







本文基本不设语言门槛,只讲大白话,力求让纯萌新也能理解扩散模型。
但这并不代表本文内容浅显,实际上本文从生成模型这个宏观的角度,告诉读者扩散模型做了什么,以及更重要的,为什么要这么做。
本文适合谁来学
现在网上有很多文章和视频来介绍Diffusion Model扩散模型,很多都是在围绕“加噪去噪”这个概念来讲,这样讲并没有错,因为扩散模型的核心确实是“加噪去噪”,但是笔者总觉得这还不够本质。希望能从生成模型的角度,用更加系统的观点来讲述扩散模型。请放心,本文只讲大白话,非常适合无扩散模型基础的同学阅读。
本文适合哪些读者:
-
如果你了解一点深度学习、有一点概率统计的知识(了解或学过就可以,本文会带你复习),但是完全不了解扩散模型,那本文很适合你。
-
如果你简单了解过扩散模型,但是有包括但不限于以下几个问题:
- 扩散模型属于生成模型,那么它和生成模型有什么关系?
- 为什么通过“加噪去噪”就能把图像生成出来?
- 都说扩散模型预测“噪声”,为什么预测“噪声”就能生成清晰的图像?
- 直接在推理的时候反向去噪不就行了,前向扩散的意义是什么?
-
如果你很了解扩散模型,但希望从生成模型的角度重新审视一下Diffusion。
本文不合适哪些读者:
- 希望学习到扩散模型每一步详细的数学推理过程(本文有数学推理过程,但是部分会省略)。
- 希望结合代码来学习扩散模型的模型结构。
- 完全不了解深度学习,没有学过概率统计相关知识。
文章目录:
文章目录
好的,那我们开始今天的学习~
本文参考视频 【较真系列】讲人话-Diffusion Model全解(原理+代码+公式)
生成模型
要理解扩散模型,首先要理解生成模型。
定义
直观来说,生成模型就是一个能生成和训练数据一致(或类似)的数据的模型。
这个生成可以是有条件的,训练数据也可以是任何形式的数据。
例如:如果生成的条件是“文字”,训练数据是“图片”,那它就是个“文生图”模型,比如基于Stable Diffusion的Midjourney。如果生成的条件是“文字”,训练数据是“音乐”,那它就是个“文生音乐”模型,比如Suno。
动机
理解一个事物,要从它的动机入手。
例如:一对情侣,男友有一天周末早上突然不高兴,对着手机一个唉声叹气。女生说一句:“今天天好蓝,我们出去玩吧。”男生说:“蓝,还不如不蓝。很蓝的啦~”女生会觉得不理解啊,甚至开始内耗担心自己是不是做错什么了。这就是不理解动机,只能自己瞎猜,很难理解事物。这时候女生去问了男生的好哥们,得知原来是意大利昨晚又双叕输球了。嗷,这下明白了!原来和自己没关系,是喜欢的球队输了球。女生不会内耗了,甚至还可以去安慰男生。这就是找到动机的作用。
要理解生成模型,首先需要理解生成模型的动机。
如果让算法工程师做一个生成模型,或者说让他根据一些训练数据,生成类似的数据,他会考虑两个问题:
- 如何对训练数据建模
- 生成过程中如何采样
理解生成模型的动机,首先要理解建模与采样的概念。
建模与采样
概念
现在有一堆数据,这些数据可能有某种规律,但是我们不知道,我们可以对这些数据进行建模或者采样。
建模:构建模型——理解这些数据的规律,构建一个具备这些数据规律的模型。
采样:采集样本——从这些数据中,采集一个数据。根据建模的规律,生成一个类似的新的数据。
举例
以让算法生成人脸照片的任务为例,
- 算法根据人脸数据集训练的过程就是“建模”,
- 用训练好的模型和输入的条件,生成人脸的过程就是“采样”。
进一步的,在算法根据人脸数据集训练的时候,算法学到的”人脸都是两个眼睛,一个鼻子,鼻子在眼睛正中间的下方位置…“,就是一些“特征”。至于“宽下颌并且有胡子的脸70%都是短直发,窄下颌并且没有胡子的脸50%会有长发”,这就是“分布”。
所以说,建模也就是学习特征和分布的过程。
在建模完成后,在采样过程中,模型会根据学到的分布,和我们输入的条件,生成符合现实规律的特征组合。
例如:如果训练数据中90%黑头发的人都是黑眼睛,但也有个别黑发妹子戴蓝色美瞳的。我们输入的条件是“黑头发”,于是模型就学会了“生成黑头发+黑眼睛的人脸更保险,但偶尔可以生成黑头发+蓝眼睛”。
也就是说,采样是根据建模和条件进行生成的过程。
之前我们说一堆数据,那么现在我们知道了,因为这些数据具有某种规律,所以这些数据可以被称为一个分布。而“采样”通常指从分布中抽取样本。
那我们现在就可以说,生成模型就是建模一个分布,并从这个分布中进行采样。
从简单分布采样——高斯分布
了解了建模与采样的概念,就能理解生成模型的目标了:
-
对训练数据建好模
-
生成过程中采好样
但是,一般来说训练数据是很复杂的,所以建模起来很难。即使建立了一个很复杂的模型,从里面采样数据也很难了。那怎么办呢?
我们知道,从一个简单分布采样肯定比从训练数据分布采样容易,而从简单分布到训练数据分布是可以转化的。也就是说,我们可以将训练数据先转化成一个简单分布,然后从这个简单分布上采样,再将采样转化成符合训练数据分布的图片。
如下图:
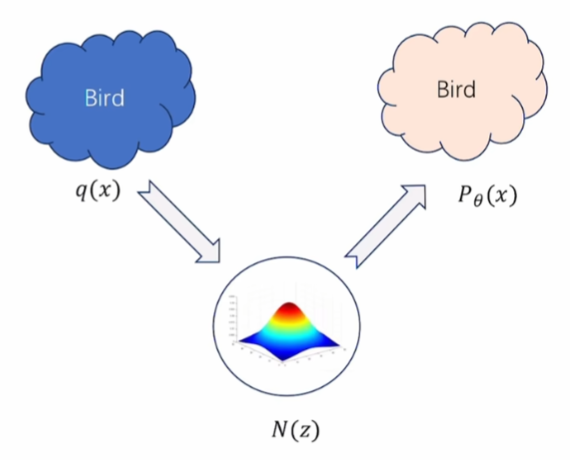
我们可以先将训练数据分布 q ( x ) q(x) q(x)(左侧蓝色的Bird图像)转化成一个简单分布 N ( z ) N(z) N(z),在这个简单分布上采样,然后将采样结果转化成与训练数据类似的数据分布 P θ ( x ) P_{\theta}(x) Pθ(x)(右侧粉色的Bird图像)。
这里的 z z z是一个低维的变量。
关于 z z z: z z z的维度远低于原始数据 x x x。例如,图像可能是几千维,而 z z z可能只有几十维。关于数据 x x x(如鸟的图像)的复杂分布可以映射到一个关于 z z z的简单分布,其中 z z z的每个维度对应数据中的某种抽象特征(如翅膀形状、颜色、姿态等),所以也可以称 z z z是潜变量或者隐变量,即 Latent Variable。
对于扩散模型而言, N ( z ) N(z) N(z)是一个高斯分布, z z z其实就是高斯分布的( μ \mu μ, σ \sigma σ),下一章会详细讲。
θ \theta θ指的是可学习的参数。
关于 θ \theta θ: 如果说 P θ ( x ) P_{\theta}(x) Pθ(x)是一个高斯分布,那 θ \theta θ也就包括一对可学习的 μ \mu μ和 σ \sigma σ,但生成模型的 P θ ( x ) P_{\theta}(x) Pθ(x)基本不可能是一个简单的高斯分布了,它可能是很多高斯分布的组合(这个在高斯混合模型部分会提到),所以 θ \theta θ是比较复杂的。
生成模型的本质其实就是,通过学习一个参数化的分布 P θ ( x ) P_{\theta}(x) Pθ(x),使其尽可能逼近真实数据分布 q ( x ) q(x) q(x)。
那么生成模型的动机其实就是:
- 训练一个模型,将训练数据分布 q ( x ) q(x) q(x)映射到简单分布 N ( z ) N(z) N(z),也就是Encoder
- 训练一个模型,将简单分布 N ( z ) N(z) N(z)映射到数据分布 P θ ( x ) P_{\theta}(x) Pθ(x),也就是Decoder
现在肯定有人想问,这个简单分布 N ( z ) N(z) N(z)具体是什么分布呢?这里我们一般采用高斯分布作为这个简单分布。
高斯分布与高斯混合模型(GMM)
高斯分布也叫做正态分布,它们是相同的概念。
我们说,若随机变量X服从一个数学期望为 μ μ μ、方差为 σ 2 σ^2 σ2的高斯分布,则记为 N ( μ , σ 2 ) N(μ,σ^2) N(μ,σ2)。高斯分布的期望值 μ μ μ决定了其位置,其标准差 σ σ σ决定了分布的幅度。当 μ = 0 , σ = 1 μ = 0,σ = 1 μ=0,σ=1时的高斯分布是标准高斯分布。
下图中的曲线都是高斯分布的概率密度函数,其中红色曲线代表了标准高斯分布。
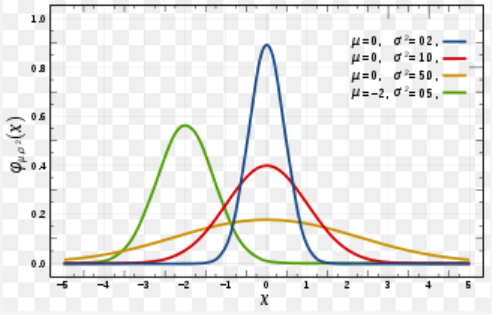
那为什么采用高斯分布而不是其他的简单分布来表示复杂分布呢?其中一个原因是:一个复杂分布可以用多个高斯分布来表示。那么用多个高斯分布来表示一个复杂分布的方法,就是高斯混合模型。
高斯混合模型的概率密度函数是这样的:
p
(
x
)
=
∑
K
k
=
1
w
k
⋅
N
(
x
∣
z
k
)
p(x) = \sum_{K}^{k=1} w_k \cdot N (x|z_k)
p(x)=K∑k=1wk⋅N(x∣zk)
其中
N
(
x
∣
z
k
)
N (x|z_k)
N(x∣zk)是第
k
k
k个高斯分布的概率密度,
w
k
w_k
wk表示该概率密度的权重,并且
∑
K
k
=
1
w
k
=
1
\sum_{K}^{k=1} w_k = 1
∑Kk=1wk=1。也就是说它就是将多个高斯分布按照权重进行加和。
N ( x ∣ z ) N(x|z) N(x∣z)是什么意思:符号 N ( x ∣ z ) N(x∣z) N(x∣z) 表示 “在给定 z z z 的条件下, x x x 服从高斯分布”。 竖线 ∣ | ∣ 表示条件关系,代表这是一个条件概率分布。竖线后面的符号可以是参数、潜在变量或另一个随机变量。这里的 z z z 指的是高斯概率的参数,也就是 z = ( μ , σ 2 ) z=(μ,σ^2) z=(μ,σ2),即 N ( x ∣ z ) = N ( x ∣ μ , σ 2 ) N(x∣z)=N(x∣μ,σ^2) N(x∣z)=N(x∣μ,σ2)。
既然 w w w表示概率密度的权重,它肯定满足一种分布,那我们不妨认为 w w w满足高斯分布(因为高斯分布在自然界中是非常常见的分布形式)。那么既然 ∑ K k = 1 w k = 1 \sum_{K}^{k=1} w_k = 1 ∑Kk=1wk=1, 也就是 ∫ w = 1 \int w = 1 ∫w=1,所以 w w w不仅满足高斯分布,而且还是标准高斯分布,也就是 w ∼ N ( 0 , 1 ) w \sim N(0,1) w∼N(0,1)。
于是,我们把
∑
K
k
=
1
w
k
\sum_{K}^{k=1} w_k
∑Kk=1wk替换成
∫
w
\int w
∫w,高斯混合模型的概率密度函数就变成了:
p
(
x
)
=
∫
w
⋅
N
(
x
∣
z
)
p(x) = \int w \cdot N (x|z)
p(x)=∫w⋅N(x∣z)
这时候,我们把生成模型需要表示的数据分布
P
θ
(
x
)
P_{\theta}(x)
Pθ(x)带入过来。之前说一个复杂分布可以用多个高斯分布来表示,那我们可以用高斯混合模型,来使用多个高斯分布表示训练数据分布
P
θ
(
x
)
P_{\theta}(x)
Pθ(x)。也就是:
P
θ
(
x
)
=
∫
w
⋅
N
(
x
∣
z
)
P_{\theta}(x) = \int w \cdot N (x|z)
Pθ(x)=∫w⋅N(x∣z)
如果我们再将
w
w
w和
z
z
z建立一个映射关系
P
P
P,也就是
w
=
P
(
z
)
w = P(z)
w=P(z),那么函数就变成了:
P
θ
(
x
)
=
∫
P
(
z
)
⋅
N
(
x
∣
z
)
P_{\theta}(x) = \int P(z) \cdot N (x|z)
Pθ(x)=∫P(z)⋅N(x∣z)
这也就是生成模型需要表示的数据分布
P
θ
(
x
)
P_{\theta}(x)
Pθ(x)的高斯混合模型形式。
优化目标 θ \theta θ——极大似然估计(MLE)
之前我们说过生成模型的本质:
生成模型的本质其实就是,通过学习一个参数化的分布 P θ ( x ) P_{\theta}(x) Pθ(x),使其尽可能逼近真实数据分布 q ( x ) q(x) q(x)。
虽然分布 P θ ( x ) P_{\theta}(x) Pθ(x)一共有三个字母,但 P ( ) P() P()只是在表示它是个分布,而 x x x是这个分布的变量,所以其实能学的只有参数 θ \theta θ。于是,生成模型的其实就是在学习这个 θ \theta θ,使得 P θ ( x ) P_{\theta}(x) Pθ(x)尽可能逼近真实数据分布 q ( x ) q(x) q(x)。
那么如何去求得 θ \theta θ呢,就需要用到极大似然估计(Maximum Likelihood Estimation, MLE),这是一种通过最大化观测数据出现的概率来估计模型参数的方法。什么意思,就是就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值。
例如:对于分布 P θ ( x ) P_{\theta}(x) Pθ(x),我们并不知道 θ \theta θ,但是我们如果可以获得这个分布中的n个采样,得到 x 1 , x 2 . . . x n x_1,x_2...x_{n} x1,x2...xn。那么我们就可以估计一个 θ ∗ \theta^{*} θ∗,使得 P θ ∗ ( x ) P_{\theta^{*}}(x) Pθ∗(x)中最有可能有 x 1 , x 2 . . . x n x_1,x_2...x_{n} x1,x2...xn。这个 θ ∗ \theta^{*} θ∗就是极大似然估计出来的 θ \theta θ值。
那我们知道 P θ ( x ) P_{\theta}(x) Pθ(x)表示在参数 θ \theta θ 下,随机变量取值为 x x x 的概率(或概率密度)。那也就是说 P θ ( x ) P_{\theta}(x) Pθ(x)最大的时候,随机变量取值为 x x x 的概率最大,于是我们让 P θ ( x ) P_{\theta}(x) Pθ(x)最大就可以了。
事实上,我们可以求得 l o g ( P θ ( x ) ) log(P_{\theta}(x)) log(Pθ(x))的最大值,并以此求得 P θ ( x ) P_{\theta}(x) Pθ(x)的最大值。
假设 q ( z ∣ x ) q(z|x) q(z∣x)为一个概率分布,可以推算得到
l o g ( P θ ( x ) ) ≥ ∫ l o g ( P θ ( x , z ) q ( z ∣ x ) ) q ( z ∣ x ) d z log(P_{\theta}(x)) \geq \int log\left ( \frac{P_\theta(x,z)}{q(z|x)} \right ) q(z|x)dz log(Pθ(x))≥∫log(q(z∣x)Pθ(x,z))q(z∣x)dz
可以写成期望的形式, E ( x ) = ∫ x f ( x ) d x E(x) = \int x f(x) dx E(x)=∫xf(x)dx,所以转换成:
l o g ( P θ ( x ) ) ≥ E q ( z ∣ x ) [ ∫ l o g ( P θ ( x , z ) q ( z ∣ x ) ) ] log(P_{\theta}(x)) \geq E_{q(z|x)}\left [ \int log\left ( \frac{P_\theta(x,z)}{q(z|x)} \right ) \right ] log(Pθ(x))≥Eq(z∣x)[∫log(q(z∣x)Pθ(x,z))]
所以只要让 E q ( z ∣ x ) [ ∫ l o g ( P θ ( x , z ) q ( z ∣ x ) ) ] E_{q(z|x)}\left [ \int log\left ( \frac{P_\theta(x,z)}{q(z|x)} \right ) \right ] Eq(z∣x)[∫log(q(z∣x)Pθ(x,z))]这个 l o g ( P θ ( x ) ) log(P_{\theta}(x)) log(Pθ(x))的最小值最大,那么 l o g ( P θ ( x ) ) log(P_{\theta}(x)) log(Pθ(x))也会最大。
对于扩散模型,我们会最大化这个最小值 E q ( z ∣ x ) [ ∫ l o g ( P θ ( x , z ) q ( z ∣ x ) ) ] E_{q(z|x)}\left [ \int log\left ( \frac{P_\theta(x,z)}{q(z|x)} \right ) \right ] Eq(z∣x)[∫log(q(z∣x)Pθ(x,z))],并将此作为Loss,这个我们后面会讲到。
生成模型了解完毕,下面开始具体来看今天的主角——扩散模型。
Diffusion Model
请注意这里的Diffusion Model指的是Denoising Diffusion Probabilistic Model,也就是DDPM,是最经典的扩散模型。如果想了解可以跨步骤采样的Denoising Diffusion Implicit Model(DDIM),可以阅读博主专门讲解DDIM的文章《大白话 | 快速理解扩散模型【DDIM】Denoising Diffusion Implicit Model》。
加噪去噪
一提到扩散模型,大家都会说到 “加噪去噪” 这个概念,那么加噪去噪的本质是什么呢?
这就要来看咱们之前提到的生成模型的动机:
- 训练一个模型,将训练数据分布 q ( x ) q(x) q(x)映射到简单分布 N ( z ) N(z) N(z),也就是Encoder
- 训练一个模型,将简单分布 N ( z ) N(z) N(z)映射到数据分布 P θ ( x ) P_{\theta}(x) Pθ(x),也就是Decoder
加噪其实就是Encoder将训练数据分布 q ( x ) q(x) q(x)映射到简单分布 N ( z ) N(z) N(z)的过程,去噪其实就是Decoder将简单分布 N ( z ) N(z) N(z)映射到数据分布 P θ ( x ) P_{\theta}(x) Pθ(x)的过程。
前向扩散过程——加噪
前向扩散过程就是向观测数据中逐步加入噪声,每次加噪声操作是对前一次加完噪声的结果操作,直到观测数据分布变成高斯分布。这里的观测数据,表示我们能观测到的数据,在实际操作中也就是训练数据。你看看,这是不是生成模型的动机第一条,“将训练数据分布 q ( x ) q(x) q(x)映射到简单分布 N ( z ) N(z) N(z)“?
如下图所示,在训练过程中,我们会将训练数据(清晰图片)一步步添加高斯噪声,使其变成纯高斯噪声(高斯分布):
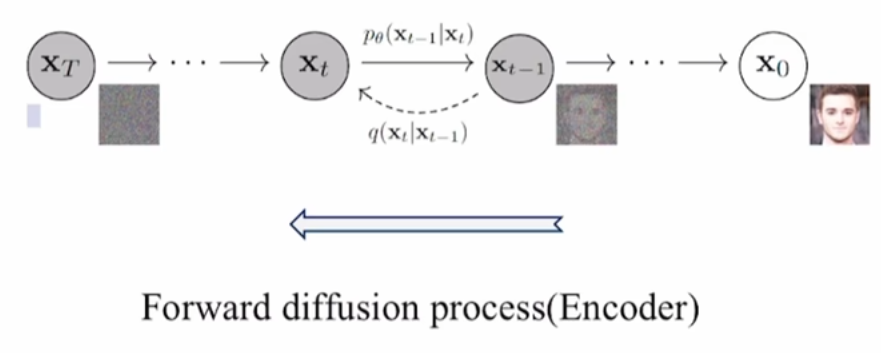
具体的加噪过程,可以用这个公式来表示:
x
t
=
1
−
β
t
∗
x
t
−
1
+
β
t
∗
ε
t
−
1
x_{t} = \sqrt{1-\beta_{t}}*x_{t-1} + \sqrt{\beta_{t}}*\varepsilon _{t-1}
xt=1−βt∗xt−1+βt∗εt−1
我们借助下图一起来看这个式子:
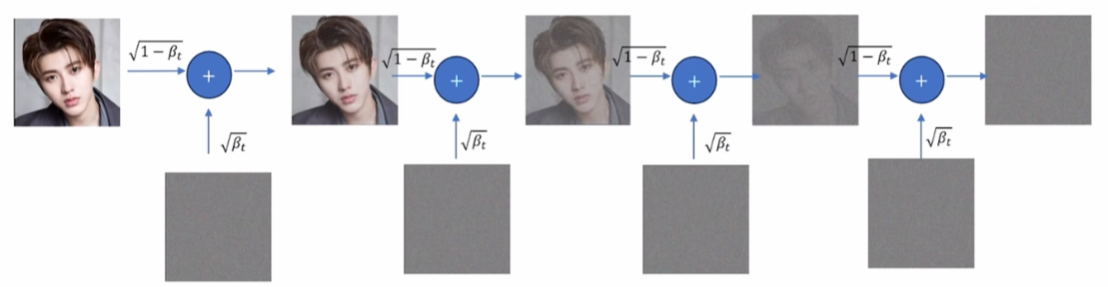
这个式子可以看做一个状态转移方程, x t x_t xt就是这张图片, t t t代表第 t t t次加噪操作, x t − 1 x_{t-1} xt−1是上一张图片, ε t − 1 \varepsilon _{t-1} εt−1是一个标准高斯噪声。其中从标准高斯分布里提取这个噪声 ε t − 1 \varepsilon _{t-1} εt−1的过程,就叫从标准高斯分布中采样。
这张图片 x t x_t xt是怎么来的呢,就是上一张图片 x t − 1 x_{t-1} xt−1加上 ε t − 1 \varepsilon _{t-1} εt−1得到的。但是这个相加呢,不是直接相加,还要各自乘上一个权重。这个权重并不是一个定值,而是带有 β t \beta_t βt,是一个和t相关的参数。
在DDPM中,参数 β t \beta_t βt会随着 t t t的增大越来越接近1,也就是说越到后面标准高斯噪声加的比重越大,越到后面越下猛药。最后,这张图片会变成纯高斯分布的噪声,并且还是标准高斯分布。也就是观测数据分布变成高斯分布。
重参数采样
这里会遇到一个问题,如果使得最后的 x t x_{t} xt是高斯噪声,是不是还差了点什么?
如果最后会变成纯高斯噪声, x t x_{t} xt是噪声没问题,但 x t x_{t} xt真的满足高斯分布吗?
我们知道 x t = 1 − β t ∗ x t − 1 + β t ∗ ε t − 1 x_{t} = \sqrt{1-\beta_{t}}*x_{t-1} + \sqrt{\beta_{t}}*\varepsilon _{t-1} xt=1−βt∗xt−1+βt∗εt−1,你会发现这个式子里只有 ε t − 1 \varepsilon _{t-1} εt−1满足高斯分布,并不仅仅能以此能说明 x t x_{t} xt满足高斯分布。
此时就需要引入重参数采样的概念: 假设 ε \varepsilon ε是标准高斯分布,即 ε ∼ N ( 0 , 1 ) \varepsilon \sim N(0,1) ε∼N(0,1),那么如果有 y = σ ∗ ε + μ y=\sigma * \varepsilon + \mu y=σ∗ε+μ,则 y ∼ N ( μ , σ 2 ) y \sim N(\mu,\sigma^2) y∼N(μ,σ2)。
也就是说, 已知 ε t − 1 ∼ N ( 0 , 1 ) \varepsilon _{t-1} \sim N(0,1) εt−1∼N(0,1),那么 x t ∼ N ( 1 − β t ∗ x t − 1 , β t ) x_{t} \sim N(\sqrt{1-\beta_{t}}*x_{t-1},\beta_{t}) xt∼N(1−βt∗xt−1,βt)。于是证明了 x t x_{t} xt满足高斯分布。所以其实得到 x t x_{t} xt的过程,也可以称为从一个高斯分布 N ( 1 − β t ∗ x t − 1 , β t ) N(\sqrt{1-\beta_{t}}*x_{t-1},\beta_{t}) N(1−βt∗xt−1,βt)中采样的过程。
直接推导 x t x_t xt
其实
x
t
x_t
xt不需要从
x
0
x_0
x0,
x
1
x_1
x1,…,
x
t
−
1
x_{t-1}
xt−1这样一步步逐步得到,它其实是可以根据
x
0
x_0
x0和
t
t
t直接推导得到的:
x
t
=
α
t
‾
∗
x
0
+
1
−
α
t
‾
∗
ε
x_{t} = \sqrt{\overline{\alpha _{t}}}*x_{0} + \sqrt{1-\overline{\alpha _{t}}}*\varepsilon
xt=αt∗x0+1−αt∗ε
其中,
α
t
‾
=
∏
i
=
1
t
α
i
\overline{\alpha_{t}} = \prod_{i=1}^{t} \alpha_{i}
αt=∏i=1tαi,
α
i
=
1
−
β
i
\alpha _{i} = 1 - \beta _{i}
αi=1−βi。
如果以图片的形式表示就是:
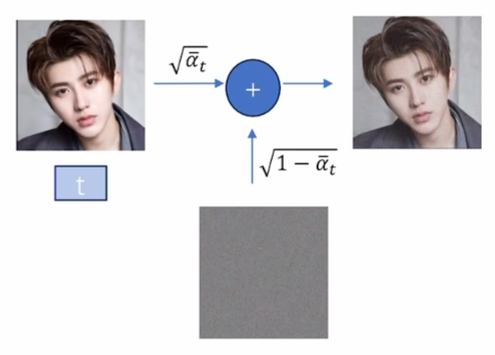
如果使用重参数采样,那么我们就能推导出,以
x
0
x_0
x0作为条件的分布
q
(
x
t
∣
x
0
)
q(x_t|x_0)
q(xt∣x0)是一个高斯分布
N
(
x
t
;
α
t
‾
⋅
x
0
,
(
1
−
α
t
‾
)
I
)
N(x_t;\sqrt{\overline{\alpha _{t}}} \cdot x_0, (1-\overline{\alpha _{t}})I)
N(xt;αt⋅x0,(1−αt)I),
I
I
I代表了标准高斯分布。也就是说:
q
(
x
t
∣
x
0
)
=
N
(
x
t
;
α
t
‾
⋅
x
0
,
(
1
−
α
t
‾
)
I
)
q(x_t|x_0)=N(x_t;\sqrt{\overline{\alpha _{t}}} \cdot x_0, (1-\overline{\alpha _{t}})I)
q(xt∣x0)=N(xt;αt⋅x0,(1−αt)I)
q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0)是什么:之前我们说过,竖线 ∣ | ∣ 表示条件关系,代表这是一个条件概率分布。所以符号 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0) 表示 “在 x 0 x_0 x0 已知的条件下, x t x_t xt 发生的概率分布”。
我们之前讲,前向扩散过程就是将观测数据分布变成高斯分布,现在来看,也就是已知 x 0 x_0 x0求分布 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0)的过程。那根据上面的公式,我们已经可以根据 x 0 x_0 x0求分布 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0),其中所有参数都已知( β t \beta_t βt的变化是已知的)。于是我们可以说,前向扩散过程是一个确定性的过程。
具体推导过程如下:
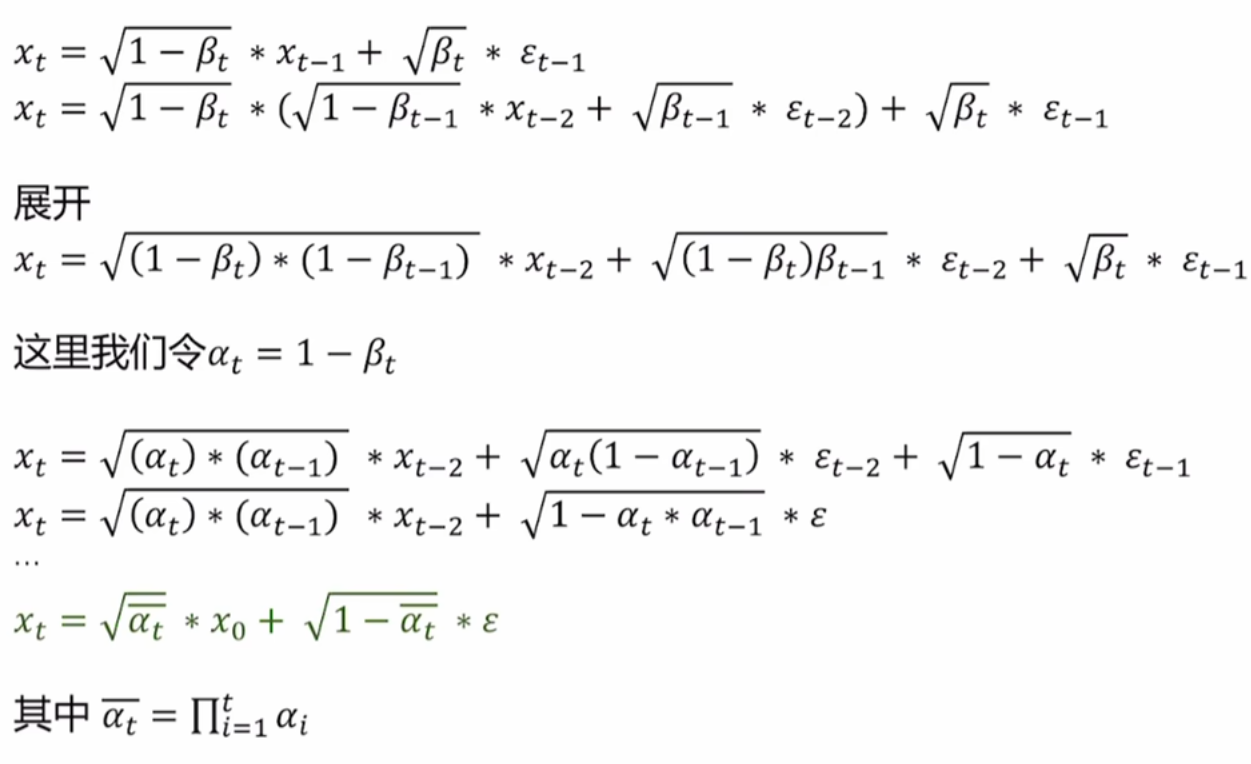
反向生成过程——去噪
反向生成过程就是:“从一个高斯分布中采样,逐步消除噪声,直到变成清晰的数据。”这句话大家可能会感到熟悉,因为这其实就是生成模型的动机第二条:“将简单分布 N ( z ) N(z) N(z)映射到数据分布 P θ ( x ) P_{\theta}(x) Pθ(x)。”
反向生成过程,就是将纯高斯分布噪声 p ( x T ) p(x_T) p(xT),一步步变成清晰数据 P θ ( x 0 ) P_\theta(x_0) Pθ(x0)的过程。
用数学公式来表示,也就是:
P
θ
(
x
0
)
=
∫
p
θ
(
x
0
:
T
)
d
x
1
:
T
P_\theta(x_0) = \int p_\theta (x_{0:T})dx_{1:T}
Pθ(x0)=∫pθ(x0:T)dx1:T
表示对联合分布
p
θ
(
x
0
:
T
)
p_\theta (x_{0:T})
pθ(x0:T)中所有中间变量
x
1
,
x
2
,
.
.
.
,
x
T
x_1, x_2,..., x_T
x1,x2,...,xT的积分,这样可以消除中间步骤的影响,仅保留
x
0
x_0
x0的分布。这里看不懂没关系,因为联合分布
p
θ
(
x
0
:
T
)
p_\theta (x_{0:T})
pθ(x0:T)其实就是:
p
θ
(
x
0
:
T
)
=
p
(
x
T
)
∗
p
θ
(
x
T
−
1
∣
x
T
)
∗
p
θ
(
x
T
−
2
∣
x
T
−
1
)
∗
⋯
∗
p
θ
(
x
1
∣
x
0
)
p_\theta (x_{0:T}) = p(x_T) * p_\theta (x_{T-1} | x_T) * p_\theta (x_{T-2} | x_{T-1})* \cdots * p_\theta (x_{1} | x_{0})
pθ(x0:T)=p(xT)∗pθ(xT−1∣xT)∗pθ(xT−2∣xT−1)∗⋯∗pθ(x1∣x0)
这里的每一项
p
θ
(
x
T
−
1
∣
x
T
)
p_\theta (x_{T-1} | x_T)
pθ(xT−1∣xT)都是高斯分布。上面这个联合分布的第一项
p
(
x
T
)
p(x_T)
p(xT)就是纯高斯噪声,后面的每一项都是网络提供的高斯分布。如下图所示:

其中第一幅噪声也就是第一项 p ( x T ) p(x_T) p(xT),第一个蓝色的Network提供了 p θ ( x T − 1 ∣ x T ) p_\theta (x_{T-1} | x_T) pθ(xT−1∣xT),第二幅图也就是 p ( x T ) ∗ p θ ( x T − 1 ∣ x T ) p(x_T) * p_\theta (x_{T-1} | x_T) p(xT)∗pθ(xT−1∣xT),后面每一个Network提供一个条件概率分布,最后都乘到一起也就是 p θ ( x 0 : T ) p_\theta (x_{0:T}) pθ(x0:T)。
∫ d x 1 : T \int dx_{1:T} ∫dx1:T表示对中间变量 x 1 , x 2 , . . . , x T x_1,x_2,...,x_T x1,x2,...,xT 的所有可能取值积分,也就消除了中间变量影响,只得到了关于 x 0 x_0 x0的概率 P θ ( x 0 ) P_\theta(x_0) Pθ(x0)。
那我们现在就知道了,如果要跑通反向生成过程,要知道每一个 p θ ( x T − 1 ∣ x T ) , p θ ( x T − 2 ∣ x T − 1 ) , . . . , p θ ( x 1 ∣ x 0 ) p_\theta (x_{T-1} | x_T), p_\theta (x_{T-2} | x_{T-1}),...,p_\theta (x_{1} | x_{0}) pθ(xT−1∣xT),pθ(xT−2∣xT−1),...,pθ(x1∣x0)。
我们现在整理一下,目前有什么已知量可以去求 p θ ( x T − 1 ∣ x T ) p_\theta (x_{T-1} | x_T) pθ(xT−1∣xT)呢?回顾发现,从前向生成过程中,我们已经得知了 q ( x T ∣ x T − 1 ) q (x_{T} | x_{T-1}) q(xT∣xT−1)和 q ( x T ∣ x 0 ) q (x_{T} | x_{0}) q(xT∣x0)的计算公式。也就是说,我们已知 q q q分布的先验概率,想求 p θ p_\theta pθ的后验概率。这跨度有点大,不过我们能不能先去求一个 q q q分布的后验概率 q ( x T − 1 ∣ x T ) q (x_{T-1} | x_{T}) q(xT−1∣xT)呢?
先验概率(根据以往经验和分析得到的概率): q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1),给定前一时刻的 x t − 1 x_{t-1} xt−1预测当前时刻 x t x_t xt的概率。
后验概率(指在得到结果的信息后重新修正的之前事件概率): q ( x t − 1 ∣ x t ) q(x_{t-1}|x_{t}) q(xt−1∣xt),给定当前时刻的 x t x_{t} xt预测前一时刻 x t − 1 x_{t-1} xt−1的概率。
求 q ( x t − 1 ∣ x t ) q (x_{t-1} | x_{t}) q(xt−1∣xt)
根据贝叶斯公式
q
(
x
t
−
1
∣
x
t
)
=
q
(
x
t
∣
x
t
−
1
)
q
(
x
t
−
1
)
q
(
x
t
)
q (x_{t-1} | x_{t}) = \frac{q(x_t|x_{t-1})q(x_{t-1})}{q(x_t)}
q(xt−1∣xt)=q(xt)q(xt∣xt−1)q(xt−1)
q
(
x
t
−
1
)
q(x_{t-1})
q(xt−1)和
q
(
x
t
)
q(x_t)
q(xt)是未知的,但是根据前向推导过程,如果在已知
x
0
x_0
x0的情况下,
q
(
x
t
∣
x
0
)
q(x_t|x_0)
q(xt∣x0)和
q
(
x
t
−
1
∣
x
0
)
q(x_{t-1}|x_0)
q(xt−1∣x0)已知。也就是说,如果知道
x
0
x_0
x0,那就都已知了,即
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
q
(
x
t
∣
x
t
−
1
,
x
0
)
q
(
x
t
−
1
∣
x
0
)
q
(
x
t
∣
x
0
)
q (x_{t-1} | x_{t},x_0) = \frac{q(x_t|x_{t-1}, x_0)q(x_{t-1}|x_0)}{q(x_t|x_0)}
q(xt−1∣xt,x0)=q(xt∣x0)q(xt∣xt−1,x0)q(xt−1∣x0)
这里
q
(
x
t
∣
x
t
−
1
,
x
0
)
,
q
(
x
t
−
1
∣
x
0
)
,
q
(
x
t
∣
x
0
)
{q(x_t|x_{t-1}, x_0),q(x_{t-1}|x_0)},{q(x_t|x_0)}
q(xt∣xt−1,x0),q(xt−1∣x0),q(xt∣x0)都是高斯分布,根据已知的定理(不做推导,感兴趣可以自己了解),
q
(
x
t
−
1
∣
x
t
,
x
0
)
q (x_{t-1} | x_{t},x_0)
q(xt−1∣xt,x0)也是高斯分布。如果将等式的右侧拆开,可以得到高斯分布
q
(
x
t
−
1
∣
x
t
,
x
0
)
q (x_{t-1} | x_{t},x_0)
q(xt−1∣xt,x0)的
σ
\sigma
σ和
μ
\mu
μ的值,具体推导过程比较复杂,这里只展示结果:
σ
t
=
β
t
∗
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
μ
(
x
t
,
x
0
)
=
1
α
t
(
x
t
−
(
1
−
α
t
)
(
1
−
α
ˉ
t
)
ε
t
)
\sigma_t = \beta_t * \frac {1-\bar{\alpha}_{t-1}} {1-\bar{\alpha}_t} \\ \mu(x_t, x_0) = \frac {1}{\sqrt{\alpha_t}} (x_t - \frac {(1-\alpha_t)}{\sqrt{(1-\bar{\alpha}_t)}} \varepsilon_t)
σt=βt∗1−αˉt1−αˉt−1μ(xt,x0)=αt1(xt−(1−αˉt)(1−αt)εt)
公式中的
α
\alpha
α和
β
\beta
β和在前向加噪阶段的一致。那么这样,在已知
x
0
x_0
x0和
x
t
x_t
xt时,我们就求得了
q
(
x
t
−
1
∣
x
t
,
x
0
)
q (x_{t-1} | x_{t},x_0)
q(xt−1∣xt,x0)……吗?
仔细观察上述公式,其实还有一项不知道,那就是 μ ( x t , x 0 ) \mu(x_t, x_0) μ(xt,x0)中的 ε t \varepsilon_t εt。
预测 ε t \varepsilon_t εt
那么 ε t \varepsilon_t εt是什么呢? ε t \varepsilon_t εt其实就是第t步加入的高斯噪声。这个 ε t \varepsilon_t εt是怎么来的呢?是从 x t = α t ‾ ∗ x 0 + 1 − α t ‾ ∗ ε x_{t} = \sqrt{\overline{\alpha _{t}}}*x_{0} + \sqrt{1-\overline{\alpha _{t}}}*\varepsilon xt=αt∗x0+1−αt∗ε这个公式得到的,我们得到 x 0 x_0 x0关于 x t x_t xt和 ε \varepsilon ε表示,然后将这个表示带入,那么 x 0 x_0 x0就消失了,转而代之的是公式中的 ε \varepsilon ε。我们让每一步加的噪声,从 ε 1 \varepsilon_1 ε1到 ε t \varepsilon_t εt都一致,都是 ε \varepsilon ε,那么 ε \varepsilon ε也就等于 ε t \varepsilon_t εt了。那怎么来求这个 ε t \varepsilon_t εt呢?这时候神经网络终于要登场了,我们用神经网络去预测 ε t \varepsilon_t εt。
具体的预测方式就是在训练的过程中,我们可以先将原始图片 x 0 x_0 x0每一步都加同一个噪声 ε \varepsilon ε生成高斯噪声 x t x_t xt,向网络中输入 x t x_t xt和 t t t,让网络预测这个 ε \varepsilon ε,网络会预测出一个 ε p r e d \varepsilon_{pred} εpred,这样将两个高斯噪声 ε \varepsilon ε和 ε p r e d \varepsilon_{pred} εpred做loss,就可以使得网络预测出更合理的 ε p r e d \varepsilon_{pred} εpred。
现在,我们就拥有了一个神经网络,给出 x t x_t xt,它可以预测 ε \varepsilon ε,那根据我们推导的公式,我们就可以求得 q ( x t − 1 ∣ x t , x 0 ) q (x_{t-1} | x_{t},x_0) q(xt−1∣xt,x0)了。
训练与推理中的前向扩散和反向生成
总结一下,那么前向扩散和反向生成过程我们全都可以用高斯分布来表示了:
q
(
x
t
∣
x
t
−
1
)
=
N
(
x
t
;
1
−
β
t
∗
x
t
−
1
,
β
t
I
)
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
N
(
x
t
;
1
α
t
(
x
t
−
(
1
−
α
t
)
(
1
−
α
ˉ
t
)
ε
t
)
,
β
t
∗
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
I
)
q(x_t|x_{t-1}) = N\left ( x_t; \sqrt{1-\beta_t} * x_{t-1}, \beta_t I \right ) \\ q (x_{t-1} | x_{t},x_0) = N \left ( x_t; \frac{1}{\sqrt{\alpha_t}}(x_t- \frac{(1-\alpha_t)}{\sqrt{(1-\bar{\alpha}_t)}}\varepsilon_t), \beta_t * \frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t} I\right )
q(xt∣xt−1)=N(xt;1−βt∗xt−1,βtI)q(xt−1∣xt,x0)=N(xt;αt1(xt−(1−αˉt)(1−αt)εt),βt∗1−αˉt1−αˉt−1I)
q
(
x
t
−
1
∣
x
t
,
x
0
)
q (x_{t-1} | x_{t},x_0)
q(xt−1∣xt,x0)这个式子看起来复杂,其实就是把之前求得的
μ
\mu
μ和
σ
\sigma
σ带进来了而已。
我们可以用这个图来表示前向扩散和反向生成的过程,其中蓝色箭头代表前向扩散,黄色箭头代表反向生成。中间左边的是 x t − 1 x_{t-1} xt−1,右边的是 x t x_t xt。最下面的噪声代表 ε t \varepsilon_t εt,最上面的噪声代表标准高斯噪声 I I I:
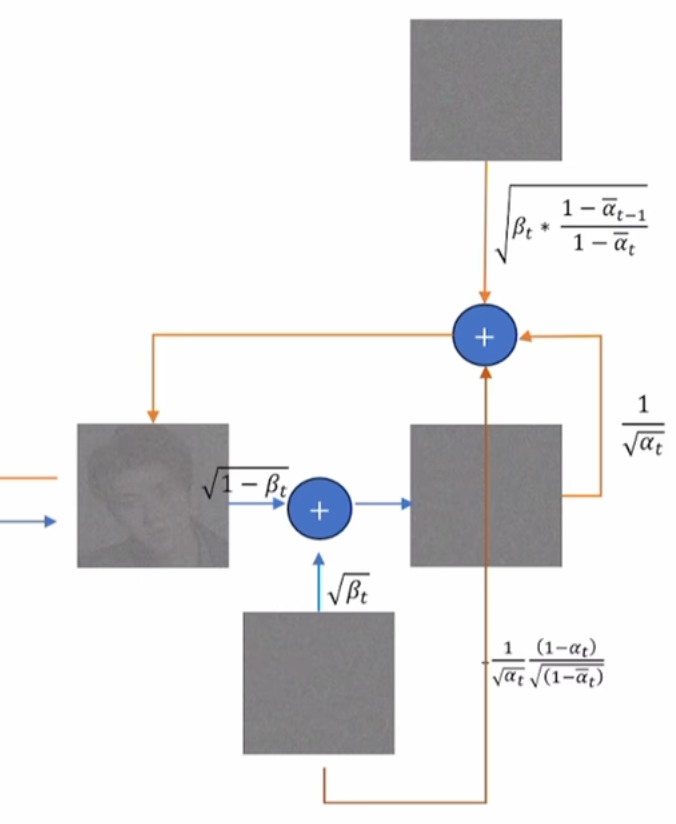
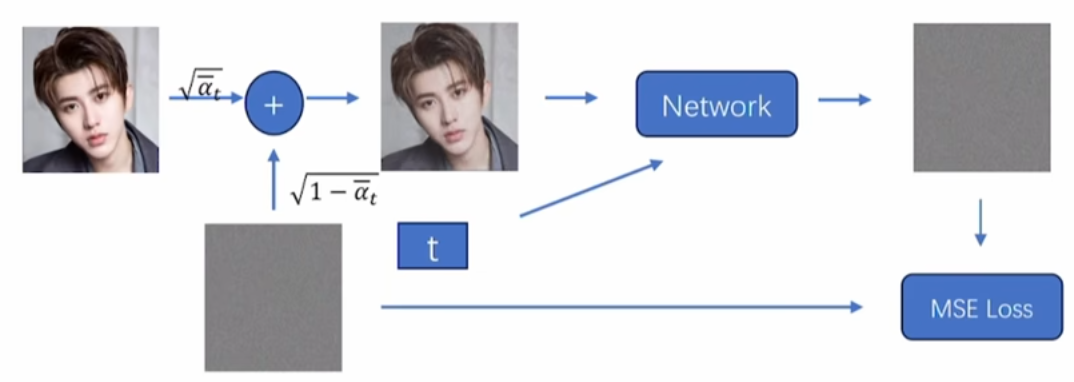
注意上图有一个有可能误导的点,就是在训练中和推理中我们都不会像上图一样,用前向扩散的 ε t \varepsilon_t εt直接进行反向生成。而是:
-
在训练中会像我们之前所说的,在反向生成的时候根据 x t x_t xt和 t t t预测一个 ε p r e d \varepsilon_{pred} εpred(右上角)和前向扩散的 ε t \varepsilon_t εt(左下角)作loss,来训练一个可以预测噪声的noise predictor(也就是图中的Network)。如下图所示:
这里展示一部分训练的代码,帮助大家理解:

可以看到这个Loss就是根据 x t x_t xt和 t t t预测一个 ε p r e d \varepsilon_{pred} εpred
self.model(x_t, t)和前向扩散的 ε t \varepsilon_t εtnoise作loss。 -
在推理中我们使用这个noise predictor,根据 x t x_t xt预测出来 ε p r e d \varepsilon_{pred} εpred,将 ε p r e d \varepsilon_{pred} εpred和 x t x_t xt相结合,得到 x t − 1 x_{t-1} xt−1。公式是 x t − 1 = μ + σ ∗ ε x_{t-1} = \mu + \sigma * \varepsilon xt−1=μ+σ∗ε,带入 μ \mu μ和 σ \sigma σ,也就是:
x t − 1 = 1 α t ( x t − ( 1 − α t ) ( 1 − α ˉ t ) ε p r e d ) + β t ∗ 1 − α ˉ t − 1 1 − α ˉ t ∗ ε x_{t-1} = \frac{1}{\sqrt{\alpha_t}}(x_t- \frac{(1-\alpha_t)}{\sqrt{(1-\bar{\alpha}_t)}}\varepsilon_{pred}) + \beta_t * \frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t} * \varepsilon xt−1=αt1(xt−(1−αˉt)(1−αt)εpred)+βt∗1−αˉt1−αˉt−1∗ε关于DDPM的采样:请注意,这里除了我们预测出来的 ε p r e d \varepsilon_{pred} εpred以外,为了保证 x t − 1 x_{t-1} xt−1是一个高斯分布,我们在后面还需要加上一个高斯噪声 ε \varepsilon ε(这么做的原因在重参数化采样一节有讲)。当我们在讲”DDPM采样一千次“的时候,采样指的就是引入随机噪声 ε \varepsilon ε的过程,因为我们是从标准高斯分布中采集了这个样本 ε \varepsilon ε,然后加到这个式子里的。
如下图所示,图中的 ε θ ( x t , t ) \varepsilon_{\theta}(x_t, t) εθ(xt,t)代表的含义就是模型根据 x t x_t xt和 t t t预测出来的噪声,和我们之前说的 ε p r e d \varepsilon_{pred} εpred是一样的:
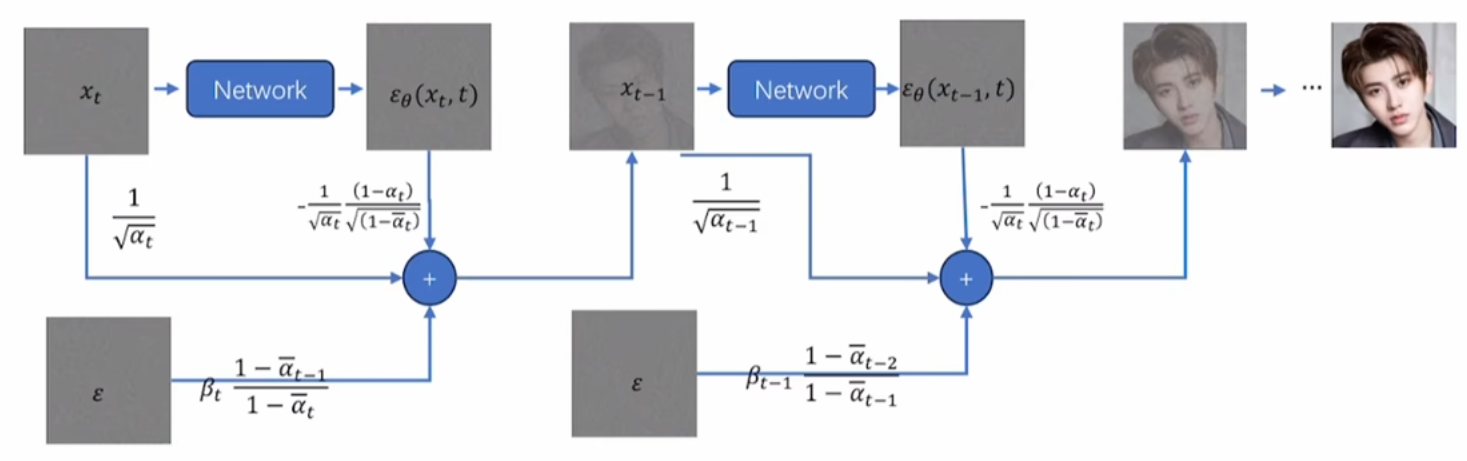
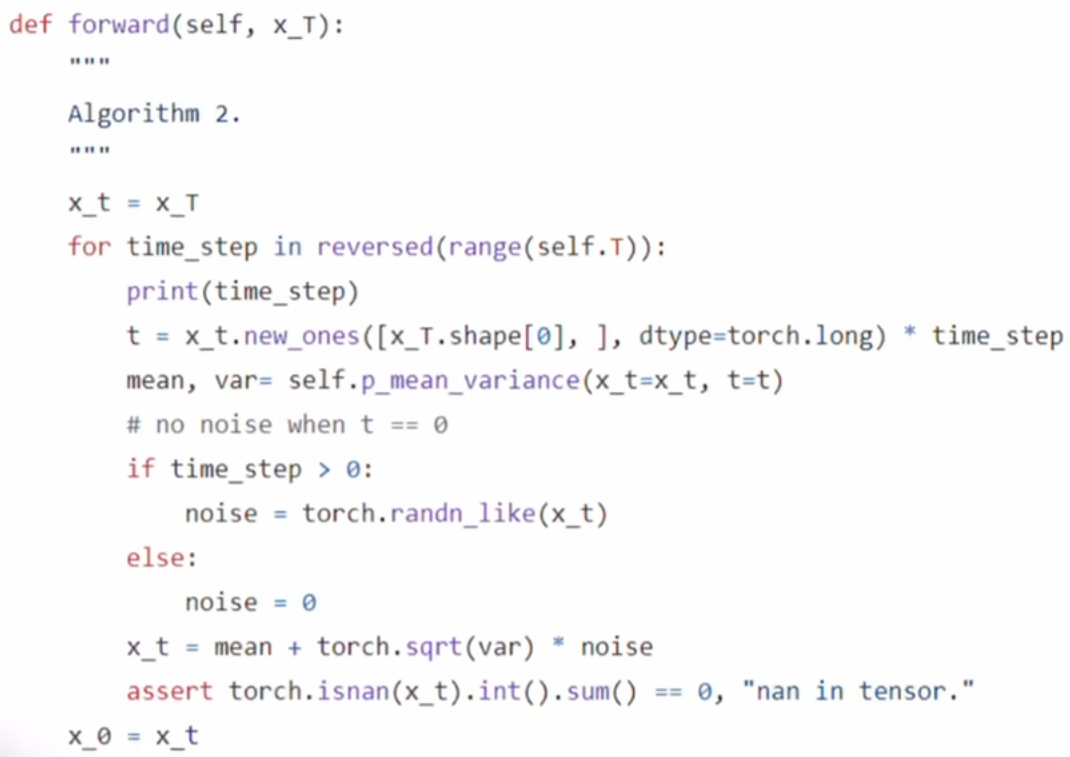
这里同样附上一段代码以帮助理解:
Loss
有读者到这里可能会好奇:“之前讲生成模型的时候,不是说优化目标是 θ \theta θ嘛?还讲了极大似然估计。那为什么现在说预测一个和 ε t \varepsilon_t εt相似的 ε p r e d \varepsilon_{pred} εpred就可以了,那极大似然估计在其中的作用是什么呢?”
这个问题实际上非常好,如果你问出来了这个问题,说明你已经在以生成模型的视角来看待扩散模型了,而这也是本文的目的——帮助大家建立起从生成模型到扩散模型的知识体系。
其实预测一个和 ε t \varepsilon_t εt相似的 ε p r e d \varepsilon_{pred} εpred,就是使得极大似然估计的最小值 E q ( z ∣ x ) [ ∫ l o g ( P θ ( x , z ) q ( z ∣ x ) ) ] E_{q(z|x)}\left [ \int log\left ( \frac{P_\theta(x,z)}{q(z|x)} \right ) \right ] Eq(z∣x)[∫log(q(z∣x)Pθ(x,z))]最大化的过程。这两个过程经过复杂的数学推导之后,可以发现是等价的。这里数学推导就不详细展开了,我讲一下大致的流程,具体大家可以自行搜索学习。
大致的过程就是让Loss等于 − E q ( z ∣ x ) [ ∫ l o g ( P θ ( x , z ) q ( z ∣ x ) ) ] -E_{q(z|x)}\left [ \int log\left ( \frac{P_\theta(x,z)}{q(z|x)} \right ) \right ] −Eq(z∣x)[∫log(q(z∣x)Pθ(x,z))],然后目标是最小化负对数似然。展开之后发现一些项可以舍去,最后Loss只剩下 q ( x t − 1 ∣ x t , x 0 ) q (x_{t-1} | x_{t},x_0) q(xt−1∣xt,x0)和 P θ ( x t ∣ x t − 1 ) P_{\theta}(x_t|x_{t-1}) Pθ(xt∣xt−1)的KL散度(KL散度是一个描述两个分布之间差异的方法),再将这一项展开整理之后,发现当 ε t \varepsilon_t εt和 ε θ ( x t , t ) \varepsilon_{\theta}(x_t, t) εθ(xt,t)越相近,Loss越小。而这个 ε θ ( x t , t ) \varepsilon_{\theta}(x_t, t) εθ(xt,t)其实就是我们知道 x t x_t xt和 t t t的时候预测的高斯噪声。
马尔可夫链
最后讲一下马尔可夫链的概念。
对于前向加噪过程 x t = 1 − β t ∗ x t − 1 + β t ∗ ε t − 1 x_{t} = \sqrt{1-\beta_{t}}*x_{t-1} + \sqrt{\beta_{t}}*\varepsilon _{t-1} xt=1−βt∗xt−1+βt∗εt−1,我们可以称它是一个马尔可夫链。这是因为每一步的噪声添加仅依赖于当前状态,而非更早的历史状态。也就是说每一步的噪声添加仅依赖 x t − 1 x_{t−1} xt−1,与更早的状态 x t − 2 , . . . , x 0 x_{t−2},...,x_0 xt−2,...,x0无关,因此前向过程是马尔可夫链。当然反向过程也是同样的,每一步噪声消除也都仅依赖上一步,所以反向过程也是马尔可夫链。
用数学语言来表示就是:若随机过程满足 p ( x t ∣ x t − 1 , x t − 2 , . . . , x 0 ) = p ( x t ∣ x t − 1 ) p(x_t∣x_{t−1},x_{t−2},...,x_0)=p(x_t∣x_{t−1}) p(xt∣xt−1,xt−2,...,x0)=p(xt∣xt−1),则称其具有马尔可夫性,即未来状态仅依赖于当前状态。
DDPM将扩散过程建模成一个马尔可夫链有其好处和坏处:
-
好处1:马尔可夫链”当前状态仅依赖前一状态“的性质,允许将多步的联合概率分布分解为单步转移概率的乘积,也就是我们之前从 x 0 x_0 x0直接推导 x t x_t xt时的:
q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(x_{1:T}|x_0) = \prod_{t=1}^{T} q(x_t|x_{t-1}) q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
这样使得我们可以推导出 x t = α t ‾ ∗ x 0 + 1 − α t ‾ ∗ ε x_{t} = \sqrt{\overline{\alpha _{t}}}*x_{0} + \sqrt{1-\overline{\alpha _{t}}}*\varepsilon xt=αt∗x0+1−αt∗ε,即直接可以从 x 0 x_0 x0推导任何时刻的 x t x_t xt,不需要逐步推导。 -
好处2:在反向推理的过程中,Loss可以得到简化。在上一部分讲Loss的时候,最后Loss之所以能被简化成 ε t \varepsilon_t εt和 ε p r e d \varepsilon_{pred} εpred作比较,很多都是源于马尔可夫链的性质。
-
坏处:推理速度慢,必须一步步逐步生成。由于马尔可夫链,在反向过程中,如果想知道 x t − 1 x_{t-1} xt−1,必须要先知道 x t x_t xt,不能跳步。在DDPM中,总时间步T默认为1000,也就是每一次生成都要从高斯噪声反向推理1000次,肯定是比较耗时的。
从扩散模型回看生成模型
至此扩散模型就讲完了,我们再回看此前生成模型的原理图:
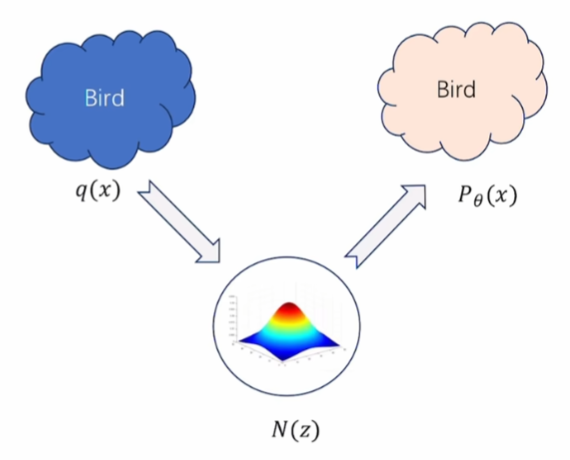
之前写到
我们可以先将训练数据分布 q ( x ) q(x) q(x)(左侧蓝色的Bird图像)转化成一个简单分布 N ( z ) N(z) N(z),在这个简单分布上采样,然后将采样结果转化成与训练数据类似的数据分布 P θ ( x ) P_{\theta}(x) Pθ(x)(右侧粉色的Bird图像)。
那对于扩散模型而言,这个过程具体是怎么样的呢?
- 在训练过程中,我们将训练数据分布中的数据不断加噪变为高斯分布,并在这个过程中学习加噪的规律。
- 在推理过程中,我们最开始在高斯分布上采样作为 x t x_t xt,并且在反向降噪的过程中,每一步都在从高斯分布中采样 ε \varepsilon ε加到公式最后,保证新的 x t − 1 x_{t-1} xt−1满足高斯分布。不断改变样本 x t x_t xt,使其在反向降噪过程中逐渐符合 q ( x ) q(x) q(x)分布,最后它会符合 P θ ( x ) P_{\theta}(x) Pθ(x)分布,而 P θ ( x ) P_{\theta}(x) Pθ(x)一定是和 q ( x ) q(x) q(x)近似的。
- 那这个 P θ ( x ) P_{\theta}(x) Pθ(x)为什么一定会和 q ( x ) q(x) q(x)近似呢?这就是由于我们在训练过程中学习的 ε p r e d \varepsilon_{pred} εpred了,我们在训练的时候,已经学习到了 q ( x ) q(x) q(x)分布下,什么样的 x t x_t xt对应什么样的 ε t \varepsilon_{t} εt,所以可以在推理中根据 x t x_t xt推理出合适的 ε t \varepsilon_{t} εt,使其反向靠近 q ( x ) q(x) q(x)分布。当然我们不可能直接靠近到 q ( x ) q(x) q(x)本身,但是我们可以靠近到一个近似的分布 P θ ( x ) P_{\theta}(x) Pθ(x)。
当然之前还提到了
那么生成模型的动机其实就是:
- 训练一个模型,将训练数据分布 q ( x ) q(x) q(x)映射到简单分布 N ( z ) N(z) N(z),也就是Encoder
- 训练一个模型,将简单分布 N ( z ) N(z) N(z)映射到数据分布 P θ ( x ) P_{\theta}(x) Pθ(x),也就是Decoder
我们发现扩散模型其实并没有一个具体的Encoder和Decoder,是因为它的两个映射过程并不是通过某个模块实现的,而是:前向加噪过程是Encode过程,是训练数据分布 q ( x ) q(x) q(x)映射到简单分布 N ( z ) N(z) N(z)的映射过程;反向去噪过程是Decode过程,是将简单分布 N ( z ) N(z) N(z)映射到数据分布 P θ ( x ) P_{\theta}(x) Pθ(x)的过程。
总结
至此,我们就已经完全详解了Diffusion中最经典的模型DDPM,我们可以看到DDPM有很多优点,比如将极大似然估计一个抽象的任务转化成噪声预测这样一个简单任务,使其非常有利于使用深度学习方法来解决这个问题。但是我们同样还要看到DDPM的缺点:
- DDPM的生成过程不是一步到位的,而是需要多步迭代,使其非常耗时。
- DDPM的输入和输出尺寸是一致的,大尺度的Tensor使其耗费显存,并且增长计算时间。
- DDPM缺少条件控制,生成过程随机,难以得到我们想要的结果。
针对这些问题,在DDPM提出之后都有新的方法来解决:
- DDIM(Denoising Diffusion Implicit Model)采用了跨步采样的方式,降低了迭代的次数,提升了速度。
- LDM(Latent Diffusion Models)或者又称SD(Stable Diffusion)通过结合VQ-VAE,先用一个encoder将数据降维,然后在低维数据上进行diffuison,之后使用一个decoder将低维数据还原到原先维度,降低了显存消耗和耗时。
- ControlNet 在diffusion的过程中加入控制变量(文本或图像),使得扩散过程可以被条件控制,生成我们想要的结果(比如对照片进行动画风格转换)。
由于这些工作切实帮助了扩散模型更好的应用,它们也获得了很高的成就。截止本文撰写,提出DDPM的论文《Denoising Diffusion Probabilistic Models》已经达到了2w的引用量,提出DDIM的论文《Denoising Diffusion Implicit Models》引用量也达到了7k+。此外,基于LDM的Stable Diffusion作为首个开源的文本到图像模型,直接推动了2023年至今的AIGC浪潮。而ControlNet则获得了ICCV 2023的最佳论文奖,也就是我们熟知的马尔奖。
如想继续学习扩散模型相关算法,可阅读本系列其他文章:
- 基于DDPM知识讲解DDIM —— 《大白话 | 快速理解扩散模型【DDIM】Denoising Diffusion Implicit Model》

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









