak_intrusive_ptr<T> 尝试访问对象:
// - 需要先原子地尝试增加 refcount;
// - 若 refcount > 0,表示对象还活着,增加成功;
// - 否则,refcount == 0,则表示对象已死,不可访问,需返回失败。
// 强引用计数(对应 intrusive_ptr<T> 的数量)。
mutable std::atomic<uint32_t> refcount_;
// 弱引用计数(weak_intrusive_ptr<T> 的数量)+(当 refcount > 0 时加 1)。
mutable std::atomic<uint32_t> weakcount_;
// 友元类声明:这些类(和函数)需要访问 refcount_ 和 weakcount_,所以成为友元。
template <typename T, typename NullType>
friend class intrusive_ptr;
friend inline void raw::intrusive_ptr::incref(intrusive_ptr_target* self);
template <typename T, typename NullType>
friend class weak_intrusive_ptr;
friend inline void raw::weak_intrusive_ptr::incref(
intrusive_ptr_target* self);
protected:
// protected destructor. We never want to destruct intrusive_ptr_target*
// directly.
// 析构函数:
// - 设计为 protected,表示你不应该直接 delete 一个 intrusive_ptr_target*。
// - 它会在析构时检查 refcount 和 weakcount 的合理性,防止未释放的引用仍然存在。
// - 使用了 TORCH_INTERNAL_ASSERT_DEBUG_ONLY(...) 进行调试期断言。
virtual ~intrusive_ptr_target() {
TORCH_INTERNAL_ASSERT_DEBUG_ONLY(); // 这里省略了代码
}
// 构造函数和拷贝操作:
// - 初始化时 refcount 和 weakcount 都为 0。
// - 拷贝和移动构造函数不会拷贝引用计数(因为那是和对象地址绑定的)。
constexpr intrusive_ptr_target() noexcept : refcount_(0), weakcount_(0) {}
// ……
private:
/**
* This is called when refcount reaches zero.
* You can override this to release expensive resources.
* There might still be weak references, so your object might not get
* destructed yet, but you can assume the object isn't used anymore,
* i.e. no more calls to methods or accesses to members (we just can't
* destruct it yet because we need the weakcount accessible).
*
* If there are no weak references (i.e. your class is about to be
* destructed), this function WILL NOT be called.
*/
/**
* 当 refcount(强引用计数)变为零时会调用这个函数。
* 你可以重写它来自行释放一些昂贵的资源。
* 此时可能仍然存在弱引用(weak references),因此对象本身可能还不会被析构,
* 但你可以认为这个对象已经不再被使用了,
* 即:不会再有方法调用或成员访问(我们只是暂时还不能销毁它,因为还需要保留 weakcount)。
*
* 如果没有任何弱引用(即你的类即将被析构),那么这个函数不会被调用。
*/
virtual void release_resources() {}
};
c10/cuda/CUDACachingAllocator.h
#include <c10/cuda/CUDAStream.h>
#include <c10/core/Allocator.h> -> c10/core/Allocator.h
#include <c10/cuda/CUDAMacros.h>
#include <c10/util/Registry.h>
namespace CUDACachingAllocator {
struct Stat {
int64_t current = 0;
int64_t peak = 0;
int64_t allocated = 0;
int64_t freed = 0;
};
enum struct StatType : uint64_t {
AGGREGATE = 0,
SMALL_POOL = 1,
LARGE_POOL = 2,
NUM_TYPES = 3 // remember to update this whenever a new stat type is added
};
typedef std::array<Stat, static_cast<size_t>(StatType::NUM_TYPES)> StatArray;
// Struct containing memory allocator summary statistics for a device.
struct DeviceStats {
// COUNT: allocations requested by client code
StatArray allocation;
// COUNT: number of allocated segments from cudaMalloc().
StatArray segment;
// COUNT: number of active memory blocks (allocated or used by stream)
StatArray active;
// COUNT: number of inactive, split memory blocks (unallocated but can't be released via cudaFree)
StatArray inactive_split;
// SUM: bytes requested by client code
StatArray allocated_bytes;
// SUM: bytes reserved by this memory allocator (both free and used)
StatArray reserved_bytes;
// SUM: bytes within active memory blocks
StatArray active_bytes;
// SUM: bytes within inactive, split memory blocks
StatArray inactive_split_bytes;
// COUNT: total number of failed calls to CUDA malloc necessitating cache flushes.
int64_t num_alloc_retries = 0;
// COUNT: total number of OOMs (i.e. failed calls to CUDA after cache flush)
int64_t num_ooms = 0;
};
// Struct containing info of an allocation block (i.e. a fractional part of a cudaMalloc)..
struct BlockInfo {
int64_t size = 0;
bool allocated = false;
bool active = false;
};
// Struct containing info of a memory segment (i.e. one contiguous cudaMalloc).
struct SegmentInfo {
int64_t device = 0;
int64_t address = 0;
int64_t total_size = 0;
int64_t allocated_size = 0;
int64_t active_size = 0;
bool is_large = false;
std::vector<BlockInfo> blocks;
};
C10_CUDA_API void* raw_alloc(size_t nbytes);
C10_CUDA_API void* raw_alloc_with_stream(size_t nbytes, cudaStream_t stream);
C10_CUDA_API void raw_delete(void* ptr);
C10_CUDA_API Allocator* get();
C10_CUDA_API void init(int device_count);
C10_CUDA_API void emptyCache();
C10_CUDA_API void cacheInfo(int dev_id, size_t* cachedAndFree, size_t* largestBlock);
C10_CUDA_API void* getBaseAllocation(void *ptr, size_t *size);
C10_CUDA_API void recordStream(const DataPtr&, CUDAStream stream);
C10_CUDA_API DeviceStats getDeviceStats(int device);
C10_CUDA_API void resetAccumulatedStats(int device);
C10_CUDA_API void resetPeakStats(int device);
C10_CUDA_API std::vector<SegmentInfo> snapshot();
C10_CUDA_API std::mutex* getFreeMutex();
C10_CUDA_API std::shared_ptr<void> getIpcDevPtr(std::string handle);
} // namespace CUDACachingAllocator
c10/cuda/CUDACachingAllocator.cpp
#include <c10/cuda/CUDACachingAllocator.h> -> c10/cuda/CUDACachingAllocator.h
#include <c10/cuda/CUDAGuard.h>
#include <c10/cuda/CUDAException.h>
#include <c10/cuda/CUDAFunctions.h>
#include <c10/util/UniqueVoidPtr.h> -> c10/util/UniqueVoidPtr.h
void* raw_alloc(size_t nbytes);
// 实现
void* raw_alloc(size_t nbytes) {
if (nbytes == 0) {
return nullptr;
}
int device;
C10_CUDA_CHECK(cudaGetDevice(&device));
void* r = nullptr;
caching_allocator.malloc(&r, device, nbytes, cuda::getCurrentCUDAStream(device));
return r;
}
---
/** allocates a block which is safe to use from the provided stream 从提供的流中分配一个可以安全使用的块
* THCCachingAllocator 类的成员函数
* 被 void* raw_alloc 调用
*/
void malloc(void** devPtr, int device, size_t size, cudaStream_t stream) {
TORCH_INTERNAL_ASSERT(
0 <= device && device < device_allocator.size(),
"Allocator not initialized for device ",
device,
": did you call init?");
// 调用device_allocator的分配函数,并且把新建的block加入到add_allocated_block中。
Block* block = device_allocator[device]->malloc(device, size, stream);
add_allocated_block(block);
*devPtr = (void*)block->ptr;
}
---
/**
* 被 THCCachingAllocator 类的成员函数 void malloc 调用
* DeviceCachingAllocator 类的成员函数
*/
Block* malloc(int device, size_t size, cudaStream_t stream)
{
std::unique_lock<std::recursive_mutex> lock(mutex);
// process outstanding cudaEvents
process_events();
// 分配512 byte倍数的数据
size = round_size(size);
// 寻找合适的内存池进行分配
auto& pool = get_pool(size);
// 根据分配segment分配分配空间
const size_t alloc_size = get_allocation_size(size);
// 把需要的数据放入params中,尤其是size、alloc_size
AllocParams params(device, size, stream, &pool, alloc_size, stats);
// 设置标志,其中stat_types包括三个标志,分别针对AGGREGATE、SMALL_POOL以及LARGE_POOL,分别有bitset进行赋值(true of false)
params.stat_types[static_cast<size_t>(StatType::AGGREGATE)] = true;
params.stat_types[static_cast<size_t>(get_stat_type_for_pool(pool))] = true;
// 最为核心的部分,包括了四个小部分。
bool block_found =
// Search pool
// 从对应大小的Pool中搜索出>=所需size的数据,并分配。
get_free_block(params)
// Trigger callbacks and retry search 手动进行一波垃圾回收,回收掉没人用的 Block,再调用 get_free_block
|| (trigger_free_memory_callbacks(params) && get_free_block(params))
// Attempt allocate
// Allocator 在已有的 Block 中找不出可分配的了,就调用 cudaMalloc 创建新的 Block。
|| alloc_block(params, false)
// Free all non-split cached blocks and retry alloc. 释放所有非分割缓存块并重试分配。
// 如果无法分配合理的空间,那么系统会调用free_cached_blocks()函数先将cache释放掉,然后再重新分配。
|| (free_cached_blocks() && alloc_block(params, true));
// 如果无法重复使用指针,也没有额外的资源分配空间。
// 该部分处理分配未成功的部分。如果走到了这里,那程序就意味着没救了,剩下的就只有崩溃。
TORCH_INTERNAL_ASSERT((!block_found && params.err != cudaSuccess) || params.block);
if (!block_found) {
if (params.err == cudaErrorMemoryAllocation) {
size_t device_free;
size_t device_total;
C10_CUDA_CHECK(cudaMemGetInfo(&device_free, &device_total));
stats.num_ooms += 1;
// "total capacity": total global memory on GPU
// "already allocated": memory allocated by the program using the
// caching allocator
// "free": free memory as reported by the CUDA API
// "cached": memory held by the allocator but not used by the program
//
// The "allocated" amount does not include memory allocated outside
// of the caching allocator, such as memory allocated by other programs
// or memory held by the driver.
//
// The sum of "allocated" + "free" + "cached" may be less than the
// total capacity due to memory held by the driver and usage by other
// programs.
//
// Note that at this point free_cached_blocks has already returned all
// possible "cached" memory to the driver. The only remaining "cached"
// memory is split from a larger block that is partially in-use.
TORCH_CHECK_WITH(CUDAOutOfMemoryError, false,
"CUDA out of memory. Tried to allocate ", format_size(alloc_size), // 使内存分配不足的最后一颗稻草。
" (GPU ", device, "; ",
format_size(device_total), " total capacity; ", // GPU设备的总显存大小,该值来源于cudaMemGetInfo(&device_free, &device_total),而该函数能返回gpu中的free与total显存的量。
format_size(stats.allocated_bytes[static_cast<size_t>(StatType::AGGREGATE)].current),
" already allocated; ", // 表示使用cache分配器已经分配的数据的量,对应malloc中的update_stat_array(stats.allocated_bytes, block->size, params.stat_types);
format_size(device_free), " free; ", // 为free显存的量
format_size(stats.reserved_bytes[static_cast<size_t>(StatType::AGGREGATE)].current),
" reserved in total by PyTorch)"); // 表示PyTorch中真正分配与cache后的数据,就是该值减去“已经分配的值(stats.allocated_bytes)”就是暂存在pool中的物理上已经分配但是逻辑上没有被使用的总显存大小。
} else {
C10_CUDA_CHECK(params.err);
}
}
Block* block = params.block;
Block* remaining = nullptr;
TORCH_INTERNAL_ASSERT(block);
const bool already_split = block->is_split();
// block分裂,针对get_free_block以及alloc_block情况(复用cache的指针以及重新分配)
if (should_split(block, size)) {
remaining = block;
// 新建一个block,其大小为size,而不是alloc_size(因为alloc_size实际大小过大,需要分裂)
block = new Block(device, stream, size, &pool, block->ptr);
// 在原来的block链中间插入新的block,而把原来的block转化为remaining,添加到新block的后面
block->prev = remaining->prev;
if (block->prev) {
block->prev->next = block;
}
block->next = remaining;
remaining->prev = block;
remaining->ptr = static_cast<char*>(remaining->ptr) + size;
// 将remaining块缩小
remaining->size -= size;
pool.insert(remaining);
if (already_split) {
// An already-split inactive block is being shrunk by size bytes.
update_stat_array(stats.inactive_split_bytes, -block->size, params.stat_types);
} else {
// A new split inactive block is being created from a previously unsplit block,
// size remaining->size bytes.
update_stat_array(stats.inactive_split_bytes, remaining->size, params.stat_types);
update_stat_array(stats.inactive_split, 1, params.stat_types);
}
} else if (already_split) {
// An already-split block is becoming active
update_stat_array(stats.inactive_split_bytes, -block->size, params.stat_types);
update_stat_array(stats.inactive_split, -1, params.stat_types);
}
block->allocated = true;
// active_blocks中存储的是正在使用的block,insert表示将新建立的block插入到这个集合中
active_blocks.insert(block);
c10::reportMemoryUsageToProfiler(
block, block->size, c10::Device(c10::DeviceType::CUDA, device));
// 以此保存内存分配次数、内存分配byte大小、正在使用的数据个数、正在使用的数据大小
update_stat_array(stats.allocation, 1, params.stat_types);
update_stat_array(stats.allocated_bytes, block->size, params.stat_types);
update_stat_array(stats.active, 1, params.stat_types);
update_stat_array(stats.active_bytes, block->size, params.stat_types);
return block;
}
---
std::mutex mutex;
// allocated blocks by device pointer 通过设备指针分配块
// 在缓存分配器中跟踪分配的内存块。
/**
这行代码声明了一个名为 allocated_blocks 的 std::unordered_map 容器。
这个哈希表将 void* 类型的键(在本例中是设备指针,指向分配的内存)映射到 Block* 类型的值
(Block 结构体代表分配的内存块的信息)。
std::unordered_map 基于哈希表实现,提供了平均常数时间复杂度的查找、插入和删除操作。
*/
std::unordered_map<void*, Block*> allocated_blocks;
/**
* THCCachingAllocator 类的成员函数
* 将新分配的内存块添加到 allocated_blocks 哈希表中。
*
* 被 THCCachingAllocator 类的成员函数 void malloc 调用
*/
void add_allocated_block(Block* block) {
std::lock_guard<std::mutex> lock(mutex);
allocated_blocks[block->ptr] = block;
}
void* raw_alloc_with_stream(size_t nbytes, cudaStream_t stream);
// 实现
void* raw_alloc_with_stream(size_t nbytes, cudaStream_t stream) {
if (nbytes == 0) {
return nullptr;
}
int device;
C10_CUDA_CHECK(cudaGetDevice(&device));
void* r = nullptr;
// 和 id* raw_alloc(size_t nbytes) 的实现区别在指定 stream
caching_allocator.malloc(&r, device, nbytes, stream);
return r;
}
raw_delete(void* ptr);
// void raw_delete(void* ptr); 的实现
void raw_delete(void* ptr) {
caching_allocator.free(ptr);
}
---
/**
* THCCachingAllocator 类的成员函数
* 被 void raw_delete 调用
*/
void free(void* ptr) {
if (!ptr) {
return;
}
Block* block = get_allocated_block(ptr, true /* remove */);
if (!block) {
AT_ERROR("invalid device pointer: ", ptr);
}
device_allocator[block->device]->free(block);
}
---
/**
* THCCachingAllocator 的成员函数
* 被 void free 调用
*/
Block* get_allocated_block(void *ptr, bool remove=false) {
std::lock_guard<std::mutex> lock(mutex);
auto it = allocated_blocks.find(ptr);
if (it == allocated_blocks.end()) {
return nullptr;
}
Block* block = it->second;
if (remove) {
allocated_blocks.erase(it);
}
return block;
}
---
/**
* 被 THCCachingAllocator 的成员函数 void free 调用
*/
void free(Block* block)
{
std::lock_guard<std::recursive_mutex> lock(mutex);
block->allocated = false;
c10::reportMemoryUsageToProfiler(
block, -block->size, c10::Device(c10::DeviceType::CUDA, block->device));
// 更新全局的记录
StatTypes stat_types;
stat_types[static_cast<size_t>(StatType::AGGREGATE)] = true;
stat_types[static_cast<size_t>(get_stat_type_for_pool(*(block->pool)))] = true;
update_stat_array(stats.allocation, -1, {stat_types});
update_stat_array(stats.allocated_bytes, -block->size, {stat_types});
// 判断stream是不是空的
if (!block->stream_uses.empty()) {
// stream_uses不是空,则进入
insert_events(block);
} else {
// 是空的进入
free_block(block);
}
}
void* getBaseAllocation(void *ptr, size_t *size);
// void* getBaseAllocation(void *ptr, size_t *size); 的实现
void* getBaseAllocation(void *ptr, size_t *size)
{
return caching_allocator.getBaseAllocation(ptr, size);
}
---
// THCCachingAllocator 类的成员函数,被 void* getBaseAllocation 调用
void* getBaseAllocation(void* ptr, size_t* outSize)
{
Block* block = get_allocated_block(ptr);
if (!block) {
AT_ERROR("invalid device pointer: ", ptr);
}
return device_allocator[block->device]->getBaseAllocation(block, outSize);
}
---
/**
* 被 THCCachingAllocator 类的成员函数 void* getBaseAllocation 调用
*/
void* getBaseAllocation(Block* block, size_t* outSize) {
std::lock_guard<std::recursive_mutex> lock(mutex);
while (block->prev) { // 找到一个 segment 的头指针
block = block->prev;
}
void *basePtr = block->ptr; // 找到了,暂存给 basePtr
if (outSize) {
size_t size = 0;
while (block) {
size += block->size;
block = block->next;
}
*outSize = size; // 求的应该是这个 segment 的长度
}
return basePtr;
}


















 2898
2898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









