







一:list的定义
用[],定义,数据之间用,分隔,索引从0开始,又叫下标 -index,为可变数据类型,可以存储任何数据类型,但是使用中,一般都是放相同数据类型。
用下标从列表中取值时,超出索引范围,会报错。
二;列表常用操作
定义一个列表为a = [1, 2, 3]
1-- 增
a.insert(index, 数据) ,在指定索引位置,插入数据 ,插入的数据的数据类型是str的话要加上'' "
a.append(数据), 在列表的末尾追加数据 ,最常用,必须记住
a.extend(列表2) 将列表2中的数据追加到列表a中(追加在尾部)
2-- 删
del a[index] --删除指定索引的数据
eg:删除a列表中的最后一个数据 del [len(a) - 1] 意思是;先找出列表a的长度, 减1 就为最后一个元素的索引,然后就能删除了
a.pop 删除列表末尾的数据
a.remove(数据) 删除第一个出现的指定数据, 为什么是第二个?,因为列表的元素是可以重复的。,最常用
a.clear 清空整个列表
3-- 改
找到对应数据的index ,列表.index(要找下标的数据) -- index = a.index(1)
a[index] = 数据 修改指定索引的数据, 这种可以看成是赋值。
4-- 统计
len(a) 统计列表长度, 减去1就是最后一个元素的index
a.count(数据) 统计数据在列表中出现的次数
5-- 比较
max(a) 返回列表a中元素的最大值
min(a) 返回列表a 中元素的最小值
list(元祖) 把元祖转换成列表
6-- 排序
a.sort() 默认升序排序,从小到大
a.sort(reverse=True) 降序排序
7:列表反转
a.reverse() 列表反转,不是倒序排序!!!
还可以通过切片的方式来是列表反转, 反转是反转,排序和倒序排序是排序,两者不一样的,不要搞反了
a1 = a[::-1] 字符串的倒序取值也是同样操作。
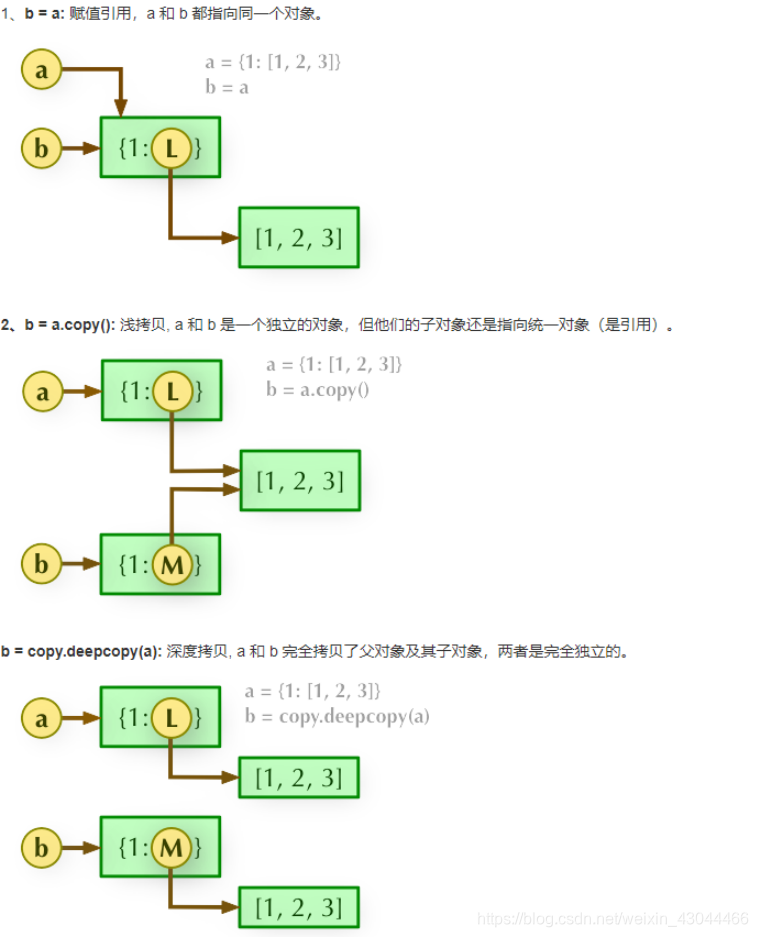
8-- 深拷贝和浅拷贝
简单的理解,浅拷贝就是赋值,b = a, 把a 赋值给b,只拷贝父对象,不会拷贝对象内部的子对象,内存id都是一样的。 但是后续如果对a进行操作,增删改,都会影响到b
深拷贝,如果要进行深拷贝,首先要引入自带的copy模块,深拷贝完全copy了父对象和子对象,虽然值是一样的,但是内存id是不一样的,所以修改任意一个值,两者之间都不会相互影响。
列表的切片,以及copy属于浅拷贝,相当于新开辟一个内存空间,里面存放的是可变类型变量的引用,深拷贝里面存放的是具体的数据,
9 ,列表去重,常见的列表去重的方法。
list_1 = [10, 1, 2, 20, 10, 3, 2, 1, 15, 20, 44, 56, 3, 2, 1]1-- 使用set(列表), 去重后,在赋值给新的列表,新的列表就是去重后的列表了
def func(list_1):
return list(set(list_1))
print("去重后的列表为: {}".format(func(list_1)))
2-- 遍历列表,如果i不在新列表中,则添加到新列表中,得到的新列表就是去重后的列表
def func2(list):
my_list = []
for i in list:
if i not in my_list:
my_list.append(i)
return my_list
print(func2(list_2))
3--
其实这个本质上跟for循环是一样的,只不过是换成了while循环,通过判断下标小于列表的长度,
如果不满足的时候在退出循环,就可以把列表中的值全部遍历出来,然后通过下标判断存不存在新的列表中,不存在添加,存在的话
则计数器加一在进入循环,直到计数器 i 大于列表的长度,则退出循环,返回新的列表,排序只是为了好看
list_3 = [10, 1, 2, 20, 10, 3, 2, 1, 15, 20, 44, 56, 3, 2, 1]
def func3(list):
result_list = []
newlist = sorted(list)
i = 0
while i < len(newlist):
if newlist[i] not in result_list:
result_list.append(newlist[i])
else:
i+=1
return result_list
print(func3(list_3))注意事项:!!!
最好不要在循环过程中修改列表。因为列表是会变的。必须要修改列表的时候,可以定义一个新的列表去接受数据
a = [1, 2, 3, 4]
for i in a:
# 因为遍历的时候是通过列表的下标取值的,所以当遍历到索引0的时候,删除了元素1,此时列表变成了[2,3,4],再次遍历的是取索引1的值,即3
# 此时列表变为[2,4],再遍历的时候到了下标3,但是列表已经没有了。所以结束循环,输出为[2,4]
a.remove(i)
print(a)
要特别小心面试的时候遇到这种坑。考察基础
这个也是考察列表是可变的数据类型!
def add_movie(movie, movies=[]):
movies.append(movie)
return movies
# 因为列表是可变的,执行完第一条打印的时候,movies为['权游'],第二条为['权游','老友记'],第三条的时候因为给movies传入了一个空列表,此时重新创建了一个列表,为一个新列表,所以输出为['变形金刚']
# 第五条输出是因为没有用新的列表,还是第一条输出的时候就创建的列表,此时列表为第二条输出的内容:为['权游','老友记']。 所以第五条的输出为['权游', '老友记', '2012']
print(add_movie("权游"))
print(add_movie("老友记"))
print(add_movie("变形金刚", []))
print(add_movie("2012"))
输出结果为:['权游']
['权游', '老友记']
['变形金刚']
['权游', '老友记', '2012']
第一个打印和第二个打印都使用的是默认参数列表,所以内存地址没有发生变化,每次增加的值都是在原先的基础上添加值,第二个打印重新传入了一个空列表,此时创建了一个新的列表,内存地址发生了变化,因此它们不是一个列表
三; 元祖
1-- 用()表示,用,隔开
2-- 可通过下标取值
3-- 不要放劣列表,字典等可变的数据类型
4-- 元祖中只有一个数据时; (数据,)
5-- 元祖为不可变数据类型
后续有新坑,会持续修改~谢谢

















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









