







 本文使用Python工具分析IT桔子死亡公司的数据,包括存活时间、地理位置、融资情况、死亡原因和主要业务,揭示公司死亡背后的模式。发现公司平均存活3.5年,北上广死亡公司最多,游戏开发和电子商务占比较高,商业模式匮乏和市场竞争是主要死亡原因。
本文使用Python工具分析IT桔子死亡公司的数据,包括存活时间、地理位置、融资情况、死亡原因和主要业务,揭示公司死亡背后的模式。发现公司平均存活3.5年,北上广死亡公司最多,游戏开发和电子商务占比较高,商业模式匮乏和市场竞争是主要死亡原因。
前言
在一次日常上网过程中,无意间发现了IT桔子死亡公司有个有趣的新经济死亡公司数据库的专栏,因此对于刚学习了数据分析相关工具的我,对此产生了极大的兴趣,想要通过分析这些死亡公司的数据来发现点有趣的东西,同时也是将其作为一个数据分析实战的案例,数据来源:IT桔子死亡公司数据库 (网络爬虫获取,具体实现请参照我的个人博客文章:python爬取IT桔子死亡公司数据库),特此声明:此数据仅用于个人数据分析学习,请勿商用,如侵犯IT桔子公司权益,请联系本人删除!

使用工具
- jupyter
- numpy
- pandas
- matplotlib
代码实现
本文所有源码均保存在我的github上:https://github.com/ShanYonggang/spider_list/tree/master/death_company
更多内容,请查看我的个人博客:大圣的专属空间
首先是进行数据的导入:
import numpy as np
import pandas as pd
read_data = pd.read_excel(r"F:\git_project\spider_list\death_company\death_company_info - 副本.xls")
df_data = pd.DataFrame(read_data)
# 计算存活天数
def cal_live_time(start_time,end_time):
import datetime
d1 = datetime.datetime.strptime(start_time,'%Y-%m-%d')
d2 = datetime.datetime.strptime(end_time,'%Y-%m-%d')
days = (d2-d1).days
return days
need_data = df_data.loc[:,['com_name','com_born','com_change_close_date','com_style','com_position','com_tags','com_fund_status_name','com_invsts','death_reason']]
# 计算所有公司的存活时间
f = lambda x:cal_live_time(x.com_born,x.com_change_close_date)
need_data['live_time'] = need_data.apply(f,axis=1)
need_data.head()解释:由于我们在初期爬取数据的时候未获取公司存活天数,因此通过创立时间及死亡时间来计算存活天数,查看数据结果如下:
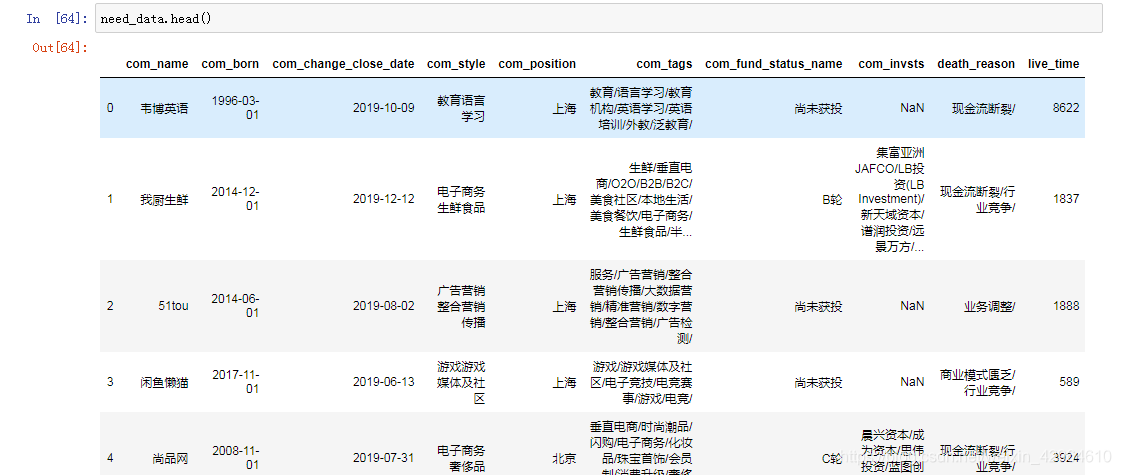
首先我们从公司存活时间这方面来进行分析
通过如下代码我们可以获取存活时间最长和最短的公司信息
# 获取生存时间最短的公司
need_data.loc[need_data['live_time'].idxmin(),:]
# 获取生存时间最长的公司
need_data.loc[need_data['live_time'].idxmax(),:]
# 平均存活时间
need_data['live_time'].mean()结果如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









