






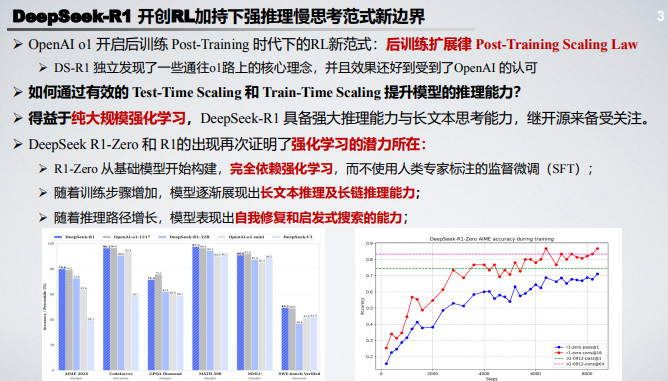
在人工智能领域,强化学习 正在大语言模型推理领域掀起一场革命,而 DeepSeek-R1 系列模型正是这场变革的先锋。
北京大学对齐小组发布的这份重磅报告,探索 DeepSeek-R1 与 Kimi 1.5 等类强推理模型的独特魅力与技术实现。
这篇报告我已经下载整理好的,想看完整版的小伙伴可以在评论区回复“想要”,我会发给你!

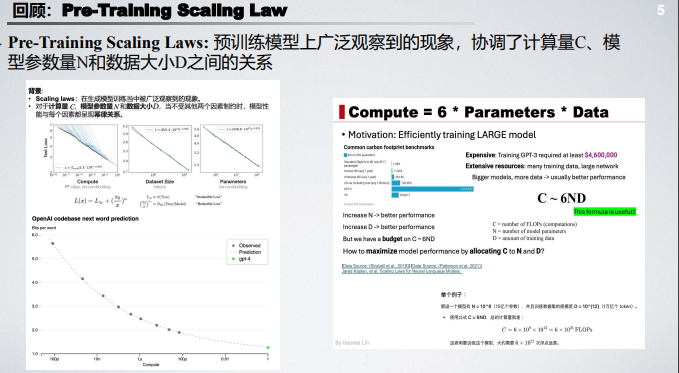
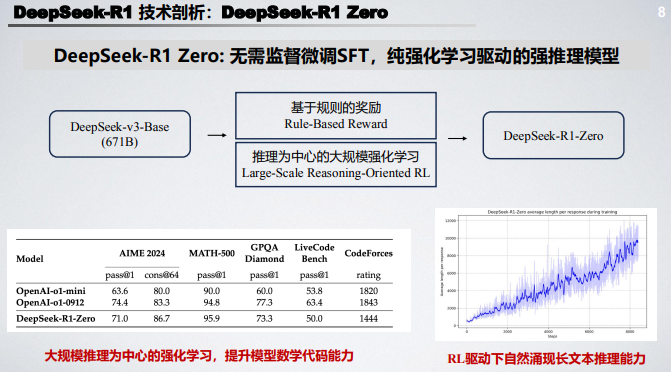
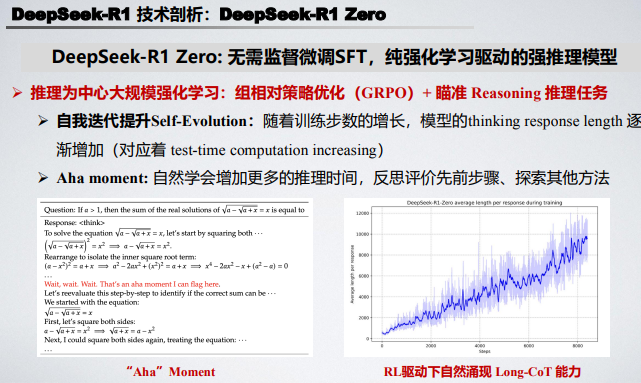
这份报告由北京大学 2022 级 “通班” 的陈博远倾力打造,系统梳理了 DeepSeek-R1、Kimi 1.5 等强推理模型的技术脉络。报告聚焦于这些模型在研发历程中的关键节点,深入剖析了 强化学习(RL) 如何赋能大语言模型实现推理能力的飞跃。








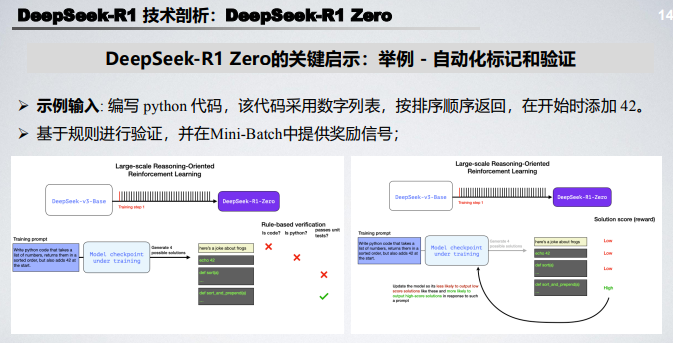

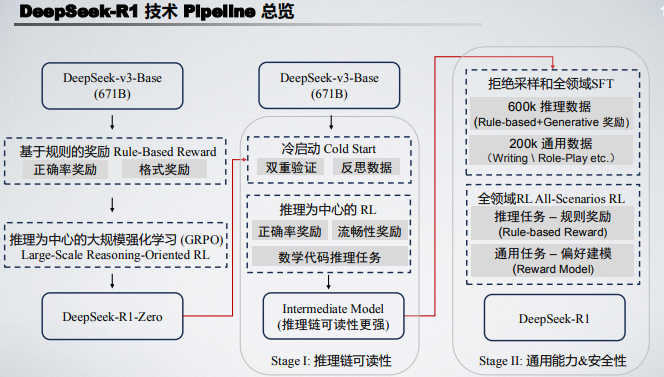



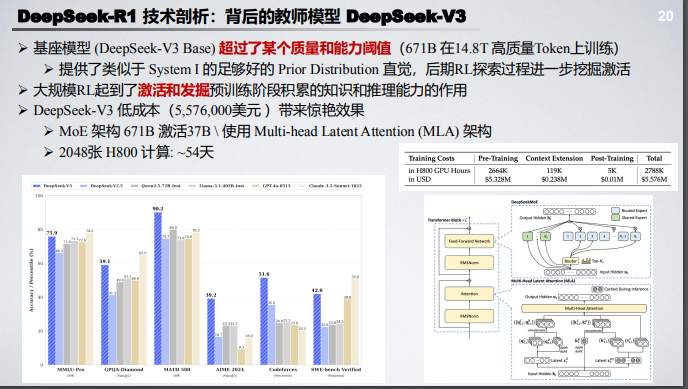
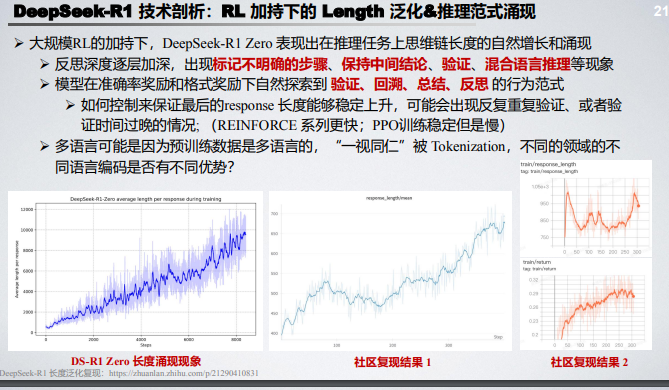
























 150
150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











