







需求:当前库里面的人物画像表(暂称表1)有不少空值,现在外部采购了一批数据(暂称表2),要求使用这批数据对库表进行映射填充;
现状:库内表的建设初期就是从该外部机构购买的,后期本公司又新增了一些人物,外部机构也新增了一些人物,库内表的大致情况如下:

采购数据表如下:

我们发现有很多特征列都出现了空值,这时候可以用外部采购数据进行填充,充分探索和观察了库内数据的基本面貌之后制定了如下四种填充方式:
- 性别,出生地填充规则:空值填充
- 语言技能,获得证书:空值填充,非空值则判断是否已存在,若不存在则追加,使用"|"符号隔开
- 姓名,别名:只有一种情况需要填充:如果表1姓名与表2姓名相等且表2别名不为空,然后判断表1别名是否为空,若为空,则表2别名填充表1别名,若不为空且表2别名不属于表1别名子集,则表1别名等于表1别名+"|"+表2别名,其他情况都不处理
- 主要爱好,其他爱好:表1主要爱好为空,则表1主要爱好=表2,非空,则判断两表主要爱好是否一致,若是,以表1为准,若不是,则判断表1其他爱好是否为空,若为空,则表2主要爱好填入,若非空,判断表2主要爱好是否为表1其他爱好子集,若是,则pass,若否,则追加
功能实现代码
import numpy as np
import pandas as pd
import os
os.listdir()
['.ipynb_checkpoints', 'Untitled.ipynb', '人物画像_库.xlsx', '人物画像_采购.xlsx']
ku_rw = pd.read_excel("./人物画像_库.xlsx")
cg_rw = pd.read_excel("./人物画像_采购.xlsx")
比较数据类型
如果数据类不一致后续处理会比较麻烦
# 设计函数比较两个列表各字段的数据类型及空值数量
def data_dtypes(df1,df2):
df1_dty = df1.dtypes
df2_dty = df2.dtypes
dict_df1_dty = {"表1":df1_dty.index,"表1数据字段类型":df1_dty.values}
dict_df2_dty = {"表2":df2_dty.index,"表2数据字段类型":df2_dty.values}
df_df1 = pd.DataFrame(dict_df1_dty)
df_df2 = pd.DataFrame(dict_df2_dty)
df_bijiao = pd.concat([df_df1,df_df2],axis=1)
# 插入空值列
df_bijiao.insert(2,"表1空值数(%s)" % len(df1),df1.isnull().sum().values)
df_bijiao.insert(5,"表2空值数(%s)" % len(df2),df2.isnull().sum().values)
return df_bijiao
data_dtypes(ku_rw,cg_rw)
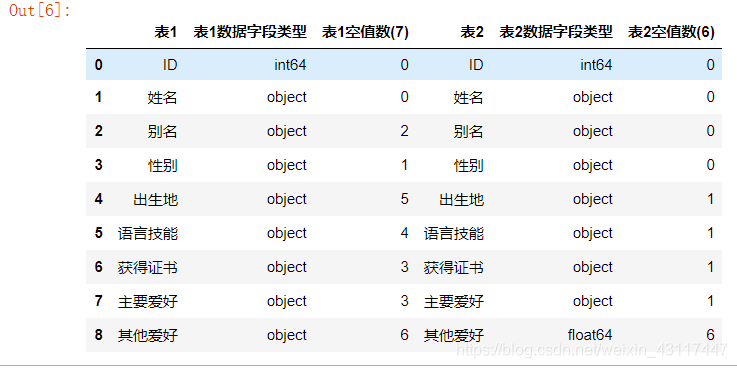
发现数据类型都一致,不需要做类型转换
考虑到只有ID对的上的数据才能做映射填充,所以我们需要将两张表内连接
zongbiao = pd.merge(left=ku_rw,right=cg_rw,on="ID",how="inner")
zongbiao
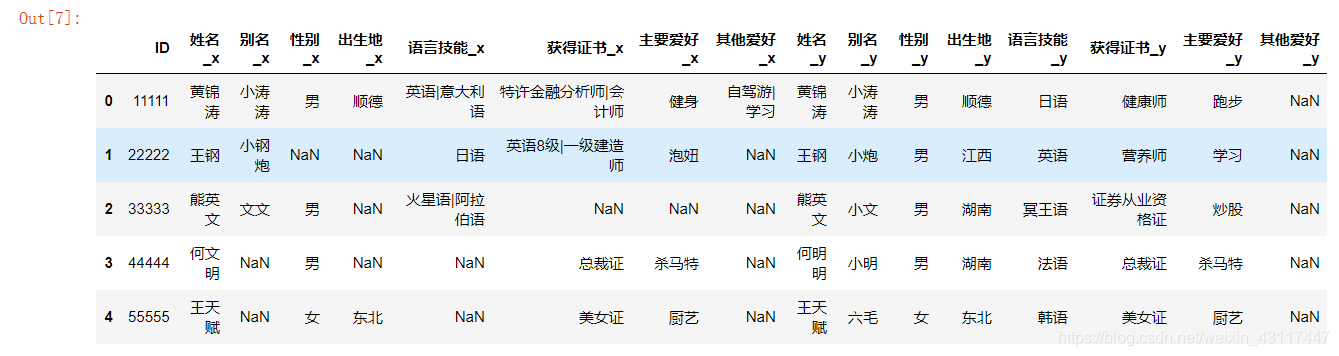
# 去除总表所有的空格,空字符
zongbiao.replace(to_replace=r'^\s*$',value=np.nan,regex=True,inplace=True)
# 空值填充函数
def kongzhi_tc(x,y):
if x is np.nan:
x = y
else:
pass
return x
# 定义追加函数
def zhuijia(a,b):
if a is np.nan:
a = b
elif b is not np.nan and b not in a:
a = a + "|" + b
else:
pass
return a
# 定义别名填充函数
def bieming_tc(name_k,alias_name_k,name_sl,alias_name_sl):
if name_k == name_sl and alias_name_sl is not np.nan:
if alias_name_k is np.nan:
alias_name_k = alias_name_sl
elif alias_name_sl not in alias_name_k:
alias_name_k = alias_name_k + "|" + alias_name_sl
else:
pass
else:
pass
return alias_name_k
# 定义主要爱好,其他爱好填充函数:
def aihao_tc(aihao_ku,alias_aihao_ku,aihao_cg):
if aihao_ku is np.nan:
aihao_ku = aihao_cg
elif aihao_cg is not np.nan and aihao_cg not in aihao_ku:
if alias_aihao_ku is np.nan:
alias_aihao_ku = aihao_cg
elif aihao_cg not in alias_aihao_ku:
alias_aihao_ku = alias_aihao_ku + "|" + aihao_cg
else:
pass
else:
pass
return aihao_ku,alias_aihao_ku
list_to_add_kong = ["性别","出生地"]
for i in list_to_add_kong:
zongbiao[i + "_x"] = zongbiao[[i + "_x",i + "_y"]].apply(lambda x:kongzhi_tc(x[0],x[1]),axis=1)
zhuijia_list = ["语言技能","获得证书"]
for i in zhuijia_list:
zongbiao[i + "_x"] = zongbiao[[i + "_x",i + "_y"]].apply(lambda x:zhuijia(x[0],x[1]),axis=1)
# 别名填充
zongbiao["别名_x"] = zongbiao[["姓名_x","别名_x","姓名_y","别名_y"]].apply(lambda x:bieming_tc(x[0],x[1],x[2],x[3]),axis=1)
# 主要爱好,其他爱好填充
zongbiao[["主要爱好_x","其他爱好_x"]] = zongbiao[["主要爱好_x","其他爱好_x","主要爱好_y"]].apply(lambda x:aihao_tc(x[0],x[1],x[2]),axis=1).apply(pd.Series)
zongbiao_shuchu = zongbiao.iloc[:,:9]
zongbiao_shuchu
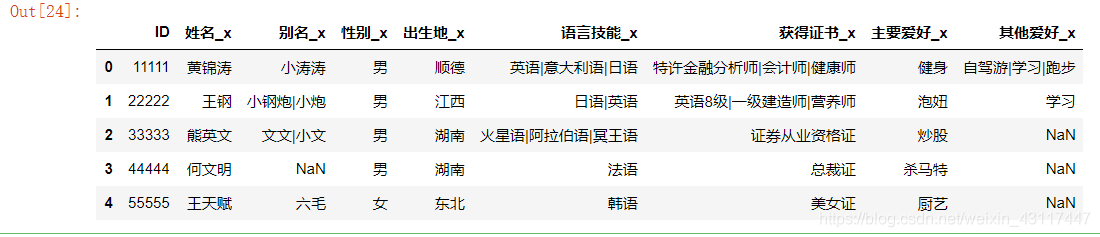
# 给列重命名
zongbiao_shuchu.columns = ku_rw.columns
zongbiao_shuchu
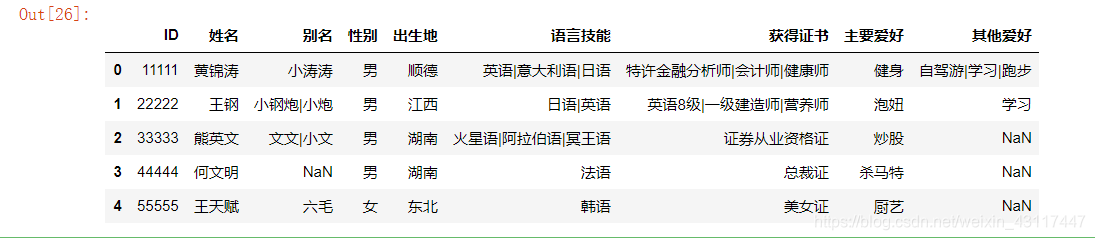
至此,功能已经全部实现

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









