







 本文介绍了使用机器学习分析泰坦尼克号数据,通过数据预处理、特征工程、模型构建和评估,探索哪些特征影响乘客生存率。数据包括乘客性别、船舱等级、年龄等,结果显示女性和年轻乘客生存率较高。最终模型正确率为73.18%,为进一步优化提供了方向。
本文介绍了使用机器学习分析泰坦尼克号数据,通过数据预处理、特征工程、模型构建和评估,探索哪些特征影响乘客生存率。数据包括乘客性别、船舱等级、年龄等,结果显示女性和年轻乘客生存率较高。最终模型正确率为73.18%,为进一步优化提供了方向。
项目简介
项目说明:泰坦尼克号的沉没是历史上最臭名昭著的海难之一,1912年4月15日,在她的处女航中,被广泛认为的“沉没” RMS泰坦尼克号与冰山相撞后沉没。不幸的是,船上没有足够的救生艇供所有人使用,导致2224名乘客和机组人员中的1502人死亡。虽然幸存有一些运气,但似乎有些人比其他人更有可能生存。本次主要是根据提供的数据来判断什么样的人更容易生存。
数据来源:Kaggle泰坦尼克生存预测
数据说明:
| PassengerId | 乘客编号 |
| Survived | 是否生还(0、1) |
| Pclass | 船票等级(1、2、3) |
| Name | 姓名 |
| Sex | 性别(male、female) |
| Age | 年龄 |
| SibSp | 船上的兄弟姐妹、配偶数量 |
| Parch | 船上的父母、子女数量 |
| Ticket | 票号 |
| Fare | 票价 |
| Cabin | 船舱口 |
| mbarked | 登船港口 |
数据分析
这部分主要进行数据的导入、查看、缺失值的处理及数据的可视化显示,目前先是针对训练数据进行分析,后续需要对训练数据和测试数据进行统计处理,保证一致性。
导入数据
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
# 导入数据
train_data = pd.read_csv("titanic_train.csv")
test_data = pd.read_csv("titanic_test.csv")查看数据
查看前五行
# 查看数据
train_data.head()结果如下:

查看整体统计
# 整体统计
train_data.describe()结果如下:
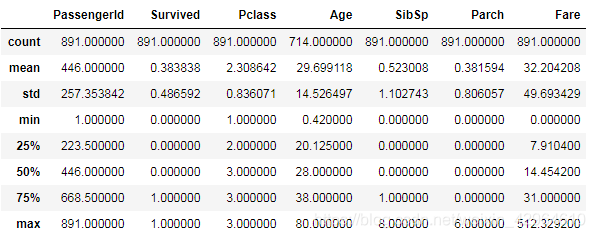
可以看出,训练集中有891条数据,整体的生存率为38.4%,平均年龄为29.699,平均票价为32.2
查看数据缺失值
# 查看数据
train_data.info()
# 缺失值数量查看
train_data.isnull().sum()结果如下:
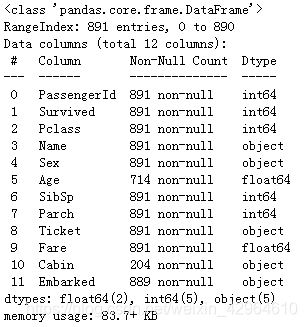
可以看到,船舱口数据缺失较大、登船港口有两条缺失、乘员年龄数据也有缺失,后续需要对缺失值进行填充。
缺失值处理
由上面可以数据有缺失,需要对其进行处理,主要是依据填充的形式,对于Embarked使用众数进行填充,对于年龄使用平均值进行填充(当然也可以根据其他特征使用模型拟合进行填充,本次为了简便使用了年龄均值的方式),对于Carbin,博主使用的是去除该特征,代码如下:
# 数据缺失值处理
# 年龄使用了平均值来填充
train_dat 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









