



DHD-Occ
https://github.com/yanzq95/DHD
Deep Height Decoupling for Precise Vision-based 3D Occupancy Prediction
- 本文提出了用于占用率预测的深度与高度解耦(deep height decoupling, DHD) 框架,该框架首次通过明确的高度监督将高度先验纳入模型中。
- 本文提出了由高度采样引导的mask模块(mask guided height sampling,MGHS),可以准确地完成特征变换,改善了2D到3D投影的准确性。
- 本文引入了协同特征聚合模块(synergistic feature aggregation,SFA)来增强特征表征,从而提高Occ预测准确率。
Method
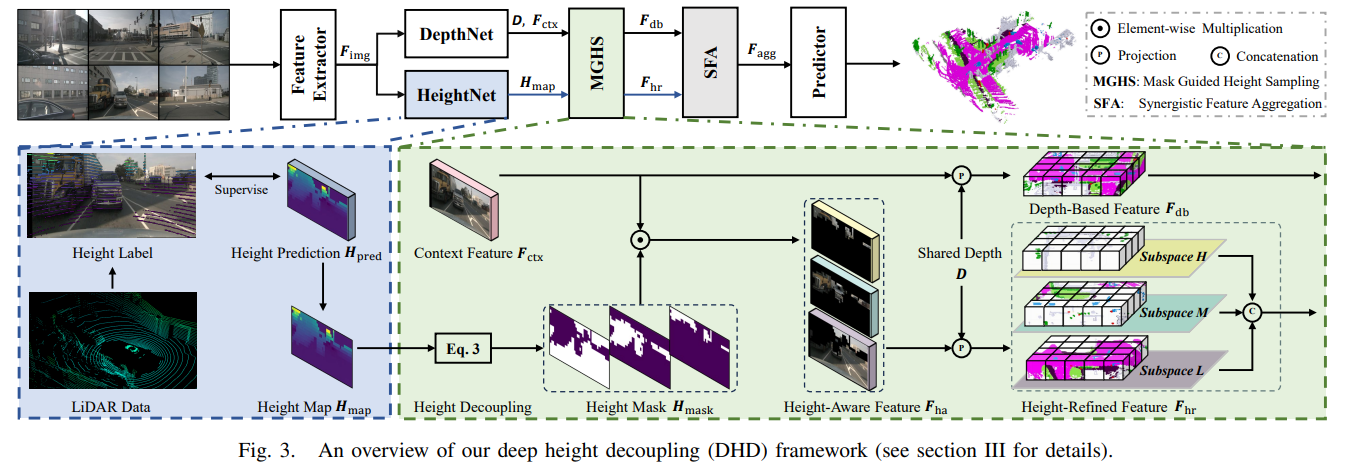
- HeightNet
参考DepthNet, 本文采用one-hot编码的方式将高度信息编码到特征中,利用SE-layer和深度可分离卷积得到高度特征,进而通过argmax得到最终的高度预测结果。并且使用点云数据对高度进行监督。 - Mask Guided Height Sampling
基于对数据集的分析,不同类别的物体在高度上的分布存在显著差异,从几何角度来看,(b) 中的累积分布函数 (CDF) 曲线显示,分布偏离了正态分布或均匀分布,在较低区域观察到高密度: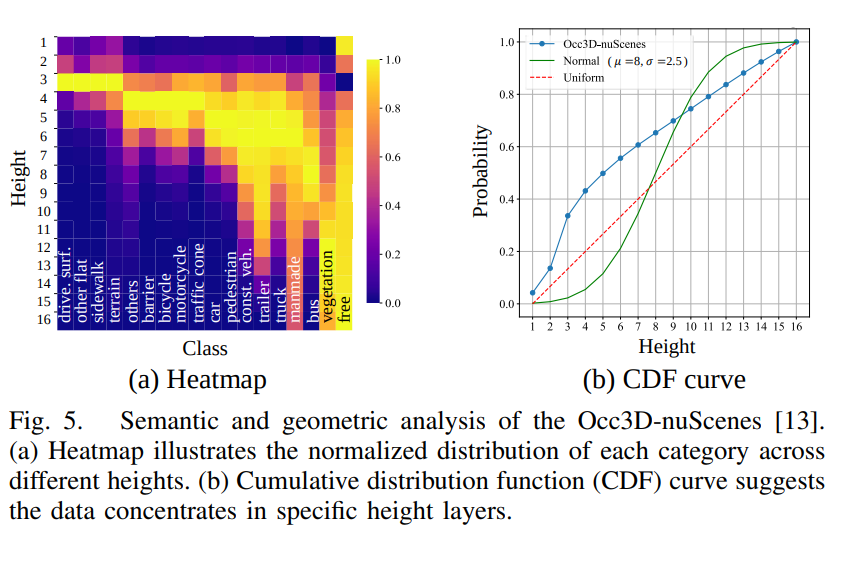
根据上述观察结果,我们首先将高度分解为不同的区间 I = {[1,4],[5,8],[9,16]},然后在高度区间对特征进行分解,得到三个具有不同语义信息的子空间(L、M 和 H)。
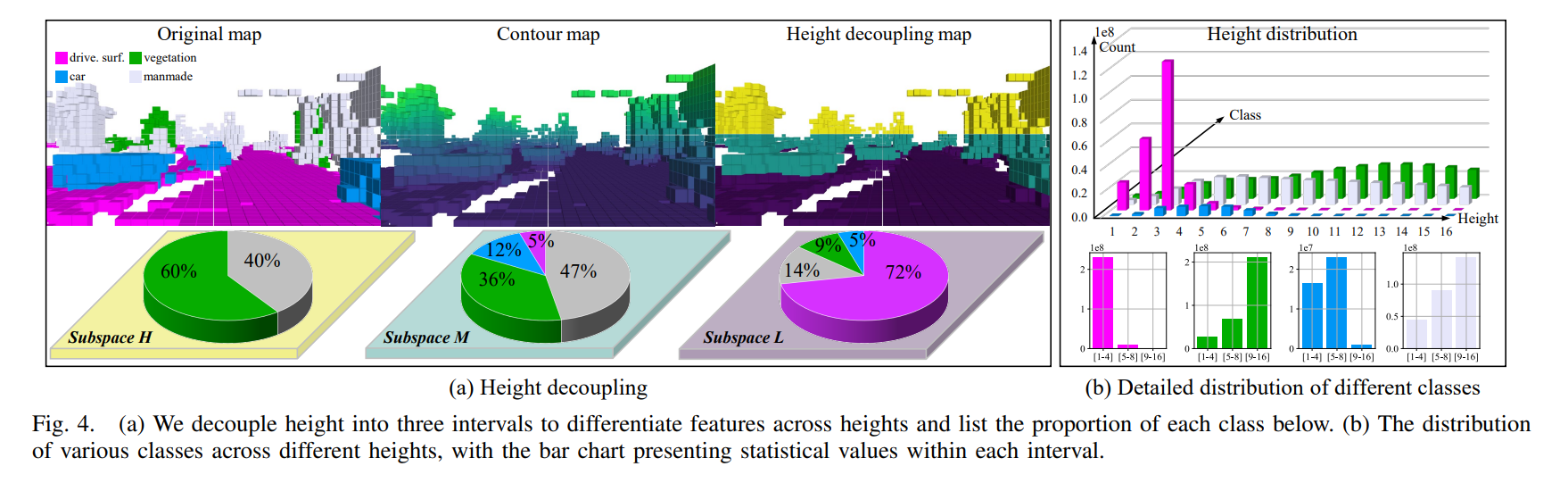
此外,我们还提出了加权平均熵,以证明高度解耦的有效性:
E=−1Nsample∑k=1Nhsksvox(∑j=1NclaqjNvoxlog2qjNvox)E=-\frac{1}{N_{sample}}\sum \limits_{k=1}^{N_h}\frac{s_k}{s_{vox}}( \sum \limits_{j=1}^{N_{cla}}\frac{q_j}{N_{vox}}\log_2\frac{q_j}{N_{vox}}) E=−Nsample1k=1∑Nhsvoxsk(j=1∑NclaNvoxqjlog2Nvoxqj)
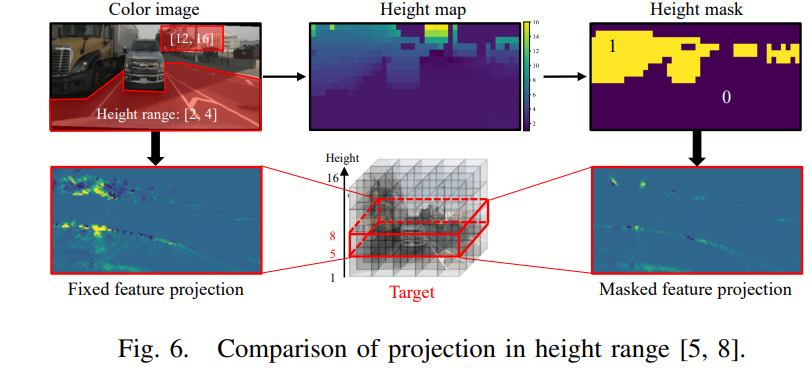
为了有效捕捉特定高度范围内的特征,我们利用高度mask剔除冗余的特征点,从而生成高度感知的特征图。并将其投影至对应高度子空间中。
- Synergistic Feature Aggregation
聚合模块的关键点是通过j两阶段注意力机制,选取并构建与Occ预测最相关的特征。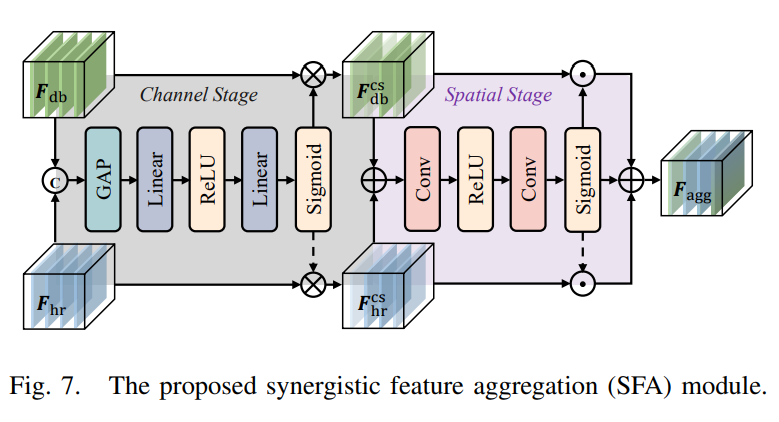
Experiment
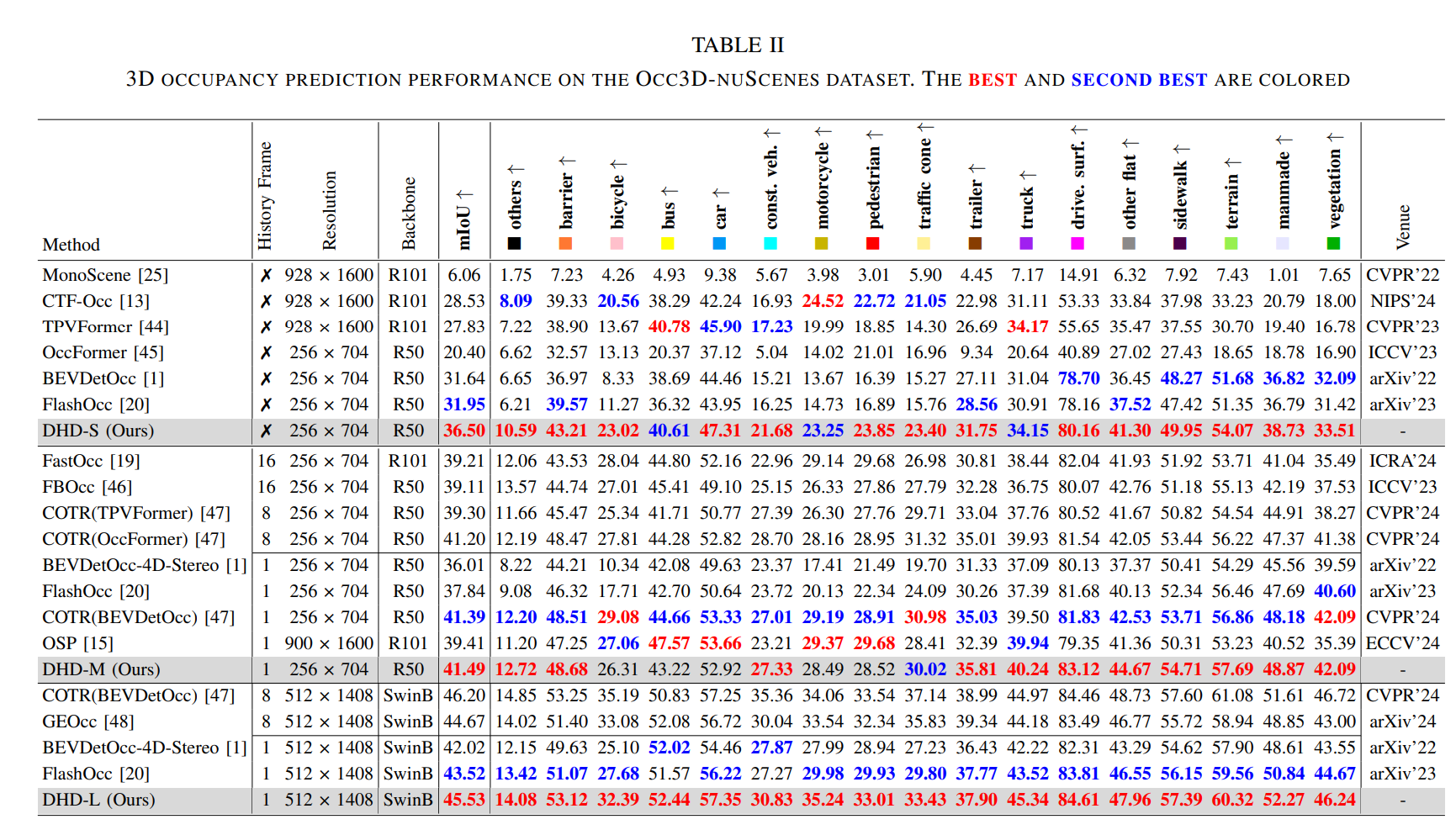
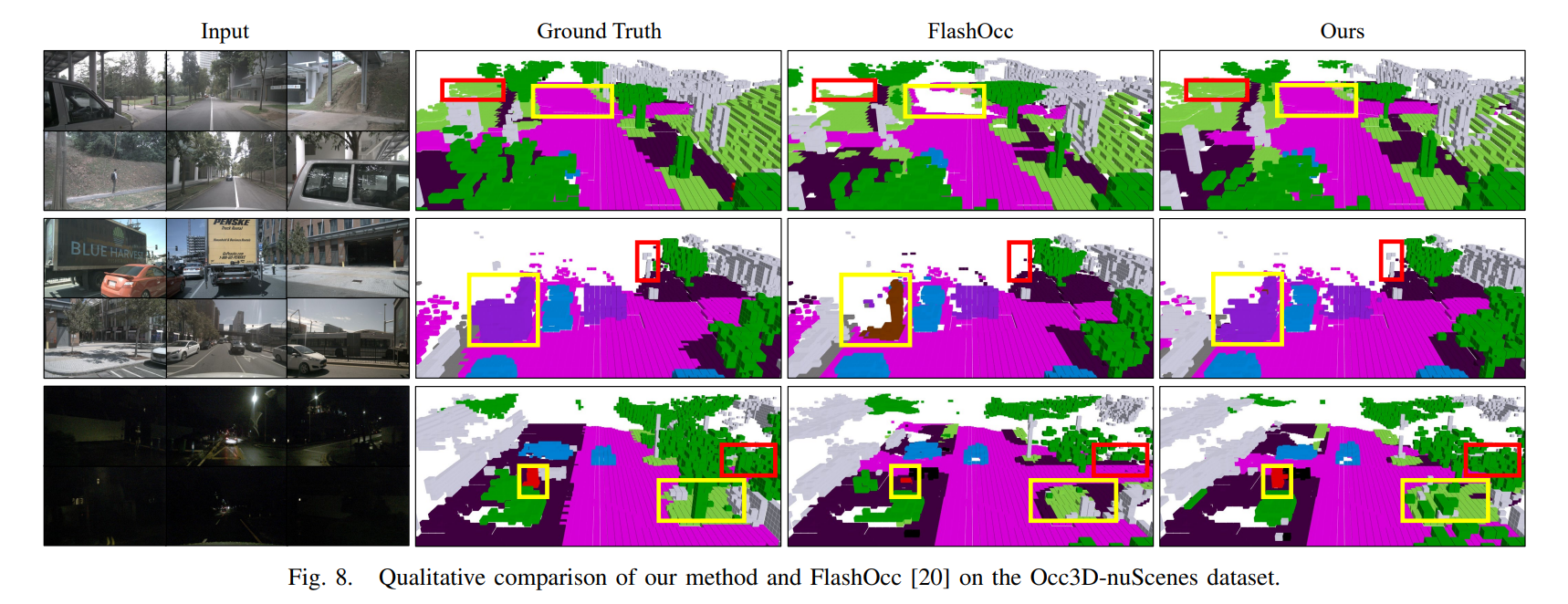

















 9814
9814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









