







对于逻辑回归,模型有两个参数,分别是w和b,前者是向量并表示每个特征的重要性,后者是偏移量(Intercept)。这些参数是需要去估计的。但现在我们唯一能拿到的是观测样本,这就意味着我们需要通过观测样本去估算最好的模型参数。
这个问题也可以这么思考:有个未知的模型类似黑盒子,它产生了很多能看得见的样本。那这时候,我们其实可以通过最大化看到这些样本的概率来反推出模型最优的参数,这种方法叫做最大似然估计。
最大似然估计是机器学习领域最为常见的用来构建目标函数的方法,它的核心思想是根据观测到的结果来预测其中的未知参数.
下面以一个例子来深入了解一下什么叫最大似然:
假设有一枚硬币,它是不均匀的,也就是说出现正面和反面的概率是不同的,假设我们设定这枚硬币出现正面的概率为θ,我们用H来指正面,用T来标记反面,假设我们投掷6次后得到了以下的结果,而且我们假定每次投掷都是相互独立的事件,则θ值为多少?
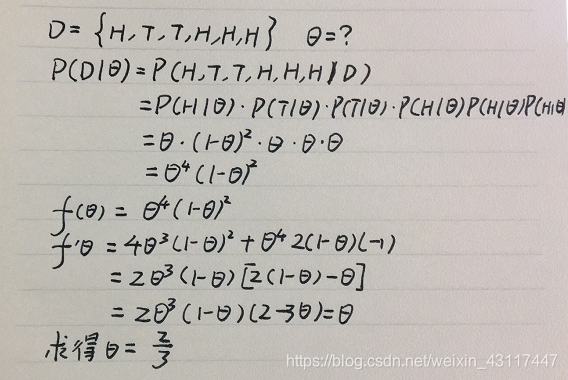
对于逻辑回归模型如何构造最大似然?

对于最大似然,无非就是把所有的样本全部考虑进来。这里需要注意的一点是,这个总概率是由每一个条件概率的乘积来表示的。 随后,通过最大化这个条件概率来得出最优的参数w和b。
有了目标函数之后,我们的任务就比较明确了,就是需要寻找让目标函数最大化的参数w和b。 所以,接下来的问题就变成了一个经典的优化问题。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3157
3157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









