







这是一篇ICRA2020顶会的一篇双目视差估计的文章;文章内容主要是对dispnet的改进;并对学习率以及尺度权重等都做了很多实验。
文章代码:https://github.com/HKBU-HPML/FADNet
摘要
深层神经网络(DNN)在计算机视觉领域取得了巨大的成功。 DNN往往会解决视差估计问题,与传统的基于传统特征的方法相比,DNN在立体匹配中获得了更好的预测精度。 但是,一方面,设计的DNN需要大量内存和计算资源才能准确预测差异,尤其是对于那些基于3D卷积的网络而言,这使得在实时应用中部署变得困难。 另一方面,现有的计算效率高的网络在大规模数据集中缺乏表达能力,因此它们无法在许多情况下做出准确的预测。
为此,我们提出了一种高效,准确的用于视差估计的深度网络,称为FADNet,具有三个主要特征:
1. 利用带有堆叠块的基于2D的高效相关层来保持快速计算;
2. 结合残差结构,使更深层次的模型更易于学习;
3. 它包含多尺度预测,以便利用多尺度体重计划训练技术来提高准确性。
我们进行实验以证明FADNet在两个流行的数据集Scene Flow和KITTI 2015上的有效性。实验结果表明FADNet达到了最先进的预测精度,并且比现有3D模型的运行速度快了一个数量级。
一、INTRODUCTION
为此,我们提出了FADNet,它是一个基于EDConv2D架构的快速,准确的视差估计网络。 FADNet可以保持较高的准确性,同时保持快速的推理速度。 如图所示。

如图1所示,我们的FADNet可以轻松获得与最新的PSMNet相当的性能[6],而它的运行速度比PSMNet快20倍左右,而GPU内存却要少10倍。
在FADNet中,我们首先利用快速计算来利用多个基于2D的堆叠卷积层,然后结合最新的残差体系结构以提高学习能力,最后为FADNet引入多尺度输出,以便 可以利用多尺度权重调度来提高训练速度。 与现有工作相比,这些功能使FADNet可以高效,高精度地预测差异。 我们的贡献总结如下:
我们提出了一种精确而高效的DNN架构,用于视差估计,称为FADNet,该架构可实现与CVM-Conv3D模型相当的预测精度,并且其运行速度比基于3D的模型快一个数量级。
- 我们在训练过程中为FADNet开发了具有多尺度权重计划的多轮训练计划,该计划提高了训练速度,但仍保持了模型准确性。
- 我们在Scene Flow数据集上实现了最新的准确性,其视差预测速度分别比PSMNet [6]和GANet [7]快20倍和45倍。
三、MODEL DESIGN AND IMPLEMENTATION
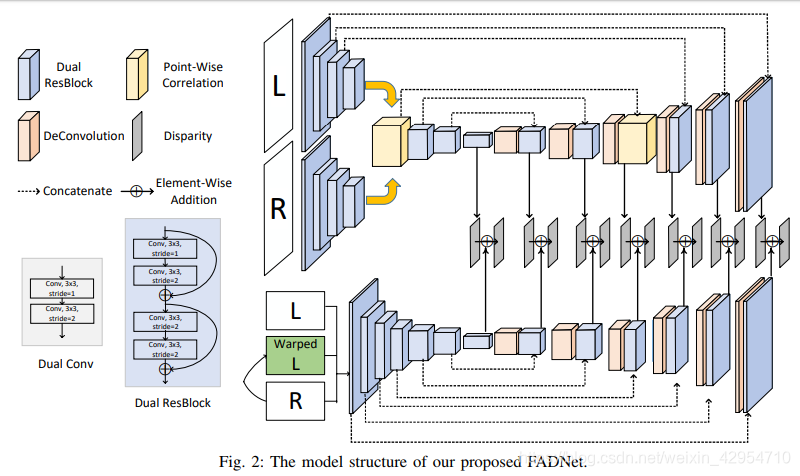
我们提出的FADNet将DispNetC [5]的结构作为骨干网,但对其进行了广泛的改革,以兼顾准确性和推理速度,这是现有研究所缺乏的。 我们首先通过引入两个新模块(残差块(Residual Block)和逐点关联(Point-wise Correlation))来改变分支深度和层类型的结构。 然后,我们利用多尺度残差学习策略来训练refine网络。 最后,使用loss权重训练计划表以从粗到精的方式训练网络。
A. Residual Block and Point-wise Correlation
[5]中研究的DispNetC和DispNetS基本上使用编码器-解码器结构,该结构具有五个特征提取下采样层和五个特征反卷积层。在进行特征提取和下采样时,DispNetC和DispNetS首先采用步幅为1的卷积层,然后采用步幅为2的卷积层,以便它们始终将特征图的大小缩小一半。 我们将尺寸减小的两层卷积称为Dual-Conv,如图2的左下角所示。DispNetC配备了Dual-Conv模块和相关层,最终实现了 如[5]中所述,在“Scene Flow”数据集上端点误差(EPE)为 1.68。
最初在[15]中得出的用于图像分类任务的残差块被广泛用于学习鲁棒特征和训练非常深的网络。 训练非常深的网络时,残留块可以很好地解决梯度消失问题。 因此,我们用残差块替换Dual-Conv模块中的卷积层,以构造一个称为Dual-ResBlock的新模块,如图2的左下角所示。使用Dual-ResBlock,我们可以使 无需训练就可以使网络更深入,因为残差块使我们可以训练非常深的模型。 因此,我们进一步将特征提取和下采样层的数量从五层增加到了七层。 最后,DispNetC和DispNetS正在发展成为具有更好学习能力的两个新网络,分别称为RB-NetC和RB-NetS,如图2所示。
DispNetC最重要的贡献之一就是相关层,该层旨在查找左右图像之间的对应关系。 给定两个以w,h和c为宽度,高度和通道数的多通道特征图f1,f2,相关层使用等式(1)计算它们的成本量。
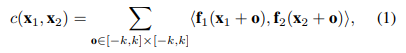
其中k是成本匹配的内核大小,x1和x2分别是f1和f2中两个patch的中心。
计算所有patch组合涉及 c×K^ 2×w ^ 2×h^2乘法,并产生w×h的成本匹配图。
给定最大搜索范围D,我们固定x1并将x2在x轴方向上从-D移到D,步幅为2。
因此,最终的输出成本量大小将为w×h×D。
但是,相关运算在每个像素均对逐点卷积结果做出同等贡献,这可能会失去学习更复杂的匹配模式的能力。 在这里,我们提出了由两个模块组成的逐点相关。 第一个模块是经典卷积层,内核大小为3×3,步幅为1。第二个模块是元素式乘法,由等式定义(2)。
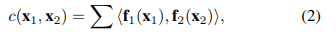
这里我们从等式(1)中删除了patch 卷积方式。
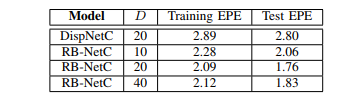
由于在评估的数据集中最大有效视差为192,因此原始图像分辨率的最大搜索范围不超过192。请记住,相关层位于第三个Dual-ResBlock之后,其输出要素分辨率为1 / 8。 因此,正确的搜索范围值不应小于192/8 = 16。 我们将值设置为稍大的20。我们还测试了其他一些值,例如10和40,它们不会超过在网络中使用20的版本。 原因是,将搜索范围值设置得太小或太小可能会导致拟合不足或拟合过度。
下表列出了通过应用建议的Dual-ResBlock和逐点相关带来的精度提高。
我们使用相同的数据集以及训练方案来训练他们。 可以看出,RB-NetC的EPE低得多,胜过DispNetC,这表明残差结构的有效性。 我们还注意到,设置相关层的适当搜索范围值有助于进一步提高模型的准确性。
B.多尺度残差学习
改进直接堆叠DispNetC和DispNetS子网来进行视差细化过程[13](也就是dispnet的解码部分),我们应用了[25]首先提出的多尺度残差学习。 基本思想是第二个精炼网络学习视差残差并将其累加到第一个网络生成的初始结果中,而不是直接预测整个视差图。 这样,第二个网络只需要专注于学习高度非线性的残差,这对于避免梯度消失是有效的。 我们最终的FADNet是通过将RB-NetC和RB-NetS与多尺度残差学习进行堆叠而形成的,如图2所示。
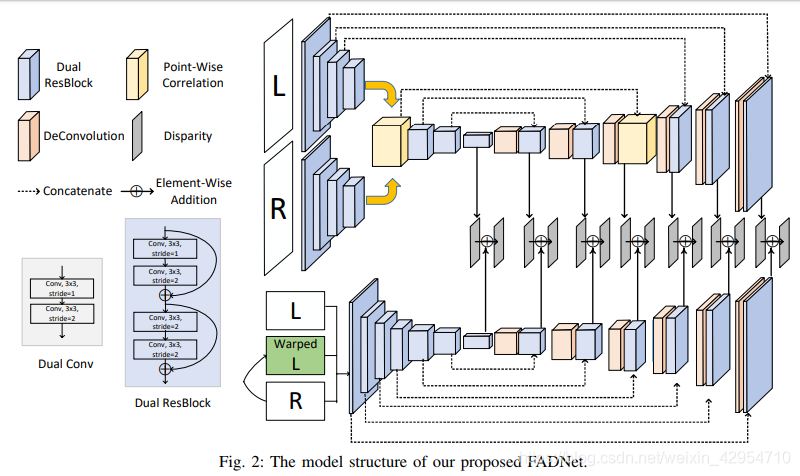
如图2所示,上层RB-NetC将左右图像作为输入,并生成总共7个比例的视差图,用cs表示,其中s为0到6。下层RB-NetS利用 左图像,右图像和warp的左图像的输入以预测残差。 然后,从RBNetS生成的残差(用rs表示)将被RBNetC累积到预测结果中,以生成具有多个比例(s = 0、1,…,6)的最终视差图。 因此,由FADNet预测的最终视差图可以用:
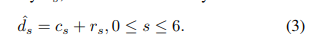
C、loss的选择
给定一对立体校正RGB图像,我们的FADNet将其作为输入并生成七个不同比例的视差图。 假设输入图像大小为H×W。输出视差图的七个比例尺的尺寸为H×W,1/2H×1/2W,1/4H×1 4W,1/8H×1/8W,1/16H×1/16W ,1/32H×1 32W和1/64H×1/64W。 为了端到端地训练FADNet,我们使用预测的视差图和ground truth之间的像素级smooth L1loss。
最后是不同尺度的权重设置
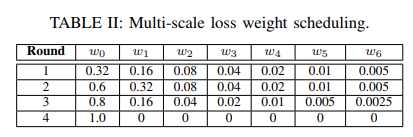
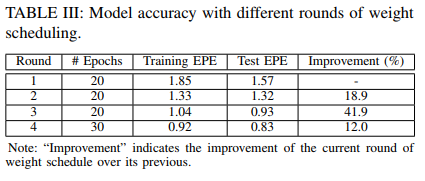
上面是不同尺度的权重策略,表三中的意思是:表二的第一个权重策略训练20个epoch的结果在round 1;继续以表二的第二个权重策略训练20个epoch的结果,最后第4个权重策略需要训练30个epoch;sceneflow数据集总共训练了90个epoch。(这训练的也太多了;看结果还没有过拟合)。
本文主体已经翻译完了,看结果是一个不错的网络,过两天应该会把它跑出来看看。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









