







 本文深入探讨了KNN算法的基本原理,包括算法的通用步骤、距离计算方法、k值选择的重要性及其对分类效果的影响。通过一个实际案例,演示了如何使用Python进行数据读取、距离计算、排序、k值选取及最终的加权平均预测,同时提供了完整的代码实现。
本文深入探讨了KNN算法的基本原理,包括算法的通用步骤、距离计算方法、k值选择的重要性及其对分类效果的影响。通过一个实际案例,演示了如何使用Python进行数据读取、距离计算、排序、k值选取及最终的加权平均预测,同时提供了完整的代码实现。
数据集可以在下方留言找我要
或者

一、认识knn算法
寻找最近的k个数据,推测新数据的分类。
二、算法原理
通用步骤
- 计算距离(常用欧几里得距离或者马氏距离)
- 升序排序
- 取前k个
- 加权平均
k的选取
- k太大:导致分类模糊
- k太小:受个例影响,波动较大
如何选取k
- 经验
- 均方根误差
读取数据
import csv
with open('E:\资资\python练习\knn\Prostate_Cancer.csv','r') as file:
#DictReader把数据读成字典
reader = csv.DictReader(file)
datas=[row for row in reader]
print(datas)

算距离
K=5
def knn(data):
#1距离
res = [
{"result":train['diagnosis_result'],"distance":distance(data,train)}
for train in train_set
]
print(res)
knn(test_set[0])

#2排序
res = sorted(res,key=lambda item:item['distance'])
print(res)
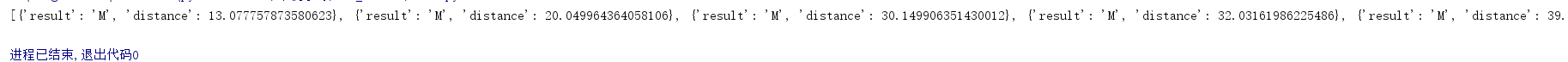
knn
def knn(data):
#1距离
res = [
{"result":train['diagnosis_result'],"distance":distance(data,train)}
for train in train_set
]
#2排序
res = sorted(res,key=lambda item:item['distance'])
#取前k个
res2=res[0:K]
#加权平均
result={'B':0,'M':0}
#总距离
sum = 0
for r in res2:
sum+=r['distance']
#距离进的权重反而高
for r in res2:
result[r['result']]+=1-r['distance']/sum
#输出预测的结果
print(result)
#输出本身结果
print(data['diagnosis_result'])


测试
#测试阶段
correct=0
for test in test_set:
result=test['diagnosis_result']
result2=knn(test)
if result==result2:
correct+=1
print("准确率:{:.2f}%".format(100*correct/len(test_set)))
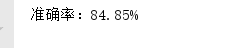
三、完整代码
import random
import csv
#数据读取
with open('E:\资资\python练习\knn\Prostate_Cancer.csv','r') as file:
#DictReader把数据读成字典
reader = csv.DictReader(file)
datas=[row for row in reader]
#分组
#分成训练集和测试集
#打乱顺序,防止偶然性
random.shuffle(datas)
n = len(datas)//3
test_set = datas[0:n]
train_set = datas[n:]
#KNN
#距离
def distance(d1,d2):
res = 0
for key in ("radius","texture","perimeter","area","smoothness","compactness","symmetry","fractal_dimension"):
res += (float(d1[key])-float(d2[key]))**2
return res**0.5
K=5
def knn(data):
#1距离
res = [
{"result":train['diagnosis_result'],"distance":distance(data,train)}
for train in train_set
]
#2排序
res = sorted(res,key=lambda item:item['distance'])
#取前k个
res2=res[0:K]
#加权平均
result={'B':0,'M':0}
#总距离
sum = 0
for r in res2:
sum+=r['distance']
#距离进的权重反而高
for r in res2:
result[r['result']]+=1-r['distance']/sum
#输出预测的结果
#print(result)
#输出本身结果
#print(data['diagnosis_result'])
if result['B']>result['M']:
return 'B'
else:
return 'M'
#测试阶段
correct=0
for test in test_set:
result=test['diagnosis_result']
result2=knn(test)
if result==result2:
correct+=1
print("准确率:{:.2f}%".format(100*correct/len(test_set)))

















 1409
1409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









