







论文地址:https://arxiv.org/abs/2310.08528
源码地址:https://github.com/hustvl/4DGaussians
项目地址:https://guanjunwu.github.io/4dgs/
摘要
表示和渲染动态场景一直是一个重要但具有挑战性的任务。尤其是要准确模拟复杂运动时,通常很难保证高效率。为了在享受高训练和存储效率的同时实现实时动态场景渲染,我们提出了4D Gaussian Splatting(4D-GS),作为动态场景的整体表示,而不是对每一帧单独应用3D-GS。在4D-GS中,提出了一种新颖的显式表示,包含3D高斯和4D神经体素。提出了一种受HexPlane启发的分解神经体素编码算法,用于从4D神经体素中高效构建高斯特征,然后应用轻量级MLP预测新时间戳的高斯变形。我们的4D-GS方法在高分辨率下实现了实时渲染,在RTX 3090 GPU上800×800分辨率下达到82 FPS,同时保持与以前最先进方法相当或更好的质量。更多的演示和代码可在https://guanjunwu.github.io/4dgs/上获得。
1.介绍
新视角合成(NVS)是3D视觉领域中的一个关键任务,在许多应用中发挥着至关重要的作用,例如虚拟现实(VR)、增强现实(AR)和电影制作。NVS的目标是从场景的任意期望视点或时间戳渲染图像,通常需要从几个2D图像准确建模场景。动态场景在真实场景中非常常见,渲染它们很重要,但也很具挑战性,因为需要用空间和时间上稀疏的输入来建模复杂运动。
NeRF[22]通过用隐式函数表示场景,在合成新视角图像方面取得了巨大成功。体积渲染技术[5]被引入以连接2D图像和3D场景。然而,原始的NeRF方法在训练和渲染方面都有很高的成本。尽管一些NeRF变体[4, 6–8, 23, 34, 36]将训练时间从几天减少到几分钟,渲染过程仍然有不可忽视的延迟。
最近的3D Gaussian Splatting(3D-GS)[14]通过将场景表示为3D高斯,显著提高了渲染速度,达到了实时水平。原始NeRF中繁琐的体积渲染被高效的可微分splatting[46]取代,该方法直接将3D高斯点投影到2D平面上。3D-GS不仅享有实时渲染速度,而且更明确地表示场景,使得操作场景表示变得更加容易。
然而,3D-GS专注于静态场景。将其扩展到动态场景作为4D表示是一个合理、重要但困难的话题。关键挑战在于从稀疏输入中建模复杂的点运动。3DGS通过用点状高斯表示场景,保持了自然几何先验。一个直接而有效的扩展方法是在每个时间戳[21]构建3D高斯,但存储/内存成本将特别增加,尤其是对于长输入序列。我们的目标是构建一个紧凑的表示,同时保持训练和渲染效率,即4D Gaussian Splatting(4DGS)。为此,我们提出用一个高效的高斯变形场网络表示高斯运动和形状变化,该网络包含一个时空结构编码器和一个极小的多头高斯变形解码器。只维护一组规范的3D高斯。对于每个时间戳,规范的3D高斯将通过高斯变形场变换到新位置,并呈现新的形状。变换过程代表了高斯运动和变形。**请注意,与分别建模每个高斯的运动[21, 44]不同,时空结构编码器可以将不同的相邻3D高斯连接起来,以预测更准确的运动和形状变形。**然后,变形的3D高斯可以直接splatting以渲染相应时间戳的图像。我们的贡献可以总结如下:
- 提出了一个高效的4D高斯splatting框架,通过建模时间上的高斯运动和高斯形状变化,提出了一个高效的高斯变形场。
- 提出了一种多分辨率编码方法,通过高效的时空结构编码器连接附近的3D高斯,并构建丰富的3D高斯特征。
- 4D-GS在动态场景上实现了实时渲染,在合成数据集上分辨率为800×800时达到82 FPS,在真实数据集中分辨率为1352×1014时达到30 FPS,同时保持与以前最先进的(SOTA)方法相当或更优的性能,并展示了在4D场景中编辑和跟踪的潜力。
2.相关工作
在本节中,我们将简要回顾动态NeRFs在第2.1节中的差异,然后讨论基于点云的神经渲染算法在第2.2节中。
2.1. 动态神经渲染
[3, 22, 48] 展示了隐式辐射场可以有效学习场景表示并合成高质量的新视角图像。[24, 25, 28] 挑战了静态假设,扩展了动态场景新视角合成的边界。此外,[6] 提出了使用显式体素网格来模拟时间信息,将动态场景的学习时间缩短到半小时,并在[12, 20, 45]中应用。所提出的规范映射神经渲染方法如图2(a)所示。[4, 8, 17, 34, 37] 通过采用分解的神经体素表示,进一步推进了更快的动态场景学习。它们将每个时间戳中的采样点单独处理,如图2(b)所示。[11, 18, 27, 38, 40, 42] 是处理多视图设置的有效方法。尽管上述方法实现了快速训练速度,但动态场景的实时渲染仍然具有挑战性,尤其是对于单目输入。我们的方法旨在构建一个高效的训练和渲染流程,如图2©所示,同时保持质量,即使是对于稀疏输入。
2.2. 基于点云的神经渲染
有效表示3D场景仍然是一个挑战性的话题。社区已经探索了各种神经表示[22],例如网格、点云[43]和混合方法。基于点云的方法[19, 29, 30, 47]最初针对3D分割和分类。一个代表性的渲染方法[1, 43]结合了点云表示和体积渲染,实现了快速收敛速度。[15, 16, 31]采用了微分点渲染技术进行场景重建。此外,3D-GS[14]因其纯粹的显式表示和基于微分点的splatting方法而引人注目,实现了新视角的实时渲染。Dynamic3DGS[21]通过在每个时间戳 t i t_i ti跟踪每个3D高斯的位置和方差来模拟动态场景。使用显式表格存储每个时间戳的每个3D高斯的信息,导致线性内存消耗增加,表示为 O ( t N ) O(tN) O(tN),其中 N N N是3D高斯的数量。对于长时间场景重建,存储成本将变得不可忽视。我们的方法的内存复杂性仅取决于3D高斯的数量和高斯变形场网络F的参数,表示为 O ( N + F ) O(N + F) O(N+F)。[44]在原始3D高斯中添加了一个边缘的时态高斯分布,将3D高斯提升到4D。然而,它可能导致每个3D高斯只关注它们自己的局部时间空间。我们的方法还模拟了3D高斯的运动,但使用了一个紧凑的网络,从而实现了高效的训练效率和实时渲染。
3.2. 带有变形场的动态NeRFs
所有动态NeRF算法可以表示为:
c , σ = M ( x , t ) ( 5 ) c, \sigma = M(x, t) \quad(5) c,σ=M(x,t)(5)
其中 M M M 是一个映射,将6D空间 ( x , d , t ) (x, d, t) (x,d,t) 映射到4D空间 ( c , σ ) (c, \sigma) (c,σ)。动态NeRF主要遵循两条路径:规范映射体积渲染[6, 20, 24, 25, 28]和时间感知体积渲染[4, 8, 9, 17, 34]。在本节中,我们主要回顾前者。如图2 (a)所示,规范映射体积渲染通过变形网络 ϕ t : ( x , t ) → ∆ x ϕ_t : (x, t) \to ∆x ϕt:(x,t)→∆x 将每个采样点转换到规范空间。然后引入一个规范网络 ϕ x ϕ_x ϕx 来从每个射线回归体积密度和视角依赖的RGB颜色。渲染的公式可以表示为:
c , σ = NeRF ( x + Δ x ) ( 6 ) c, \sigma = \text{NeRF}(x + \Delta x)\quad(6) c,σ=NeRF(x+Δx)(6)
其中NeRF代表原始的NeRF流程。然而,我们的4D高斯splatting框架展示了一种新颖的渲染技术。我们直接在时间 t t t 使用高斯变形场网络 F F F 变换3D高斯,然后遵循微分splatting [14]。
4. Method
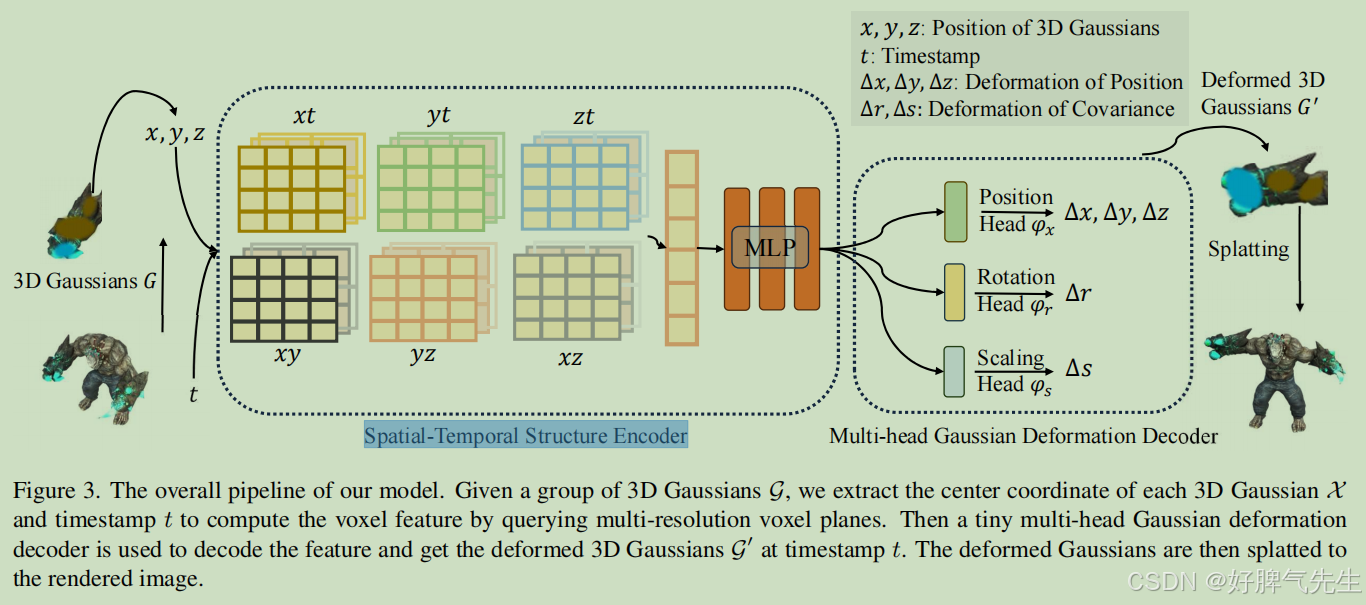
4.1. 4D Gaussian Splatting框架
如图3所示,给定一个视图矩阵 M = [ R , T ] M = [R, T] M=[R,T]和时间戳 t t t,我们的4D Gaussian splatting框架包括3D高斯 G G G和高斯变形场网络 F F F。然后通过微分splatting S S S渲染新视图图像 I ^ \hat{I} I^,遵循 I ^ = S ( M , G ′ ) \hat{I} = S(M, G') I^=S(M,G′),其中 G ′ = Δ G + G G' = \Delta G + G G′=ΔG+G。
具体来说,3D高斯的变形 Δ G \Delta G ΔG是由高斯变形场网络 Δ G = F ( G , t ) \Delta G = F(G, t) ΔG=F(G,t)引入的,其中空间-时间结构编码器 H H H可以编码3D高斯的时空特征 f d = H ( G , t ) f_d = H(G, t) fd=H(G,t),多头高斯变形解码器 D D D可以解码特征并预测每个3D高斯的变形 Δ G = D ( f ) \Delta G = D(f) ΔG=D(f),然后引入变形的3D高斯 G ′ G' G′。
我们的4D Gaussian Splatting的渲染过程如图2 ©所示。我们的4D Gaussian splatting将原始的3D高斯 G G G转换为另一组给定时间戳 t t t的3D高斯 G ′ G' G′,同时保持微分splatting的有效性,如[46]中所述。
4.2 高斯变形场网络
学习高斯变形场的网络包括一个高效的空间-时间结构编码器 H H H和一个用于预测每个3D高斯变形的高斯变形解码器 D D D。
空间-时间结构编码器。时间相近的3D高斯通常共享相似的空间和时间信息。为了有效建模3D高斯的特征,我们引入了一个高效的空间-时间结构编码器 H H H,包括一个多分辨率HexPlane R ( i , j ) R(i, j) R(i,j)和一个受[4, 6, 8, 34]启发的小型MLP ϕ d \phi_d ϕd。虽然原始的4D神经体素是内存密集型的,我们采用了4D K-Planes[12]模块将4D神经体素分解为6个平面。在特定区域内的所有3D高斯可以被包含在边界平面体素中,并且高斯的变形也可以在附近的时间体素中编码。
具体来说,空间-时间结构编码器 H H H包含6个多分辨率平面模块 R l ( i , j ) R_l(i, j) Rl(i,j)和一个小型MLP ϕ d \phi_d ϕd,即 H ( G , t ) = { R l ( i , j ) , ϕ d ∣ ( i , j ) ∈ { ( x , y ) , ( x , z ) , ( y , z ) , ( x , t ) , ( y , t ) , ( z , t ) } , l ∈ { 1 , 2 } } H(G, t) = \{R_l(i, j), \phi_d | (i, j) \in {\{(x, y), (x, z), (y, z), (x, t), (y, t), (z, t)}\}, l \in \{1, 2\}\} H(G,t)={Rl(i,j),ϕd∣(i,j)∈{(x,y),(x,z),(y,z),(x,t),(y,t),(z,t)},l∈{1,2}}。位置 X = ( x , y , z ) X = (x, y, z) X=(x,y,z)是3D高斯 G G G的均值。每个体素模块定义为 R ( i , j ) ∈ R h × l N i × l N j R(i, j) \in \mathbb{R}^{h \times lN_i \times lN_j} R(i,j)∈Rh×lNi×lNj,其中 h h h代表特征的隐藏维度, N N N表示体素网格的基本分辨率, l l l等于上采样比例。这意味着在考虑时间信息的同时,对3D高斯在6个2D体素平面内的信息进行编码。计算单独体素特征的公式如下
f h = ⋃ l ∏ interp ( R l ( i , j ) ) ( i , j ) ∈ ( x , y ) , ( x , z ) , ( y , z ) , ( x , t ) , ( y , t ) , ( z , t ) ( 7 ) f_h = \bigcup_l \prod \text{interp}(R_l(i, j))\\ (i, j) \in {(x, y), (x, z), (y, z), (x, t), (y, t), (z, t)} \quad(7) fh=l⋃∏interp(Rl(i,j))(i,j)∈(x,y),(x,z),(y,z),(x,t),(y,t),(z,t)(7)
其中 f h ∈ R h × l f_h \in R_{h \times l} fh∈Rh×l是神经体素的特征。 interp \text{interp} interp表示用于查询位于网格四个顶点的体素特征的双线性插值。生产过程的讨论类似于[8]。然后一个小型MLP ϕ d \phi_d ϕd通过 f d = ϕ d ( f h ) f_d = \phi_d(f_h) fd=ϕd(fh)合并所有特征。
多头高斯变形解码器。当所有3D高斯的特征被编码后,我们可以使用多头高斯变形解码器 D = { ϕ x , ϕ r , ϕ s } D = \{\phi_x, \phi_r, \phi_s\} D={ϕx,ϕr,ϕs}计算任何所需的变量。采用单独的MLP来计算位置变形 Δ X = ϕ x ( f d ) \Delta X = \phi_x(fd) ΔX=ϕx(fd),旋转 Δ r = ϕ r ( f d ) \Delta r = \phi_r(fd) Δr=ϕr(fd),和缩放 Δ s = ϕ s ( f d ) \Delta s = \phi_s(fd) Δs=ϕs(fd)。然后,变形的特征 ( X ′ , r ′ , s ′ ) (X', r', s') (X′,r′,s′)可以表示为:
( X ′ , r ′ , s ′ ) = ( X + Δ X , r + Δ r , s + Δ s ) ( 8 ) (X', r', s') = (X + \Delta X, r + \Delta r, s + \Delta s) \quad(8) (X′,r′,s′)=(X+ΔX,r+Δr,s+Δs)(8)
最后,我们获得变形的3D高斯 G ′ = { X ′ , s ′ , r ′ , σ , C } G' = \{X', s', r', \sigma, C\} G′={X′,s′,r′,σ,C}。
4.3 优化
3D 高斯初始化。文献[14]表明,3D 高斯可以通过结构从运动(SfM)[32]点初始化进行良好的训练。同样,4D 高斯也应该在适当的 3D 高斯初始化下进行微调。我们在初始的 3000 次迭代中优化 3D 高斯以进行预热,然后使用 3D 高斯 I = S ( M , G ) {I} = S(M, G) I=S(M,G)而不是 4D 高斯渲染图像 I ^ = S ( M , G ′ ) \hat{I} = S(M, G^\prime) I^=S(M,G′)。优化过程的插图如图 4 所示。
损失函数。与其他重建方法[6, 14, 28]类似,我们使用 L1 颜色损失来监督训练过程。还应用了基于网格的总变分损失[4, 6, 8, 36] L t v \mathcal{L} _{tv} Ltv。
L = ∣ I ^ − I ∣ + L t v ( 9 ) \mathcal{L} = |\hat{I} - I| + \mathcal{L} _{tv} \quad (9) L=∣I^−I∣+Ltv(9)
5 实验
在本节中,我们主要介绍设置中的超参数和数据集在第 5.1 节中,不同数据集的结果将在第 5.2 节中与[2, 4, 6, 8, 14, 18, 35, 37, 38]进行比较。然后,在第 5.3 节中提出消融研究,以证明我们方法的有效性。最后,在第 5.4 节中讨论有关 4D-GS 的更多内容。最后,我们在第 5.5 节中讨论了我们提出的 4D-GS 的局限性。
5.4 讨论
多分辨率HexPlane高斯编码器的分析。我们多分辨率HexPlane Rl(i, j)中特征的可视化如图8所示。作为一个显式模块,所有3D高斯特征都可以在各个体素平面中轻松优化。如图8 (b)所示,体素平面甚至显示出与渲染图像相似的形状,例如边缘。同时,时间特征也保留在图8 ©的运动区域中。这种显式表示提高了我们4D高斯的训练和渲染质量速度。
用3D高斯进行跟踪。在3D中进行跟踪也是一个重要的任务。[12]也展示了在3D中跟踪对象的运动。与dynamic3DGS [21]不同,我们的方法甚至可以在单目设置中以相当低的存储空间(即3D高斯G为10MB,高斯变形场网络F为8MB)呈现跟踪对象。图9显示了特定时间戳下3D高斯的变形。
用4D高斯进行合成。类似于dynamic3DGS [21],我们提出的方法也可以在图10中用不同的4D高斯进行合成。由于3D高斯的显式表示,所有训练好的模型都可以预测在同一空间中变形的3D高斯遵循G′ = {G′ 1, G′ 2, …, G′ n},并且微分渲染[46]可以将所有点云通过ˆI = S(M, G′)投影到视点。
渲染速度分析。如图11所示,我们还测试了在800×800分辨率下,渲染屏幕上的点数与渲染速度之间的关系。我们发现,如果渲染点少于30000,渲染速度可以达到90。高斯变形场的配置在附录中讨论。要实现实时渲染速度,我们应该在所有渲染分辨率、4D高斯表示(包括3D高斯的数量)以及高斯变形场网络的容量和其他任何硬件限制之间取得平衡。
5.5 限制
尽管4D-GS确实能在许多场景中实现快速收敛,并在许多场景中实现实时渲染结果,但仍有一些关键挑战需要解决。首先,大的运动、缺少背景点和不精确的相机姿态导致优化4D高斯的困难。更重要的是,4D-GS也不能在没有任何额外监督的单目设置下分割静态和动态高斯部分的联合运动。最后,需要设计一个更紧凑的算法来处理城市规模的重建,因为大量的3D高斯对高斯变形场的大量查询。
6.结论
本文提出了4D Gaussian splatting,以实现实时动态场景渲染。构建了一个高效的变形场网络,以准确模拟高斯运动和形状变形,其中相邻的高斯通过空间-时间结构编码器连接。高斯之间的连接导致了更完整的变形几何结构,有效地避免了撕裂。我们的4D高斯不仅可以建模动态场景,而且还有4D目标跟踪和编辑的潜力。

















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









